 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Estimation on Graphs with Structure Informed Stochastic Partial Differential Equations
Jun 07, 2025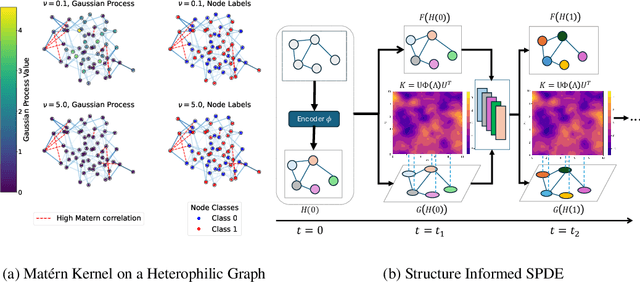
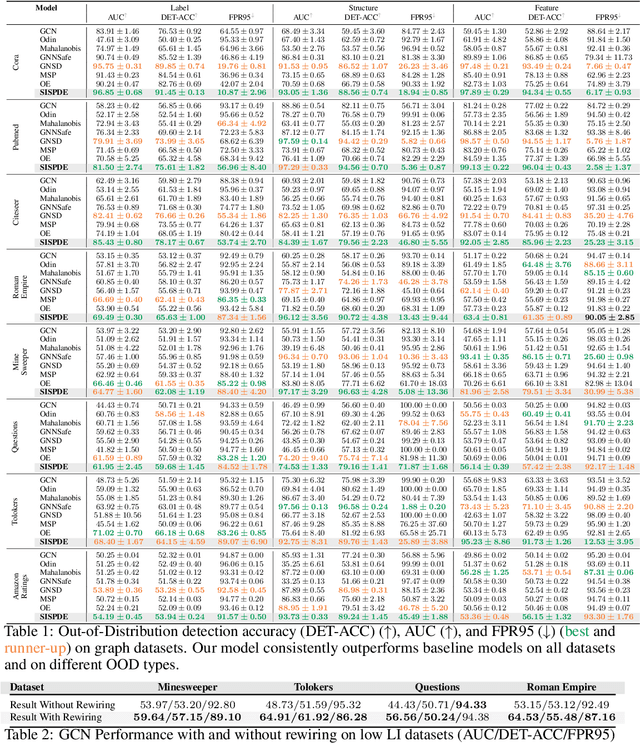
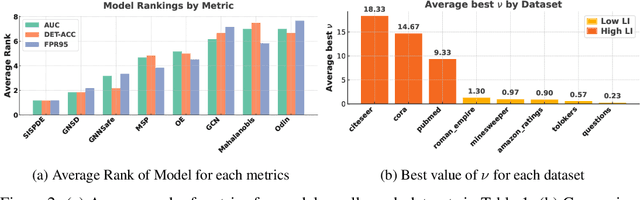
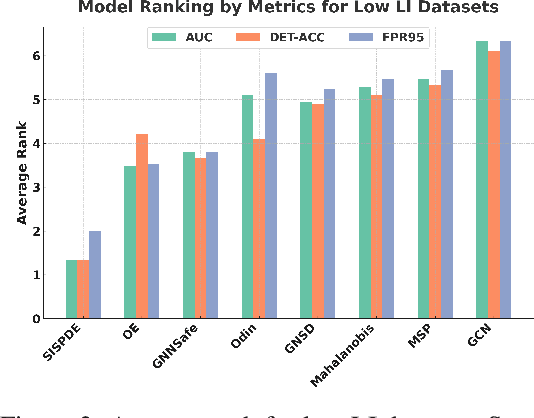
Graph Neural Networks have achieved impressive results across diverse network modeling tasks, but accurately estimating uncertainty on graphs remains difficult, especially under distributional shifts. Unlike traditional uncertainty estimation, graph-based uncertainty must account for randomness arising from both the graph's structure and its label distribution, which adds complexity. In this paper, making an analogy between the evolution of a stochastic partial differential equation (SPDE) driven by Matern Gaussian Process and message passing using GNN layers, we present a principled way to design a novel message passing scheme that incorporates spatial-temporal noises motivated by the Gaussian Process approach to SPDE. Our method simultaneously captures uncertainty across space and time and allows explicit control over the covariance kernel smoothness, thereby enhancing uncertainty estimates on graphs with both low and high label informativeness. Our extensive experiments on Out-of-Distribution (OOD) detection on graph datasets with varying label informativeness demonstrate the soundness and superiority of our model to existing approaches.
Understanding the Design Principles of Link Prediction in Directed Settings
Feb 20, 2025



Link prediction is a widely studied task in Graph Representation Learning (GRL) for modeling relational data. The early theories in GRL were based on the assumption of a symmetric adjacency matrix, reflecting an undirected setting. As a result, much of the following state-of-the-art research has continued to operate under this symmetry assumption, even though real-world data often involve crucial information conveyed through the direction of relationships. This oversight limits the ability of these models to fully capture the complexity of directed interactions. In this paper, we focus on the challenge of directed link prediction by evaluating key heuristics that have been successful in undirected settings. We propose simple but effective adaptations of these heuristics to the directed link prediction task and demonstrate that these modifications produce competitive performance compared to the leading Graph Neural Networks (GNNs) originally designed for undirected graphs. Through an extensive set of experiments, we derive insights that inform the development of a novel framework for directed link prediction, which not only surpasses baseline methods but also outperforms state-of-the-art GNNs on multiple benchmarks.
Scaling Laws for Discriminative Classification in Large Language Models
May 24, 2024



Modern large language models (LLMs) represent a paradigm shift in what can plausibly be expected of machine learning models. The fact that LLMs can effectively generate sensible answers to a diverse range of queries suggests that they would be useful in customer support applications. While powerful, LLMs have been observed to be prone to hallucination which unfortunately makes their near term use in customer support applications challenging. To address this issue we present a system that allows us to use an LLM to augment our customer support advocates by re-framing the language modeling task as a discriminative classification task. In this framing, we seek to present the top-K best template responses for a customer support advocate to use when responding to a customer. We present the result of both offline and online experiments where we observed offline gains and statistically significant online lifts for our experimental system. Along the way, we present observed scaling curves for validation loss and top-K accuracy, resulted from model parameter ablation studies. We close by discussing the space of trade-offs with respect to model size, latency, and accuracy as well as and suggesting future applications to explore.
QDC: Quantum Diffusion Convolution Kernels on Graphs
Jul 20, 2023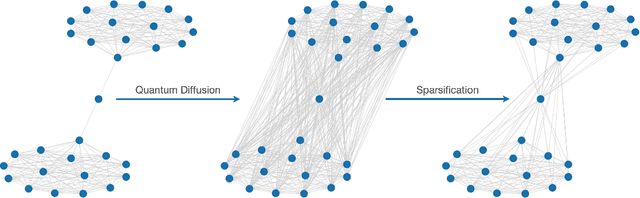
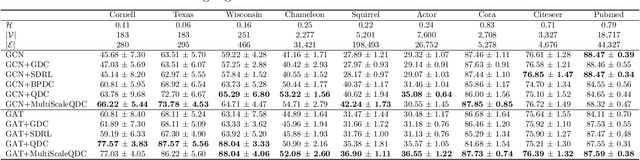
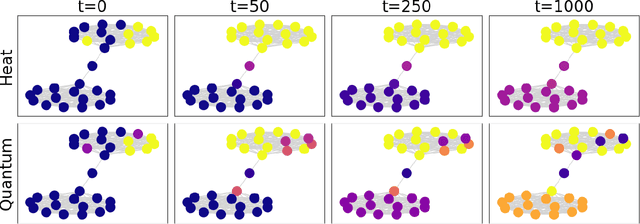

Graph convolutional neural networks (GCNs) operate by aggregating messages over local neighborhoods given the prediction task under interest. Many GCNs can be understood as a form of generalized diffusion of input features on the graph, and significant work has been dedicated to improving predictive accuracy by altering the ways of message passing. In this work, we propose a new convolution kernel that effectively rewires the graph according to the occupation correlations of the vertices by trading on the generalized diffusion paradigm for the propagation of a quantum particle over the graph. We term this new convolution kernel the Quantum Diffusion Convolution (QDC) operator. In addition, we introduce a multiscale variant that combines messages from the QDC operator and the traditional combinatorial Laplacian. To understand our method, we explore the spectral dependence of homophily and the importance of quantum dynamics in the construction of a bandpass filter. Through these studies, as well as experiments on a range of datasets, we observe that QDC improves predictive performance on the widely used benchmark datasets when compared to similar methods.
TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
Feb 27, 2023



Recommendation systems are a core feature of social media companies with their uses including recommending organic and promoted contents. Many modern recommendation systems are split into multiple stages - candidate generation and heavy ranking - to balance computational cost against recommendation quality. We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC. We show that a system that combines a real-time light ranker with sourcing strategies capable of capturing additional information provides validated gains. We present two strategies. The first strategy uses a notion of similarity in the interaction graph, while the second strategy caches previous scores from the ranking stage. The graph based strategy achieves a 4.08% revenue gain and the rankscore based strategy achieves a 1.38% gain. These two strategies have biases that complement both the light ranker and one another. Finally, we describe a set of metrics that we believe are valuable as a means of understanding the complex product trade offs inherent in industrial candidate generation systems.
Graph Neural Networks for Link Prediction with Subgraph Sketching
Oct 03, 2022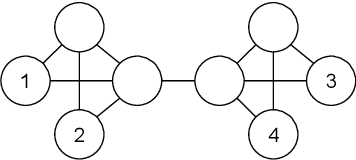
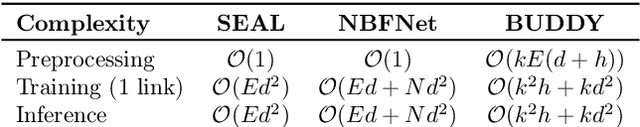
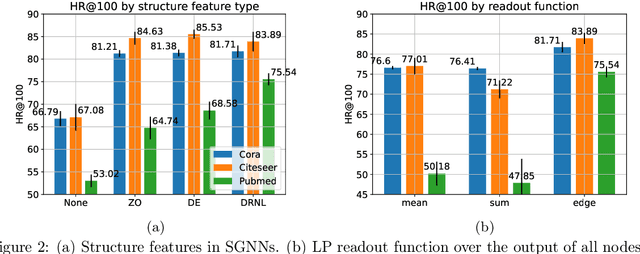
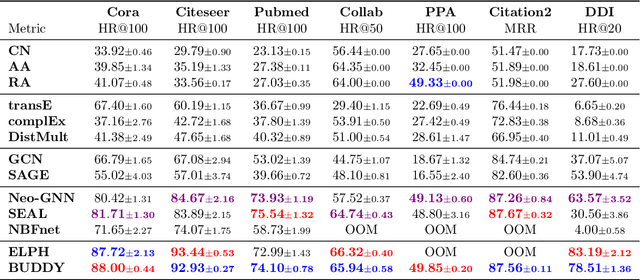
Many Graph Neural Networks (GNNs) perform poorly compared to simple heuristics on Link Prediction (LP) tasks. This is due to limitations in expressive power such as the inability to count triangles (the backbone of most LP heuristics) and because they can not distinguish automorphic nodes (those having identical structural roles). Both expressiveness issues can be alleviated by learning link (rather than node) representations and incorporating structural features such as triangle counts. Since explicit link representations are often prohibitively expensive, recent works resorted to subgraph-based methods, which have achieved state-of-the-art performance for LP, but suffer from poor efficiency due to high levels of redundancy between subgraphs. We analyze the components of subgraph GNN (SGNN) methods for link prediction. Based on our analysis, we propose a novel full-graph GNN called ELPH (Efficient Link Prediction with Hashing) that passes subgraph sketches as messages to approximate the key components of SGNNs without explicit subgraph construction. ELPH is provably more expressive than Message Passing GNNs (MPNNs). It outperforms existing SGNN models on many standard LP benchmarks while being orders of magnitude faster. However, it shares the common GNN limitation that it is only efficient when the dataset fits in GPU memory. Accordingly, we develop a highly scalable model, called BUDDY, which uses feature precomputation to circumvent this limitation without sacrificing predictive performance. Our experiments show that BUDDY also outperforms SGNNs on standard LP benchmarks while being highly scalable and faster than ELPH.
Graph Neural Networks as Gradient Flows
Jun 22, 2022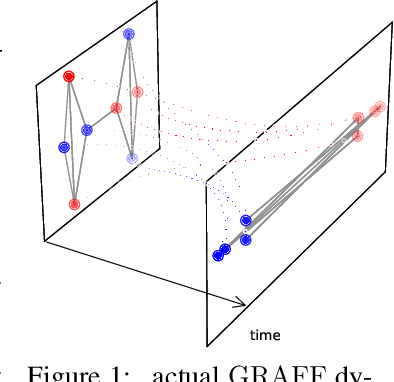
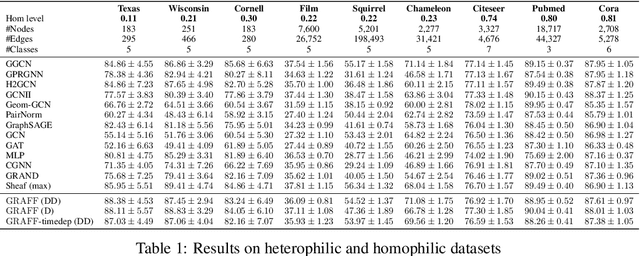
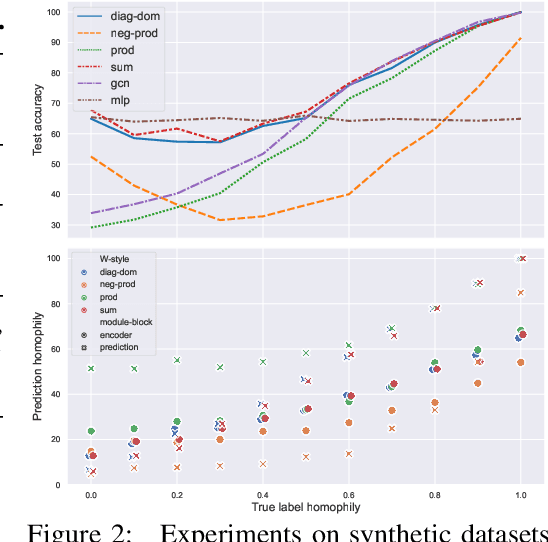
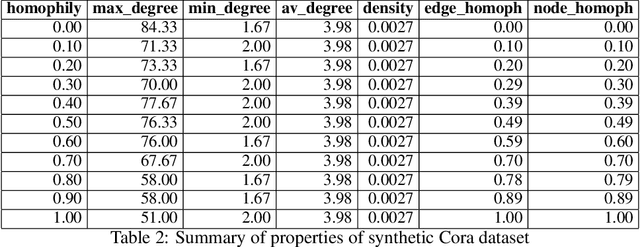
Dynamical systems minimizing an energy are ubiquitous in geometry and physics. We propose a gradient flow framework for GNNs where the equations follow the direction of steepest descent of a learnable energy. This approach allows to explain the GNN evolution from a multi-particle perspective as learning attractive and repulsive forces in feature space via the positive and negative eigenvalues of a symmetric "channel-mixing" matrix. We perform spectral analysis of the solutions and conclude that gradient flow graph convolutional models can induce a dynamics dominated by the graph high frequencies which is desirable for heterophilic datasets. We also describe structural constraints on common GNN architectures allowing to interpret them as gradient flows. We perform thorough ablation studies corroborating our theoretical analysis and show competitive performance of simple and lightweight models on real-world homophilic and heterophilic datasets.
kNN-Embed: Locally Smoothed Embedding Mixtures For Multi-interest Candidate Retrieval
May 13, 2022

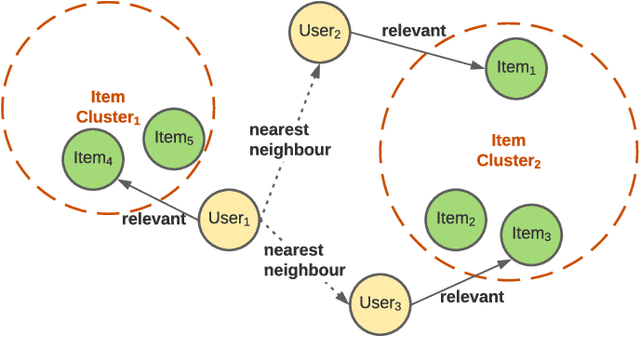
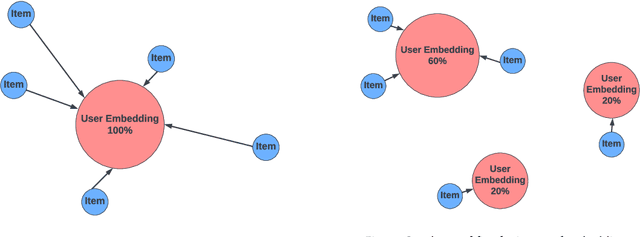
Candidate generation is the first stage in recommendation systems, where a light-weight system is used to retrieve potentially relevant items for an input user. These candidate items are then ranked and pruned in later stages of recommender systems using a more complex ranking model. Since candidate generation is the top of the recommendation funnel, it is important to retrieve a high-recall candidate set to feed into downstream ranking models. A common approach for candidate generation is to leverage approximate nearest neighbor (ANN) search from a single dense query embedding; however, this approach this can yield a low-diversity result set with many near duplicates. As users often have multiple interests, candidate retrieval should ideally return a diverse set of candidates reflective of the user's multiple interests. To this end, we introduce kNN-Embed, a general approach to improving diversity in dense ANN-based retrieval. kNN-Embed represents each user as a smoothed mixture over learned item clusters that represent distinct `interests' of the user. By querying each of a user's mixture component in proportion to their mixture weights, we retrieve a high-diversity set of candidates reflecting elements from each of a user's interests. We experimentally compare kNN-Embed to standard ANN candidate retrieval, and show significant improvements in overall recall and improved diversity across three datasets. Accompanying this work, we open source a large Twitter follow-graph dataset, to spur further research in graph-mining and representation learning for recommender systems.