 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Preference Optimisation in Protein LMs for Hit Maturation in Cell Therapy
Dec 03, 2024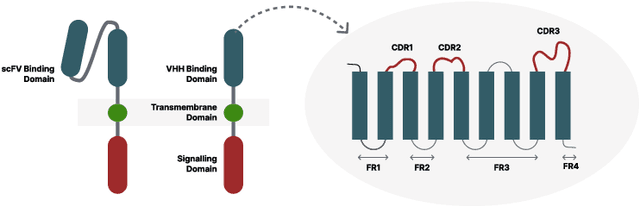
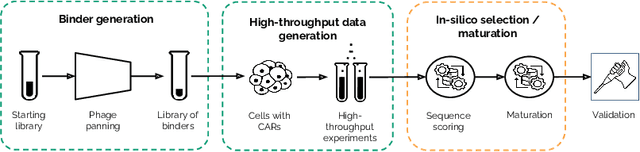
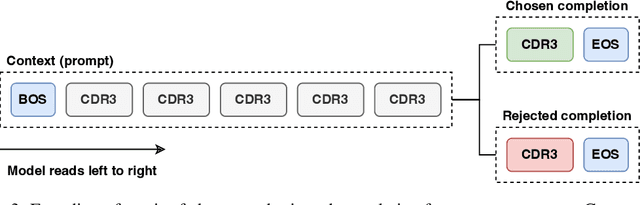
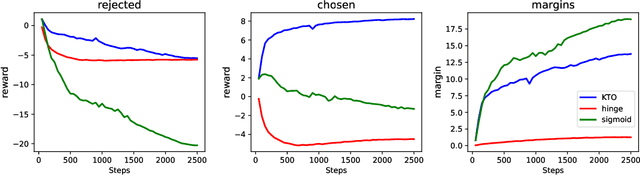
Cell and immunotherapy offer transformative potential for treating diseases like cancer and autoimmune disorders by modulating the immune system. The development of these therapies is resource-intensive, with the majority of drug candidates failing to progress beyond laboratory testing. While recent advances in machine learning have revolutionised areas such as protein engineering, applications in immunotherapy remain limited due to the scarcity of large-scale, standardised datasets and the complexity of cellular systems. In this work, we address these challenges by leveraging a high-throughput experimental platform to generate data suitable for fine-tuning protein language models. We demonstrate how models fine-tuned using a preference task show surprising correlations to biological assays, and how they can be leveraged for few-shot hit maturation in CARs. This proof-of-concept presents a novel pathway for applying ML to immunotherapy and could generalise to other therapeutic modalities.
Neural Temporal Point Processes For Modelling Electronic Health Records
Jul 27, 2020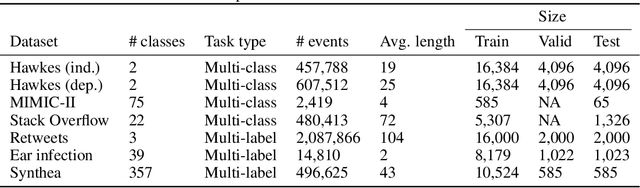
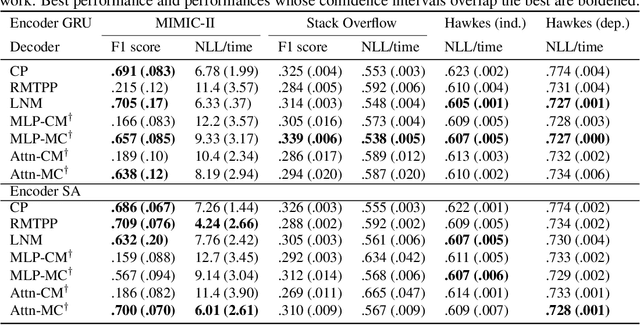
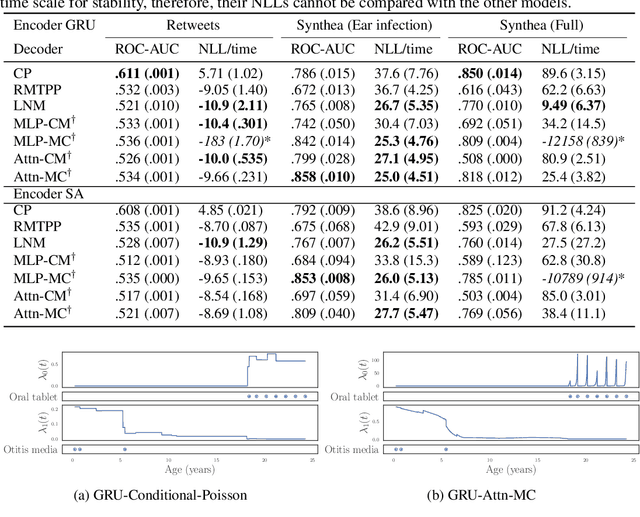
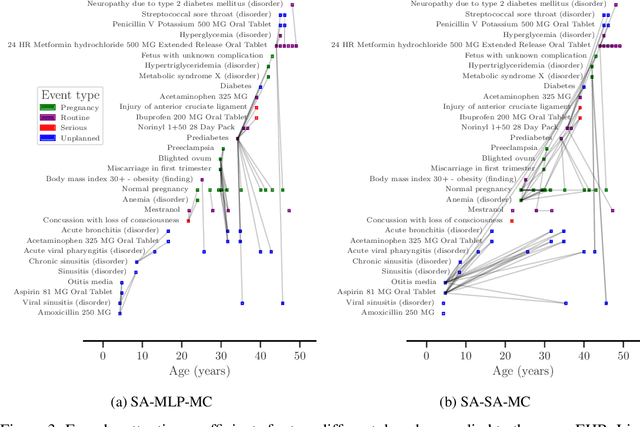
The modelling of Electronic Health Records (EHRs) has the potential to drive more efficient allocation of healthcare resources, enabling early intervention strategies and advancing personalised healthcare. However, EHRs are challenging to model due to their realisation as noisy, multi-modal data occurring at irregular time intervals. To address their temporal nature, we treat EHRs as samples generated by a Temporal Point Process (TPP), enabling us to model what happened in an event with when it happened in a principled way. We gather and propose neural network parameterisations of TPPs, collectively referred to as Neural TPPs. We perform evaluations on synthetic EHRs as well as on a set of established benchmarks. We show that TPPs significantly outperform their non-TPP counterparts on EHRs. We also show that an assumption of many Neural TPPs, that the class distribution is conditionally independent of time, reduces performance on EHRs. Finally, our proposed attention-based Neural TPP performs favourably compared to existing models, and provides insight into how it models the EHR, an important step towards a component of clinical decision support systems.
Correlation Coefficients and Semantic Textual Similarity
May 19, 2019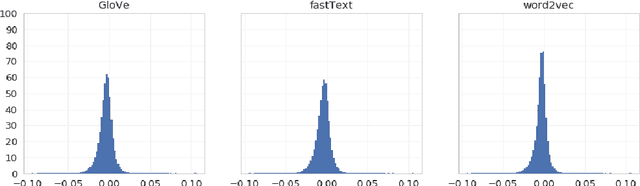
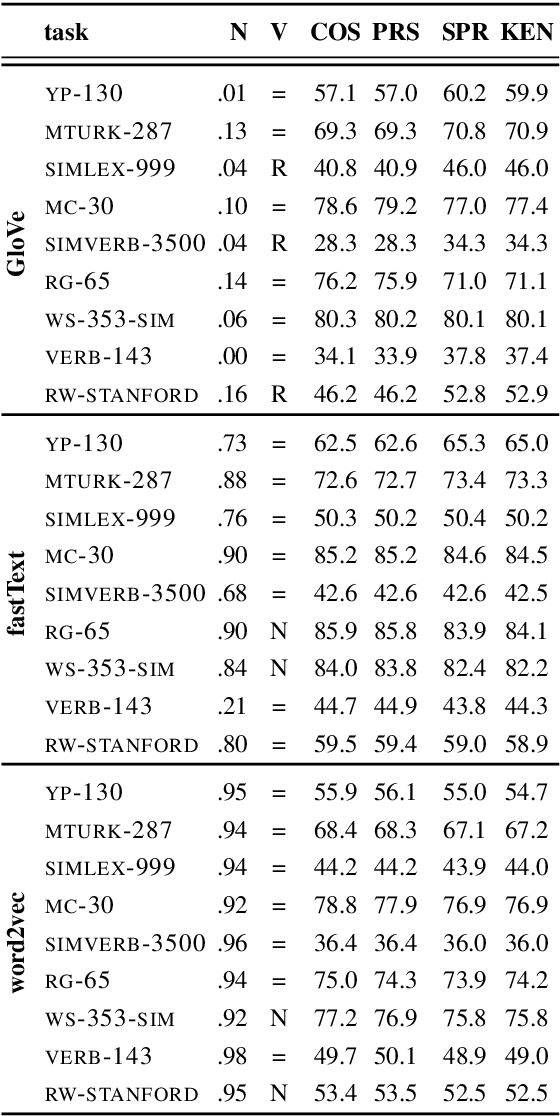
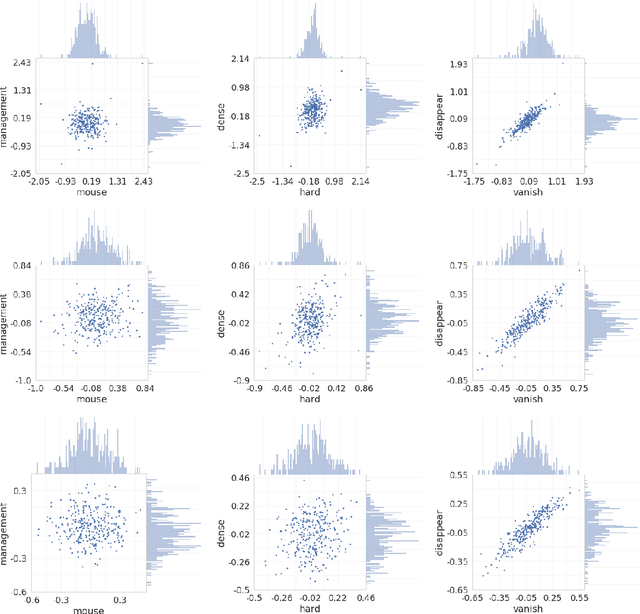
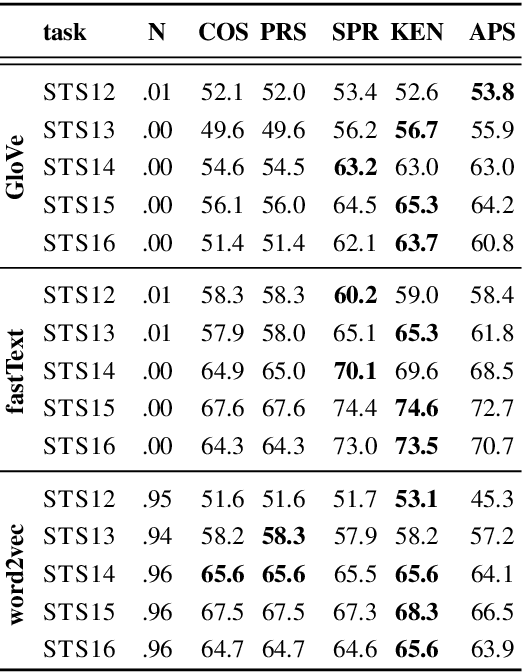
A large body of research into semantic textual similarity has focused on constructing state-of-the-art embeddings using sophisticated modelling, careful choice of learning signals and many clever tricks. By contrast, little attention has been devoted to similarity measures between these embeddings, with cosine similarity being used unquestionably in the majority of cases. In this work, we illustrate that for all common word vectors, cosine similarity is essentially equivalent to the Pearson correlation coefficient, which provides some justification for its use. We thoroughly characterise cases where Pearson correlation (and thus cosine similarity) is unfit as similarity measure. Importantly, we show that Pearson correlation is appropriate for some word vectors but not others. When it is not appropriate, we illustrate how common non-parametric rank correlation coefficients can be used instead to significantly improve performance. We support our analysis with a series of evaluations on word-level and sentence-level semantic textual similarity benchmarks. On the latter, we show that even the simplest averaged word vectors compared by rank correlation easily rival the strongest deep representations compared by cosine similarity.
Don't Settle for Average, Go for the Max: Fuzzy Sets and Max-Pooled Word Vectors
Apr 30, 2019



Recent literature suggests that averaged word vectors followed by simple post-processing outperform many deep learning methods on semantic textual similarity tasks. Furthermore, when averaged word vectors are trained supervised on large corpora of paraphrases, they achieve state-of-the-art results on standard STS benchmarks. Inspired by these insights, we push the limits of word embeddings even further. We propose a novel fuzzy bag-of-words (FBoW) representation for text that contains all the words in the vocabulary simultaneously but with different degrees of membership, which are derived from similarities between word vectors. We show that max-pooled word vectors are only a special case of fuzzy BoW and should be compared via fuzzy Jaccard index rather than cosine similarity. Finally, we propose DynaMax, a completely unsupervised and non-parametric similarity measure that dynamically extracts and max-pools good features depending on the sentence pair. This method is both efficient and easy to implement, yet outperforms current baselines on STS tasks by a large margin and is even competitive with supervised word vectors trained to directly optimise cosine similarity.
Relational Graph Attention Networks
Apr 11, 2019

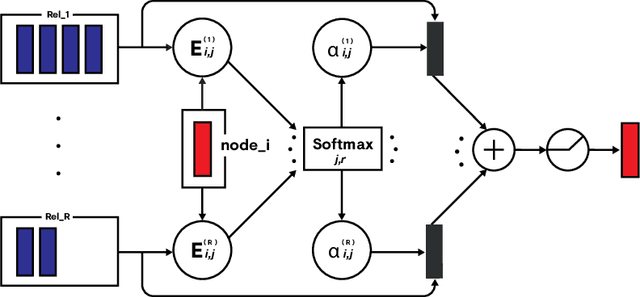

We investigate Relational Graph Attention Networks, a class of models that extends non-relational graph attention mechanisms to incorporate relational information, opening up these methods to a wider variety of problems. A thorough evaluation of these models is performed, and comparisons are made against established benchmarks. To provide a meaningful comparison, we retrain Relational Graph Convolutional Networks, the spectral counterpart of Relational Graph Attention Networks, and evaluate them under the same conditions. We find that Relational Graph Attention Networks perform worse than anticipated, although some configurations are marginally beneficial for modelling molecular properties. We provide insights as to why this may be, and suggest both modifications to evaluation strategies, as well as directions to investigate for future work.
Decoding Decoders: Finding Optimal Representation Spaces for Unsupervised Similarity Tasks
May 09, 2018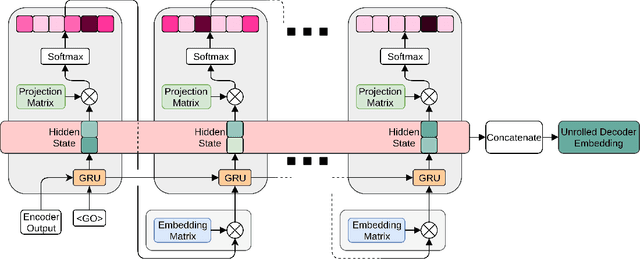
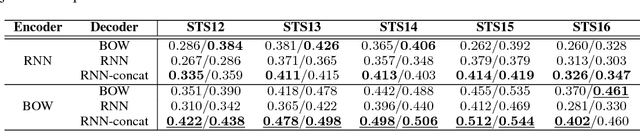
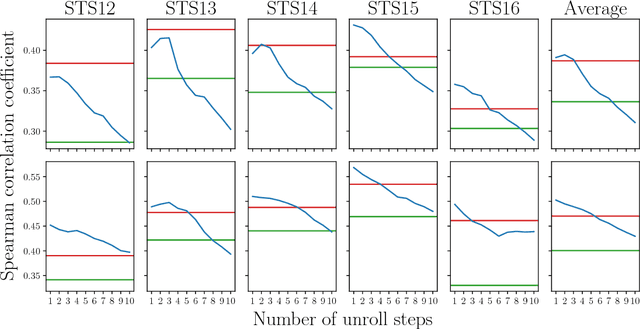

Experimental evidence indicates that simple models outperform complex deep networks on many unsupervised similarity tasks. We provide a simple yet rigorous explanation for this behaviour by introducing the concept of an optimal representation space, in which semantically close symbols are mapped to representations that are close under a similarity measure induced by the model's objective function. In addition, we present a straightforward procedure that, without any retraining or architectural modifications, allows deep recurrent models to perform equally well (and sometimes better) when compared to shallow models. To validate our analysis, we conduct a set of consistent empirical evaluations and introduce several new sentence embedding models in the process. Even though this work is presented within the context of natural language processing, the insights are readily applicable to other domains that rely on distributed representations for transfer tasks.
Offline bilingual word vectors, orthogonal transformations and the inverted softmax
Feb 13, 2017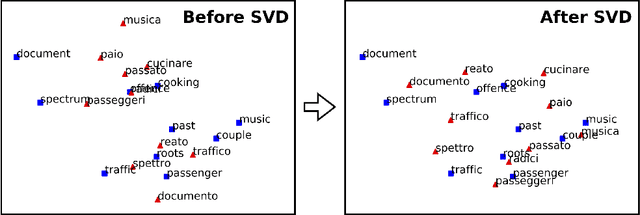
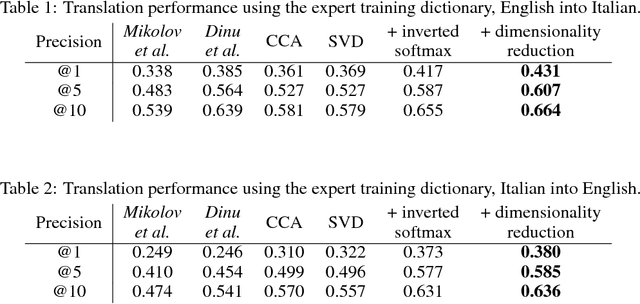
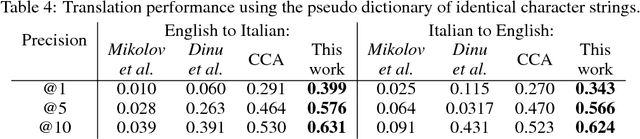
Usually bilingual word vectors are trained "online". Mikolov et al. showed they can also be found "offline", whereby two pre-trained embeddings are aligned with a linear transformation, using dictionaries compiled from expert knowledge. In this work, we prove that the linear transformation between two spaces should be orthogonal. This transformation can be obtained using the singular value decomposition. We introduce a novel "inverted softmax" for identifying translation pairs, with which we improve the precision @1 of Mikolov's original mapping from 34% to 43%, when translating a test set composed of both common and rare English words into Italian. Orthogonal transformations are more robust to noise, enabling us to learn the transformation without expert bilingual signal by constructing a "pseudo-dictionary" from the identical character strings which appear in both languages, achieving 40% precision on the same test set. Finally, we extend our method to retrieve the true translations of English sentences from a corpus of 200k Italian sentences with a precision @1 of 68%.
Deep, Convolutional, and Recurrent Models for Human Activity Recognition using Wearables
Apr 29, 2016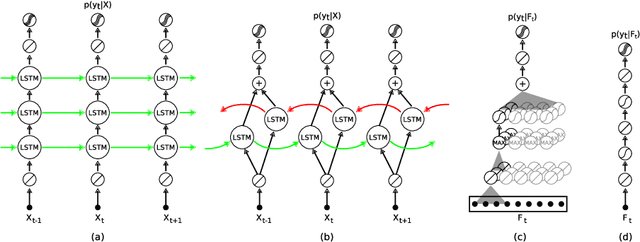

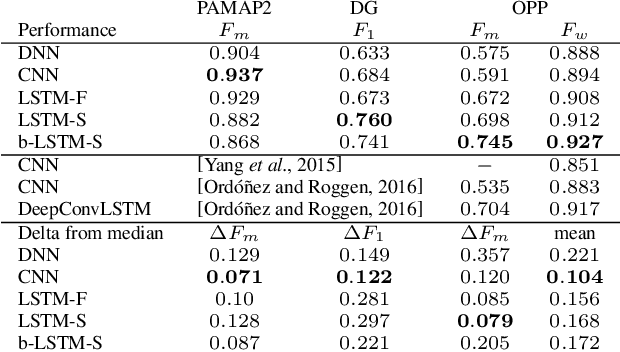
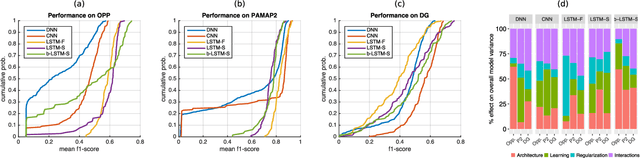
Human activity recognition (HAR) in ubiquitous computing is beginning to adopt deep learning to substitute for well-established analysis techniques that rely on hand-crafted feature extraction and classification techniques. From these isolated applications of custom deep architectures it is, however, difficult to gain an overview of their suitability for problems ranging from the recognition of manipulative gestures to the segmentation and identification of physical activities like running or ascending stairs. In this paper we rigorously explore deep, convolutional, and recurrent approaches across three representative datasets that contain movement data captured with wearable sensors. We describe how to train recurrent approaches in this setting, introduce a novel regularisation approach, and illustrate how they outperform the state-of-the-art on a large benchmark dataset. Across thousands of recognition experiments with randomly sampled model configurations we investigate the suitability of each model for different tasks in HAR, explore the impact of hyperparameters using the fANOVA framework, and provide guidelines for the practitioner who wants to apply deep learning in their problem setting.