 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Preference Optimisation in Protein LMs for Hit Maturation in Cell Therapy
Dec 03, 2024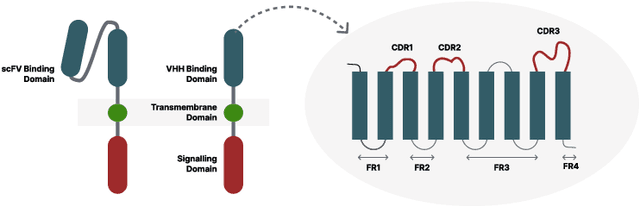
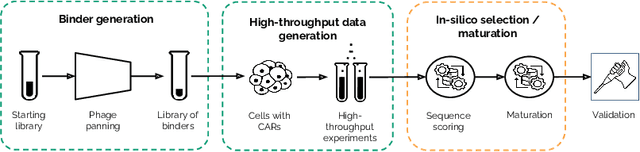
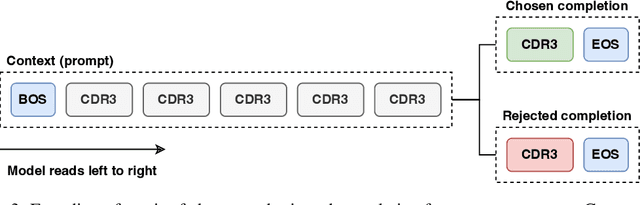
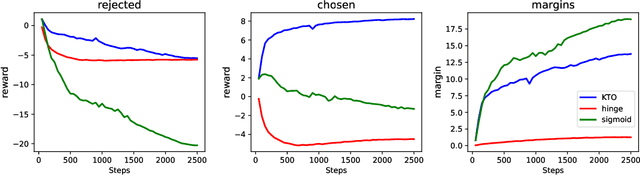
Cell and immunotherapy offer transformative potential for treating diseases like cancer and autoimmune disorders by modulating the immune system. The development of these therapies is resource-intensive, with the majority of drug candidates failing to progress beyond laboratory testing. While recent advances in machine learning have revolutionised areas such as protein engineering, applications in immunotherapy remain limited due to the scarcity of large-scale, standardised datasets and the complexity of cellular systems. In this work, we address these challenges by leveraging a high-throughput experimental platform to generate data suitable for fine-tuning protein language models. We demonstrate how models fine-tuned using a preference task show surprising correlations to biological assays, and how they can be leveraged for few-shot hit maturation in CARs. This proof-of-concept presents a novel pathway for applying ML to immunotherapy and could generalise to other therapeutic modalities.
TwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
Feb 27, 2023



Recommendation systems are a core feature of social media companies with their uses including recommending organic and promoted contents. Many modern recommendation systems are split into multiple stages - candidate generation and heavy ranking - to balance computational cost against recommendation quality. We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC. We show that a system that combines a real-time light ranker with sourcing strategies capable of capturing additional information provides validated gains. We present two strategies. The first strategy uses a notion of similarity in the interaction graph, while the second strategy caches previous scores from the ranking stage. The graph based strategy achieves a 4.08% revenue gain and the rankscore based strategy achieves a 1.38% gain. These two strategies have biases that complement both the light ranker and one another. Finally, we describe a set of metrics that we believe are valuable as a means of understanding the complex product trade offs inherent in industrial candidate generation systems.
On Loss Functions for Deep Neural Networks in Classification
Feb 18, 2017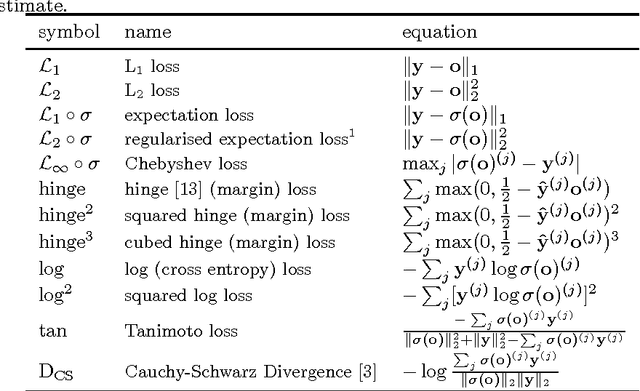
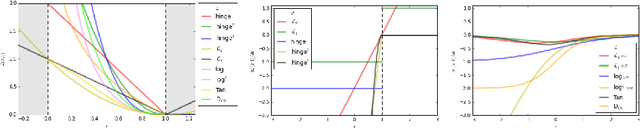
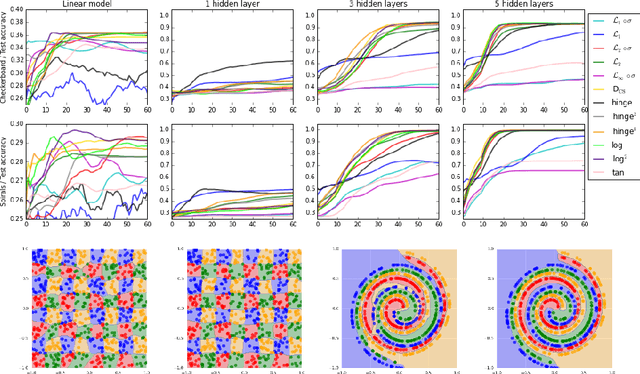
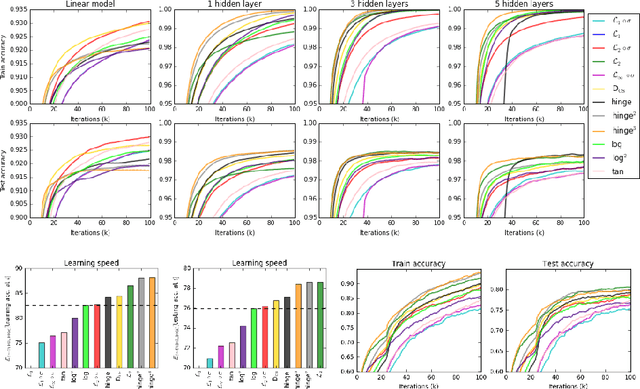
Deep neural networks are currently among the most commonly used classifiers. Despite easily achieving very good performance, one of the best selling points of these models is their modular design - one can conveniently adapt their architecture to specific needs, change connectivity patterns, attach specialised layers, experiment with a large amount of activation functions, normalisation schemes and many others. While one can find impressively wide spread of various configurations of almost every aspect of the deep nets, one element is, in authors' opinion, underrepresented - while solving classification problems, vast majority of papers and applications simply use log loss. In this paper we try to investigate how particular choices of loss functions affect deep models and their learning dynamics, as well as resulting classifiers robustness to various effects. We perform experiments on classical datasets, as well as provide some additional, theoretical insights into the problem. In particular we show that L1 and L2 losses are, quite surprisingly, justified classification objectives for deep nets, by providing probabilistic interpretation in terms of expected misclassification. We also introduce two losses which are not typically used as deep nets objectives and show that they are viable alternatives to the existing ones.