 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeMAJ (Legal LLM-as-a-Judge): Bridging Legal Reasoning and LLM Evaluation
Oct 08, 2025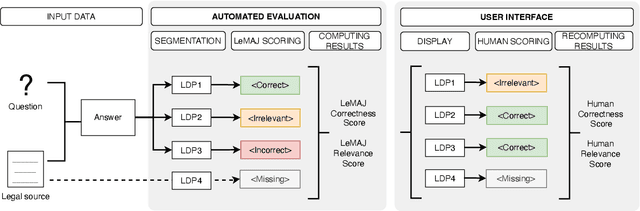

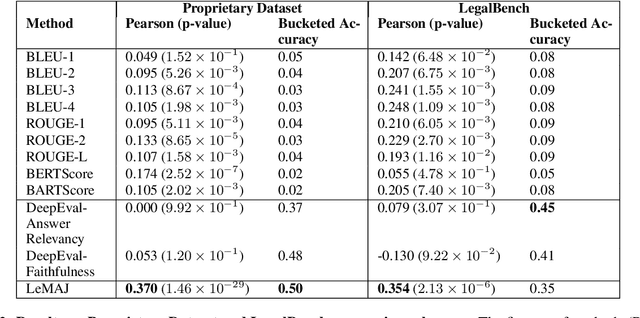
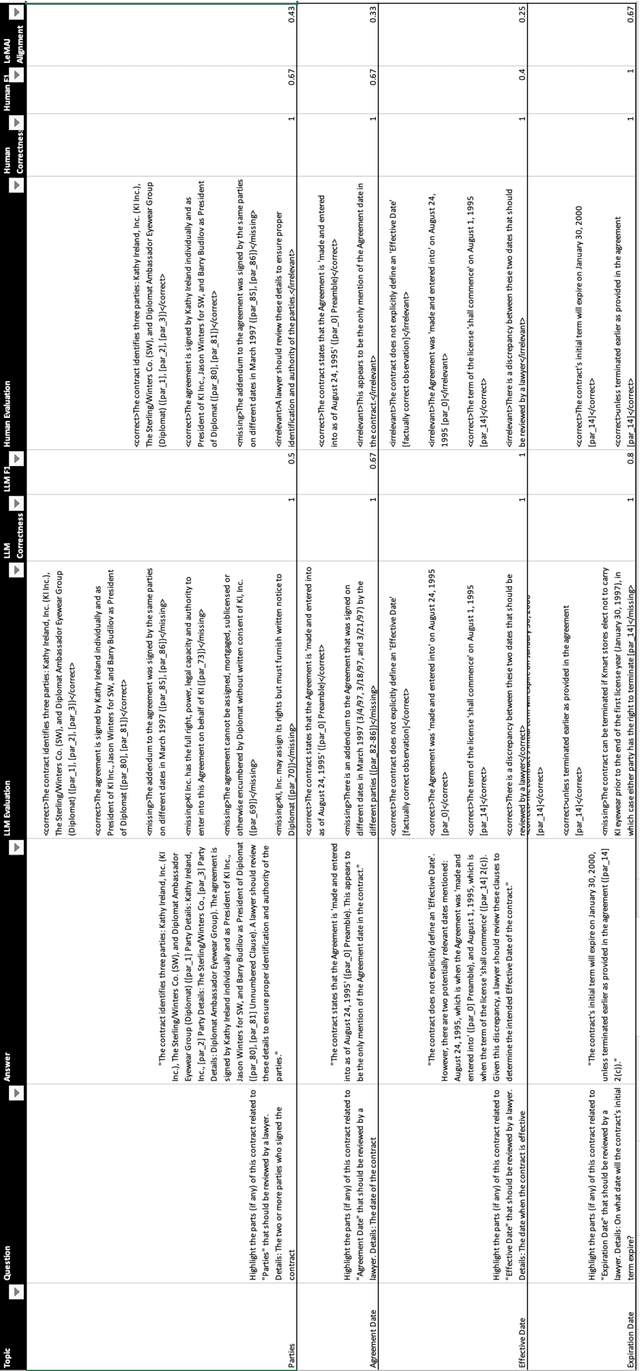
Evaluating large language model (LLM) outputs in the legal domain presents unique challenges due to the complex and nuanced nature of legal analysis. Current evaluation approaches either depend on reference data, which is costly to produce, or use standardized assessment methods, both of which have significant limitations for legal applications. Although LLM-as-a-Judge has emerged as a promising evaluation technique, its reliability and effectiveness in legal contexts depend heavily on evaluation processes unique to the legal industry and how trustworthy the evaluation appears to the human legal expert. This is where existing evaluation methods currently fail and exhibit considerable variability. This paper aims to close the gap: a) we break down lengthy responses into 'Legal Data Points' (LDPs), self-contained units of information, and introduce a novel, reference-free evaluation methodology that reflects how lawyers evaluate legal answers; b) we demonstrate that our method outperforms a variety of baselines on both our proprietary dataset and an open-source dataset (LegalBench); c) we show how our method correlates more closely with human expert evaluations and helps improve inter-annotator agreement; and finally d) we open source our Legal Data Points for a subset of LegalBench used in our experiments, allowing the research community to replicate our results and advance research in this vital area of LLM evaluation on legal question-answering.
Using the Path of Least Resistance to Explain Deep Networks
Feb 17, 2025Integrated Gradients (IG), a widely used axiomatic path-based attribution method, assigns importance scores to input features by integrating model gradients along a straight path from a baseline to the input. While effective in some cases, we show that straight paths can lead to flawed attributions. In this paper, we identify the cause of these misattributions and propose an alternative approach that treats the input space as a Riemannian manifold, computing attributions by integrating gradients along geodesics. We call this method Geodesic Integrated Gradients (GIG). To approximate geodesic paths, we introduce two techniques: a k-Nearest Neighbours-based approach for smaller models and a Stochastic Variational Inference-based method for larger ones. Additionally, we propose a new axiom, Strong Completeness, extending the axioms satisfied by IG. We show that this property is desirable for attribution methods and that GIG is the only method that satisfies it. Through experiments on both synthetic and real-world data, we demonstrate that GIG outperforms existing explainability methods, including IG.
Time Interpret: a Unified Model Interpretability Library for Time Series
Jun 06, 2023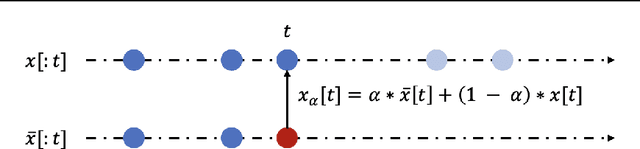
We introduce $\texttt{time_interpret}$, a library designed as an extension of Captum, with a specific focus on temporal data. As such, this library implements several feature attribution methods that can be used to explain predictions made by any Pytorch model. $\texttt{time_interpret}$ also provides several synthetic and real world time series datasets, various PyTorch models, as well as a set of methods to evaluate feature attributions. Moreover, while being primarily developed to explain predictions based on temporal data, some of its components have a different application, including for instance methods explaining predictions made by language models. In this paper, we give a general introduction of this library. We also present several previously unpublished feature attribution methods, which have been developed along with $\texttt{time_interpret}$.
Learning Perturbations to Explain Time Series Predictions
May 30, 2023Explaining predictions based on multivariate time series data carries the additional difficulty of handling not only multiple features, but also time dependencies. It matters not only what happened, but also when, and the same feature could have a very different impact on a prediction depending on this time information. Previous work has used perturbation-based saliency methods to tackle this issue, perturbing an input using a trainable mask to discover which features at which times are driving the predictions. However these methods introduce fixed perturbations, inspired from similar methods on static data, while there seems to be little motivation to do so on temporal data. In this work, we aim to explain predictions by learning not only masks, but also associated perturbations. We empirically show that learning these perturbations significantly improves the quality of these explanations on time series data.
Sequential Integrated Gradients: a simple but effective method for explaining language models
May 25, 2023Several explanation methods such as Integrated Gradients (IG) can be characterised as path-based methods, as they rely on a straight line between the data and an uninformative baseline. However, when applied to language models, these methods produce a path for each word of a sentence simultaneously, which could lead to creating sentences from interpolated words either having no clear meaning, or having a significantly different meaning compared to the original sentence. In order to keep the meaning of these sentences as close as possible to the original one, we propose Sequential Integrated Gradients (SIG), which computes the importance of each word in a sentence by keeping fixed every other words, only creating interpolations between the baseline and the word of interest. Moreover, inspired by the training procedure of several language models, we also propose to replace the baseline token "pad" with the trained token "mask". While being a simple improvement over the original IG method, we show on various models and datasets that SIG proves to be a very effective method for explaining language models.
Neural Temporal Point Processes For Modelling Electronic Health Records
Jul 27, 2020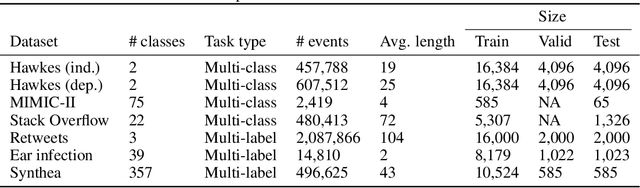
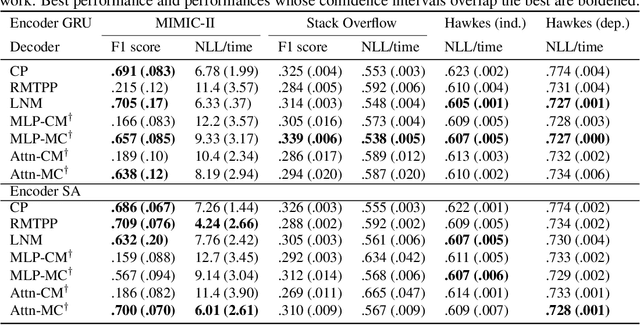
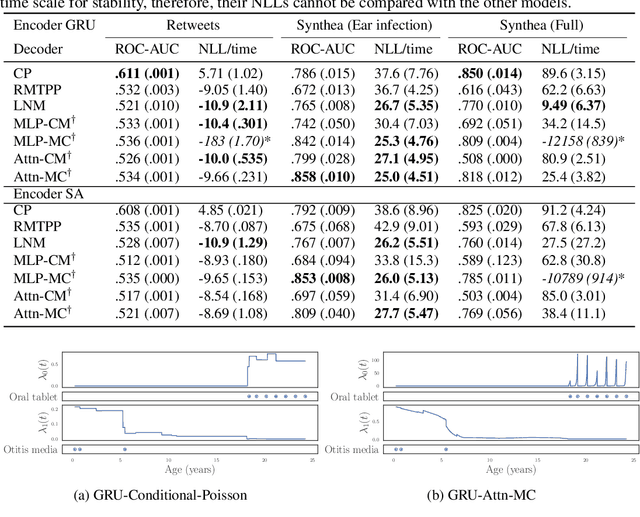
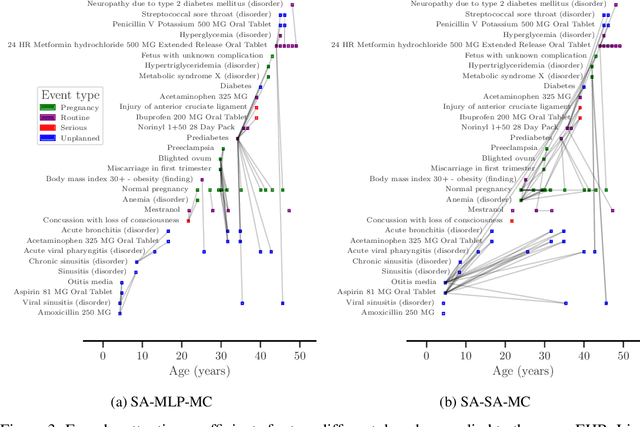
The modelling of Electronic Health Records (EHRs) has the potential to drive more efficient allocation of healthcare resources, enabling early intervention strategies and advancing personalised healthcare. However, EHRs are challenging to model due to their realisation as noisy, multi-modal data occurring at irregular time intervals. To address their temporal nature, we treat EHRs as samples generated by a Temporal Point Process (TPP), enabling us to model what happened in an event with when it happened in a principled way. We gather and propose neural network parameterisations of TPPs, collectively referred to as Neural TPPs. We perform evaluations on synthetic EHRs as well as on a set of established benchmarks. We show that TPPs significantly outperform their non-TPP counterparts on EHRs. We also show that an assumption of many Neural TPPs, that the class distribution is conditionally independent of time, reduces performance on EHRs. Finally, our proposed attention-based Neural TPP performs favourably compared to existing models, and provides insight into how it models the EHR, an important step towards a component of clinical decision support systems.
Neural Language Priors
Oct 04, 2019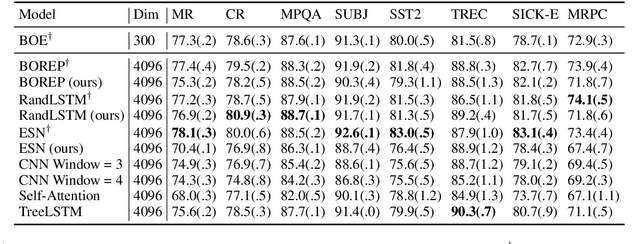
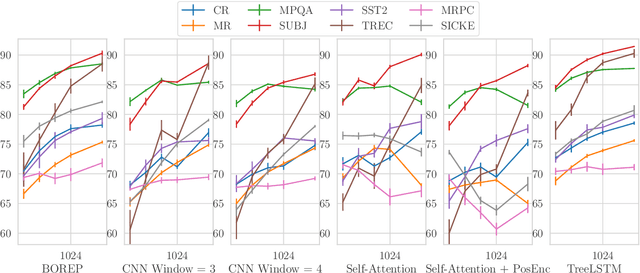
The choice of sentence encoder architecture reflects assumptions about how a sentence's meaning is composed from its constituent words. We examine the contribution of these architectures by holding them randomly initialised and fixed, effectively treating them as as hand-crafted language priors, and evaluating the resulting sentence encoders on downstream language tasks. We find that even when encoders are presented with additional information that can be used to solve tasks, the corresponding priors do not leverage this information, except in an isolated case. We also find that apparently uninformative priors are just as good as seemingly informative priors on almost all tasks, indicating that learning is a necessary component to leverage information provided by architecture choice.