 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Networks for Link Prediction with Subgraph Sketching
Oct 03, 2022
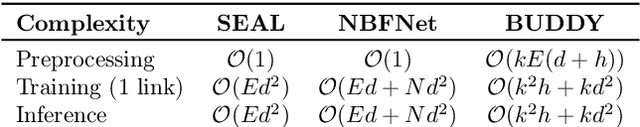
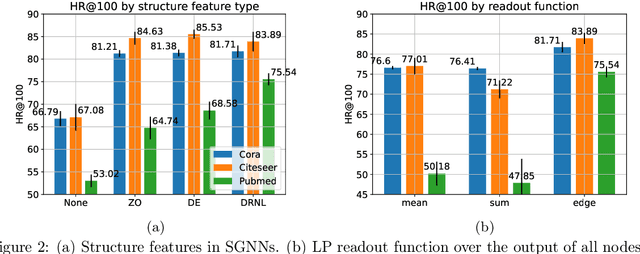
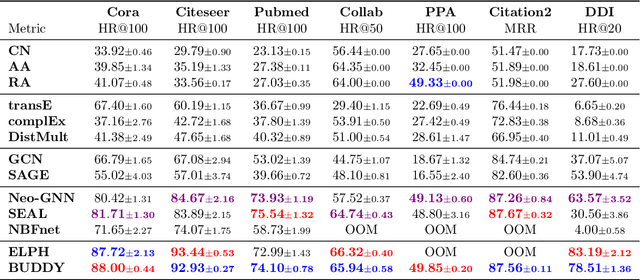
Many Graph Neural Networks (GNNs) perform poorly compared to simple heuristics on Link Prediction (LP) tasks. This is due to limitations in expressive power such as the inability to count triangles (the backbone of most LP heuristics) and because they can not distinguish automorphic nodes (those having identical structural roles). Both expressiveness issues can be alleviated by learning link (rather than node) representations and incorporating structural features such as triangle counts. Since explicit link representations are often prohibitively expensive, recent works resorted to subgraph-based methods, which have achieved state-of-the-art performance for LP, but suffer from poor efficiency due to high levels of redundancy between subgraphs. We analyze the components of subgraph GNN (SGNN) methods for link prediction. Based on our analysis, we propose a novel full-graph GNN called ELPH (Efficient Link Prediction with Hashing) that passes subgraph sketches as messages to approximate the key components of SGNNs without explicit subgraph construction. ELPH is provably more expressive than Message Passing GNNs (MPNNs). It outperforms existing SGNN models on many standard LP benchmarks while being orders of magnitude faster. However, it shares the common GNN limitation that it is only efficient when the dataset fits in GPU memory. Accordingly, we develop a highly scalable model, called BUDDY, which uses feature precomputation to circumvent this limitation without sacrificing predictive performance. Our experiments show that BUDDY also outperforms SGNNs on standard LP benchmarks while being highly scalable and faster than ELPH.
Towards more patient friendly clinical notes through language models and ontologies
Dec 23, 2021



Clinical notes are an efficient way to record patient information but are notoriously hard to decipher for non-experts. Automatically simplifying medical text can empower patients with valuable information about their health, while saving clinicians time. We present a novel approach to automated simplification of medical text based on word frequencies and language modelling, grounded on medical ontologies enriched with layman terms. We release a new dataset of pairs of publicly available medical sentences and a version of them simplified by clinicians. Also, we define a novel text simplification metric and evaluation framework, which we use to conduct a large-scale human evaluation of our method against the state of the art. Our method based on a language model trained on medical forum data generates simpler sentences while preserving both grammar and the original meaning, surpassing the current state of the art.
Biomedical Concept Relatedness -- A large EHR-based benchmark
Oct 30, 2020
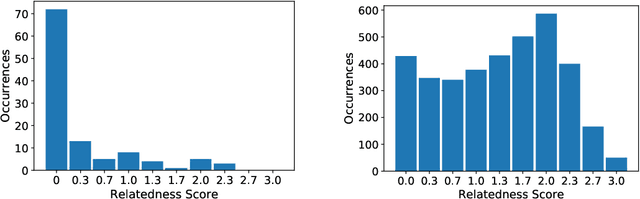
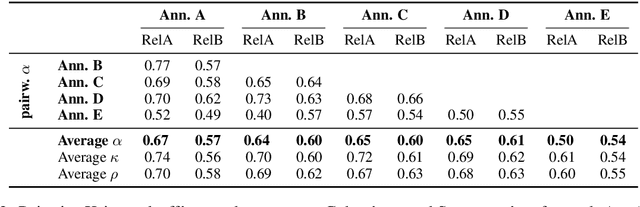
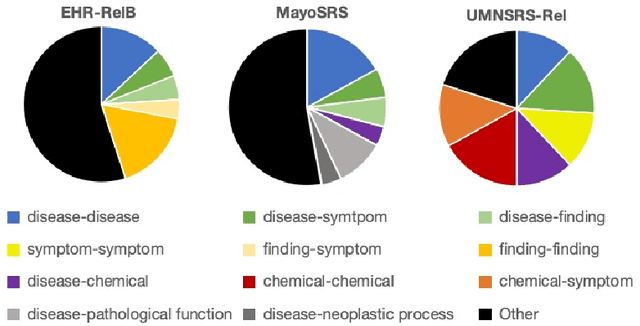
A promising application of AI to healthcare is the retrieval of information from electronic health records (EHRs), e.g. to aid clinicians in finding relevant information for a consultation or to recruit suitable patients for a study. This requires search capabilities far beyond simple string matching, including the retrieval of concepts (diagnoses, symptoms, medications, etc.) related to the one in question. The suitability of AI methods for such applications is tested by predicting the relatedness of concepts with known relatedness scores. However, all existing biomedical concept relatedness datasets are notoriously small and consist of hand-picked concept pairs. We open-source a novel concept relatedness benchmark overcoming these issues: it is six times larger than existing datasets and concept pairs are chosen based on co-occurrence in EHRs, ensuring their relevance for the application of interest. We present an in-depth analysis of our new dataset and compare it to existing ones, highlighting that it is not only larger but also complements existing datasets in terms of the types of concepts included. Initial experiments with state-of-the-art embedding methods show that our dataset is a challenging new benchmark for testing concept relatedness models.
Correlations between Word Vector Sets
Oct 07, 2019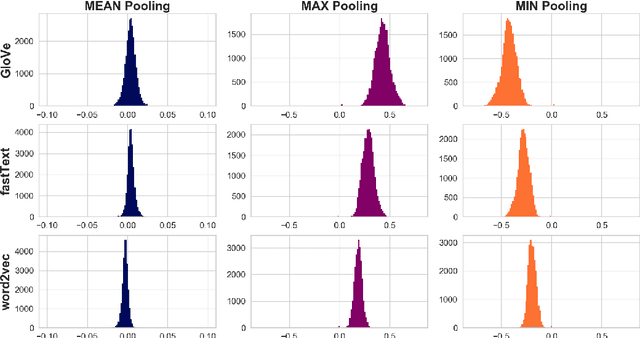
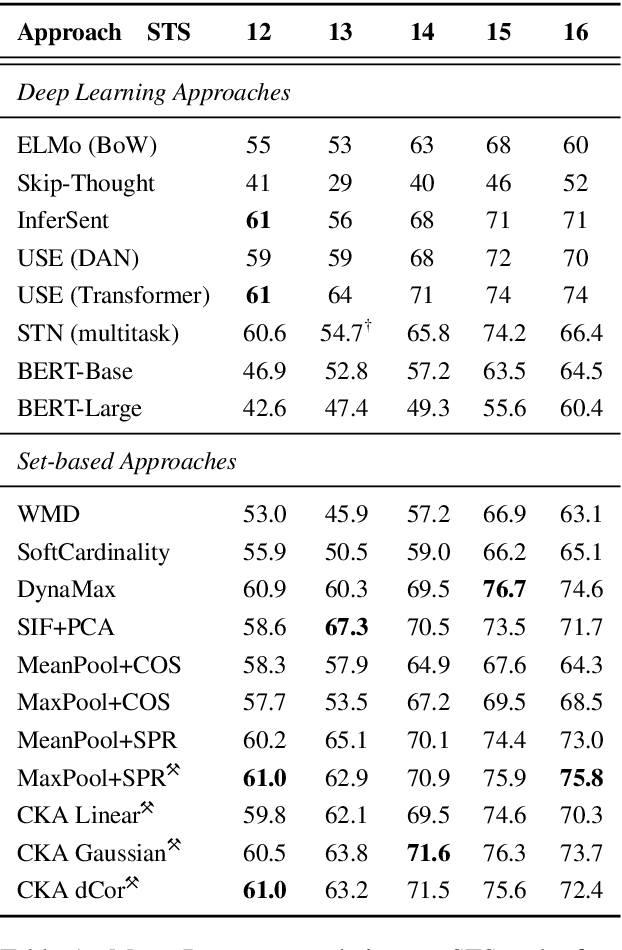
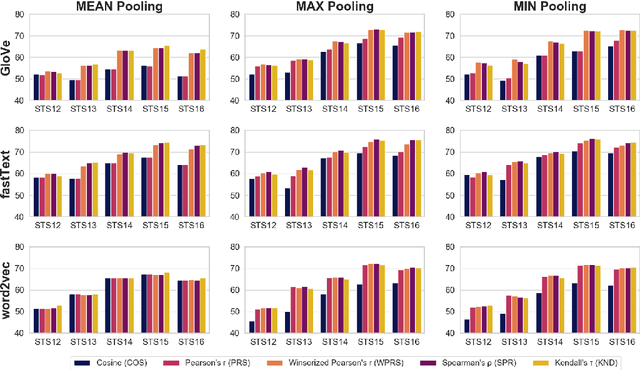

Similarity measures based purely on word embeddings are comfortably competing with much more sophisticated deep learning and expert-engineered systems on unsupervised semantic textual similarity (STS) tasks. In contrast to commonly used geometric approaches, we treat a single word embedding as e.g. 300 observations from a scalar random variable. Using this paradigm, we first illustrate that similarities derived from elementary pooling operations and classic correlation coefficients yield excellent results on standard STS benchmarks, outperforming many recently proposed methods while being much faster and trivial to implement. Next, we demonstrate how to avoid pooling operations altogether and compare sets of word embeddings directly via correlation operators between reproducing kernel Hilbert spaces. Just like cosine similarity is used to compare individual word vectors, we introduce a novel application of the centered kernel alignment (CKA) as a natural generalisation of squared cosine similarity for sets of word vectors. Likewise, CKA is very easy to implement and enjoys very strong empirical results.
Neural Language Priors
Oct 04, 2019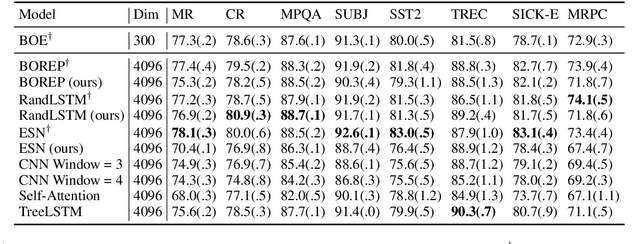
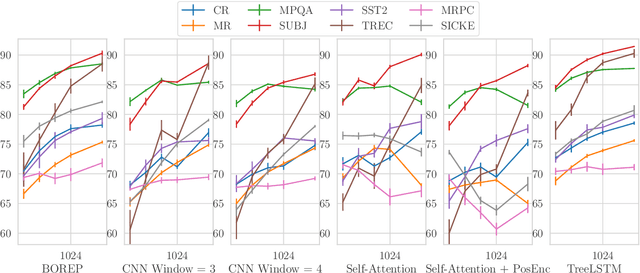
The choice of sentence encoder architecture reflects assumptions about how a sentence's meaning is composed from its constituent words. We examine the contribution of these architectures by holding them randomly initialised and fixed, effectively treating them as as hand-crafted language priors, and evaluating the resulting sentence encoders on downstream language tasks. We find that even when encoders are presented with additional information that can be used to solve tasks, the corresponding priors do not leverage this information, except in an isolated case. We also find that apparently uninformative priors are just as good as seemingly informative priors on almost all tasks, indicating that learning is a necessary component to leverage information provided by architecture choice.
Explaining Deep Learning Models with Constrained Adversarial Examples
Jun 25, 2019
Machine learning algorithms generally suffer from a problem of explainability. Given a classification result from a model, it is typically hard to determine what caused the decision to be made, and to give an informative explanation. We explore a new method of generating counterfactual explanations, which instead of explaining why a particular classification was made explain how a different outcome can be achieved. This gives the recipients of the explanation a better way to understand the outcome, and provides an actionable suggestion. We show that the introduced method of Constrained Adversarial Examples (CADEX) can be used in real world applications, and yields explanations which incorporate business or domain constraints such as handling categorical attributes and range constraints.
Multilingual Factor Analysis
May 14, 2019
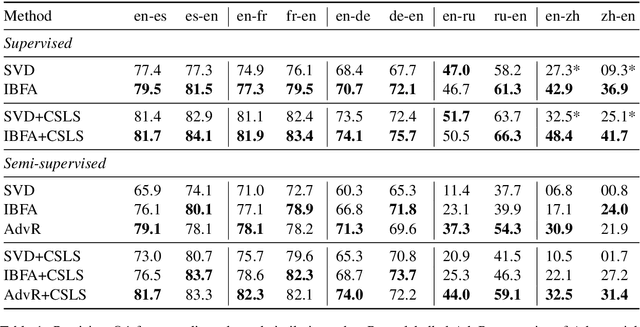

In this work we approach the task of learning multilingual word representations in an offline manner by fitting a generative latent variable model to a multilingual dictionary. We model equivalent words in different languages as different views of the same word generated by a common latent variable representing their latent lexical meaning. We explore the task of alignment by querying the fitted model for multilingual embeddings achieving competitive results across a variety of tasks. The proposed model is robust to noise in the embedding space making it a suitable method for distributed representations learned from noisy corpora.
Model Comparison for Semantic Grouping
May 01, 2019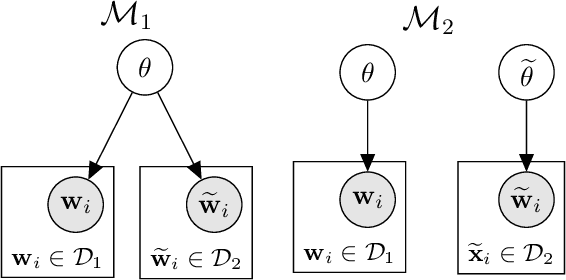
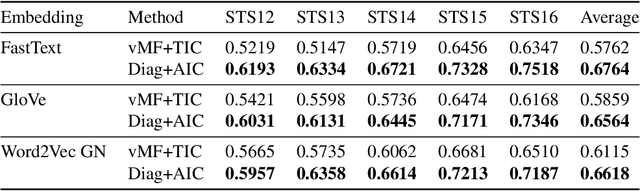
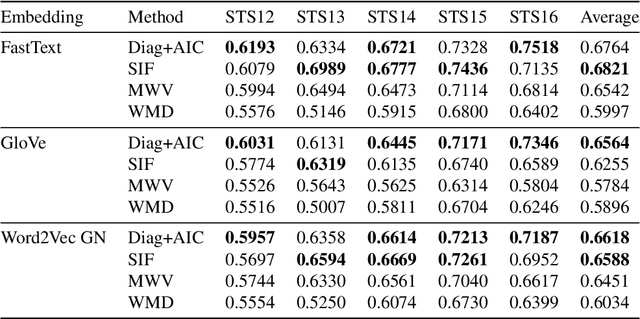
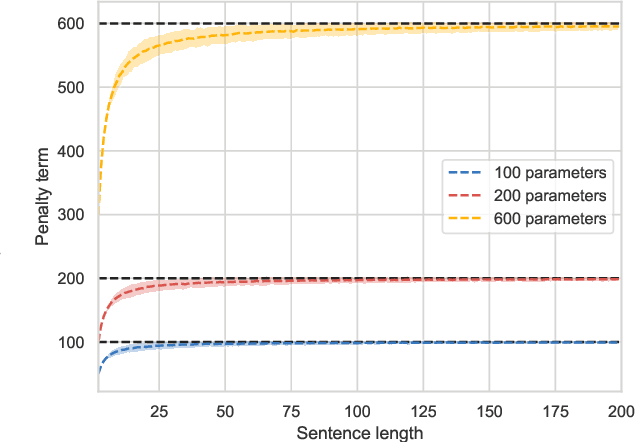
We introduce a probabilistic framework for quantifying the semantic similarity between two groups of embeddings. We formulate the task of semantic similarity as a model comparison task in which we contrast a generative model which jointly models two sentences versus one that does not. We illustrate how this framework can be used for the Semantic Textual Similarity tasks using clear assumptions about how the embeddings of words are generated. We apply model comparison that utilises information criteria to address some of the shortcomings of Bayesian model comparison, whilst still penalising model complexity. We achieve competitive results by applying the proposed framework with an appropriate choice of likelihood on the STS datasets.
Sorting out symptoms: design and evaluation of the 'babylon check' automated triage system
Jun 07, 2016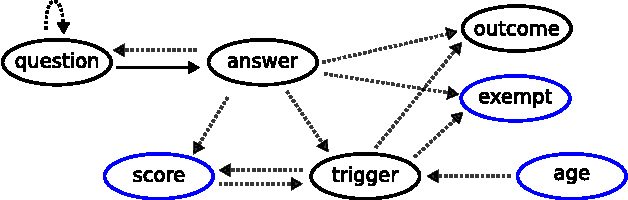
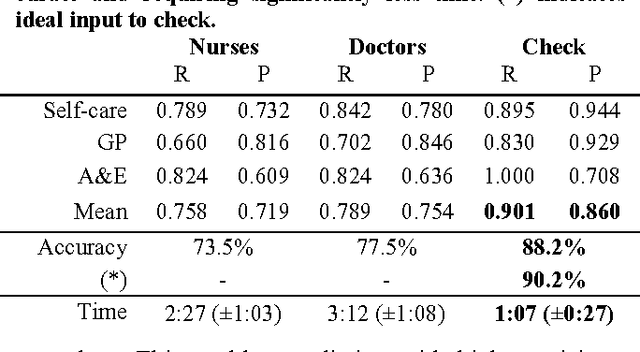
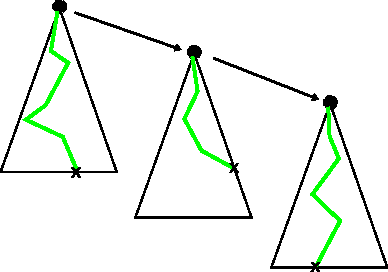
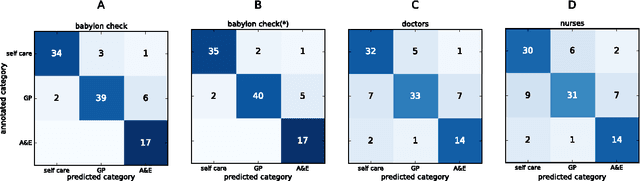
Prior to seeking professional medical care it is increasingly common for patients to use online resources such as automated symptom checkers. Many such systems attempt to provide a differential diagnosis based on the symptoms elucidated from the user, which may lead to anxiety if life or limb-threatening conditions are part of the list, a phenomenon termed 'cyberchondria' [1]. Systems that provide advice on where to seek help, rather than a diagnosis, are equally popular, and in our view provide the most useful information. In this technical report we describe how such a triage system can be modelled computationally, how medical insights can be translated into triage flows, and how such systems can be validated and tested. We present babylon check, our commercially deployed automated triage system, as a case study, and illustrate its performance in a large, semi-naturalistic deployment study.
Towards Using Unlabeled Data in a Sparse-coding Framework for Human Activity Recognition
Jul 23, 2014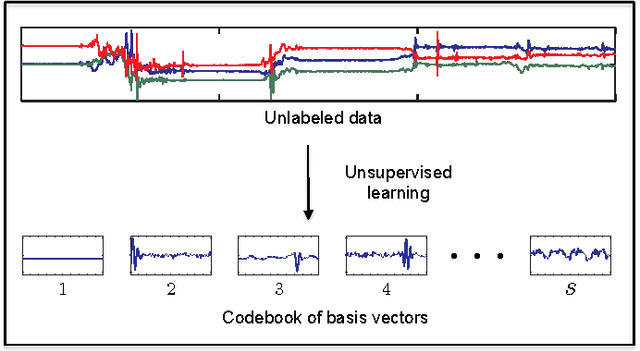


We propose a sparse-coding framework for activity recognition in ubiquitous and mobile computing that alleviates two fundamental problems of current supervised learning approaches. (i) It automatically derives a compact, sparse and meaningful feature representation of sensor data that does not rely on prior expert knowledge and generalizes extremely well across domain boundaries. (ii) It exploits unlabeled sample data for bootstrapping effective activity recognizers, i.e., substantially reduces the amount of ground truth annotation required for model estimation. Such unlabeled data is trivial to obtain, e.g., through contemporary smartphones carried by users as they go about their everyday activities. Based on the self-taught learning paradigm we automatically derive an over-complete set of basis vectors from unlabeled data that captures inherent patterns present within activity data. Through projecting raw sensor data onto the feature space defined by such over-complete sets of basis vectors effective feature extraction is pursued. Given these learned feature representations, classification backends are then trained using small amounts of labeled training data. We study the new approach in detail using two datasets which differ in terms of the recognition tasks and sensor modalities. Primarily we focus on transportation mode analysis task, a popular task in mobile-phone based sensing. The sparse-coding framework significantly outperforms the state-of-the-art in supervised learning approaches. Furthermore, we demonstrate the great practical potential of the new approach by successfully evaluating its generalization capabilities across both domain and sensor modalities by considering the popular Opportunity dataset. Our feature learning approach outperforms state-of-the-art approaches to analyzing activities in daily living.