 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Gating for Deep Multi-Rate Learning on Graphs
Oct 02, 2022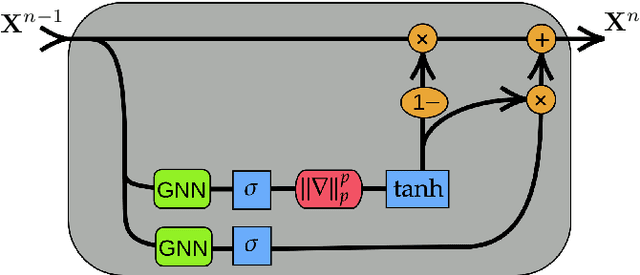
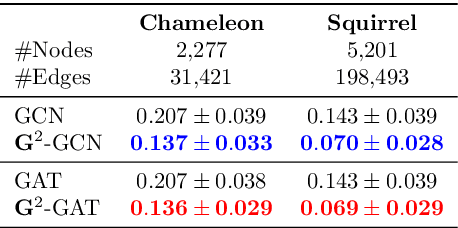
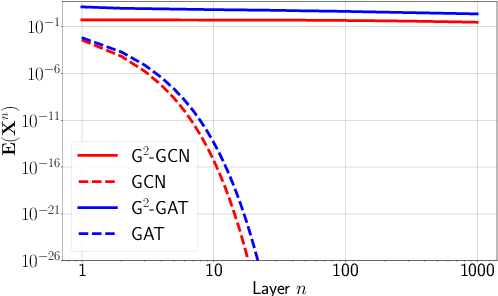

We present Gradient Gating (G$^2$), a novel framework for improving the performance of Graph Neural Networks (GNNs). Our framework is based on gating the output of GNN layers with a mechanism for multi-rate flow of message passing information across nodes of the underlying graph. Local gradients are harnessed to further modulate message passing updates. Our framework flexibly allows one to use any basic GNN layer as a wrapper around which the multi-rate gradient gating mechanism is built. We rigorously prove that G$^2$ alleviates the oversmoothing problem and allows the design of deep GNNs. Empirical results are presented to demonstrate that the proposed framework achieves state-of-the-art performance on a variety of graph learning tasks, including on large-scale heterophilic graphs.
Graph Neural Networks as Gradient Flows
Jun 22, 2022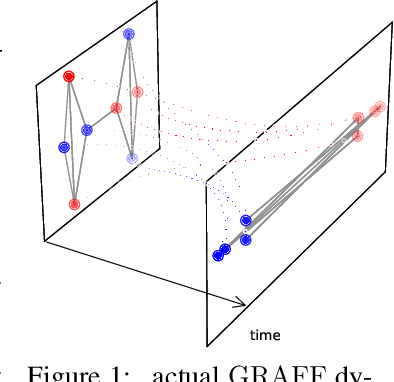
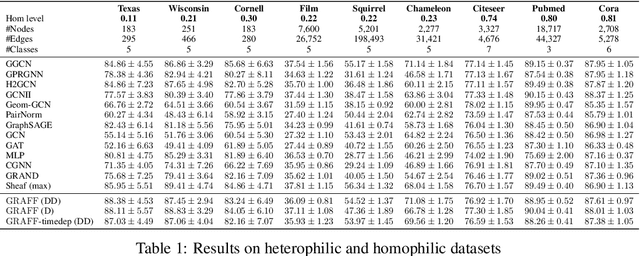
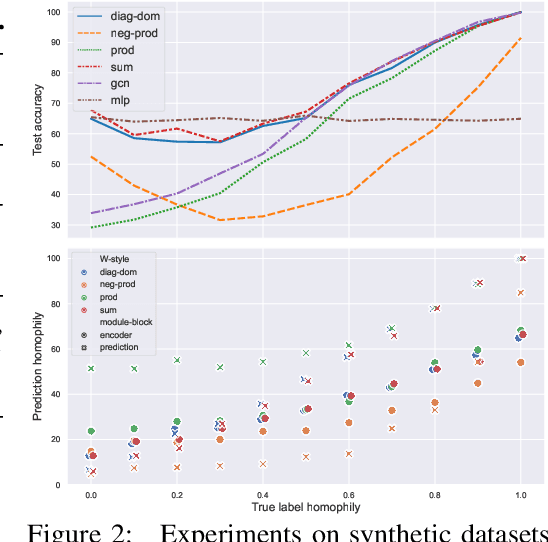
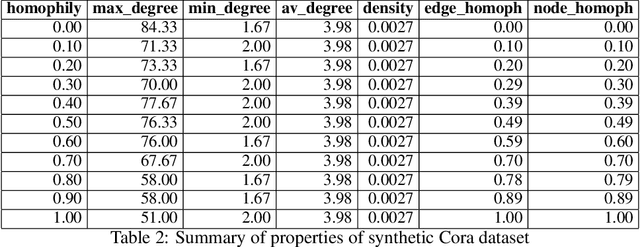
Dynamical systems minimizing an energy are ubiquitous in geometry and physics. We propose a gradient flow framework for GNNs where the equations follow the direction of steepest descent of a learnable energy. This approach allows to explain the GNN evolution from a multi-particle perspective as learning attractive and repulsive forces in feature space via the positive and negative eigenvalues of a symmetric "channel-mixing" matrix. We perform spectral analysis of the solutions and conclude that gradient flow graph convolutional models can induce a dynamics dominated by the graph high frequencies which is desirable for heterophilic datasets. We also describe structural constraints on common GNN architectures allowing to interpret them as gradient flows. We perform thorough ablation studies corroborating our theoretical analysis and show competitive performance of simple and lightweight models on real-world homophilic and heterophilic datasets.
Graph-Coupled Oscillator Networks
Feb 04, 2022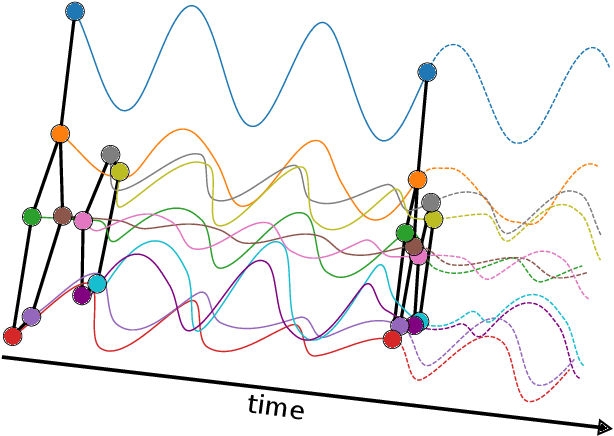

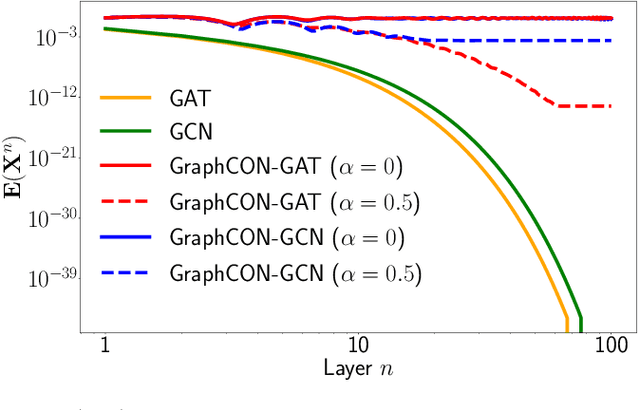
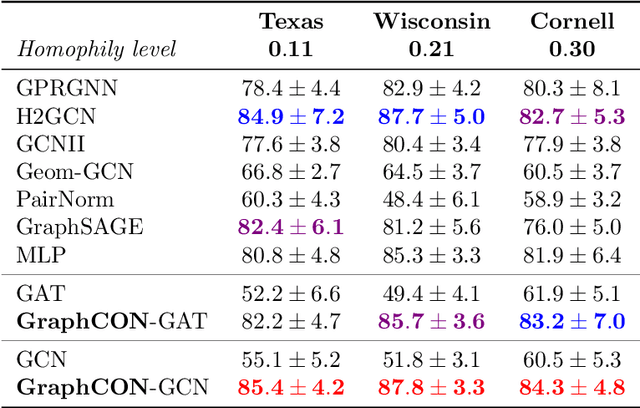
We propose Graph-Coupled Oscillator Networks (GraphCON), a novel framework for deep learning on graphs. It is based on discretizations of a second-order system of ordinary differential equations (ODEs), which model a network of nonlinear forced and damped oscillators, coupled via the adjacency structure of the underlying graph. The flexibility of our framework permits any basic GNN layer (e.g. convolutional or attentional) as the coupling function, from which a multi-layer deep neural network is built up via the dynamics of the proposed ODEs. We relate the oversmoothing problem, commonly encountered in GNNs, to the stability of steady states of the underlying ODE and show that zero-Dirichlet energy steady states are not stable for our proposed ODEs. This demonstrates that the proposed framework mitigates the oversmoothing problem. Finally, we show that our approach offers competitive performance with respect to the state-of-the-art on a variety of graph-based learning tasks.
Tuning Word2vec for Large Scale Recommendation Systems
Sep 24, 2020
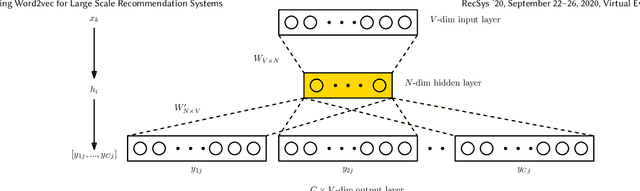
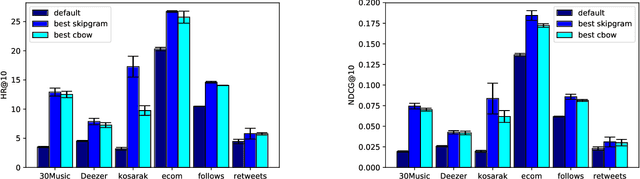

Word2vec is a powerful machine learning tool that emerged from Natural Lan-guage Processing (NLP) and is now applied in multiple domains, including recom-mender systems, forecasting, and network analysis. As Word2vec is often used offthe shelf, we address the question of whether the default hyperparameters are suit-able for recommender systems. The answer is emphatically no. In this paper, wefirst elucidate the importance of hyperparameter optimization and show that un-constrained optimization yields an average 221% improvement in hit rate over thedefault parameters. However, unconstrained optimization leads to hyperparametersettings that are very expensive and not feasible for large scale recommendationtasks. To this end, we demonstrate 138% average improvement in hit rate with aruntime budget-constrained hyperparameter optimization. Furthermore, to makehyperparameter optimization applicable for large scale recommendation problemswhere the target dataset is too large to search over, we investigate generalizinghyperparameters settings from samples. We show that applying constrained hy-perparameter optimization using only a 10% sample of the data still yields a 91%average improvement in hit rate over the default parameters when applied to thefull datasets. Finally, we apply hyperparameters learned using our method of con-strained optimization on a sample to the Who To Follow recommendation serviceat Twitter and are able to increase follow rates by 15%.
* 11 pages, 4 figures, Fourteenth ACM Conference on Recommender Systems