 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwERC: High Performance Ensembled Candidate Generation for Ads Recommendation at Twitter
Feb 27, 2023



Recommendation systems are a core feature of social media companies with their uses including recommending organic and promoted contents. Many modern recommendation systems are split into multiple stages - candidate generation and heavy ranking - to balance computational cost against recommendation quality. We focus on the candidate generation phase of a large-scale ads recommendation problem in this paper, and present a machine learning first heterogeneous re-architecture of this stage which we term TwERC. We show that a system that combines a real-time light ranker with sourcing strategies capable of capturing additional information provides validated gains. We present two strategies. The first strategy uses a notion of similarity in the interaction graph, while the second strategy caches previous scores from the ranking stage. The graph based strategy achieves a 4.08% revenue gain and the rankscore based strategy achieves a 1.38% gain. These two strategies have biases that complement both the light ranker and one another. Finally, we describe a set of metrics that we believe are valuable as a means of understanding the complex product trade offs inherent in industrial candidate generation systems.
Learning to Infer Structures of Network Games
Jun 16, 2022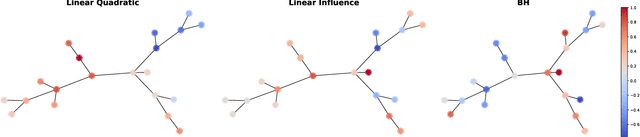

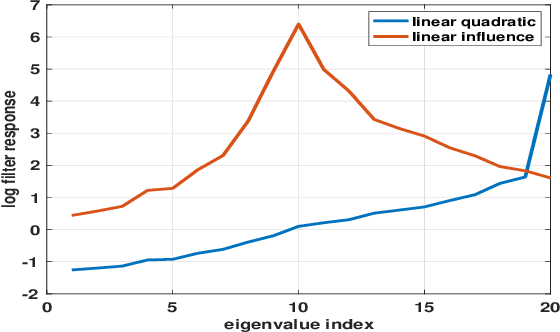
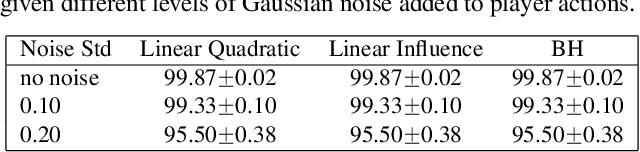
Strategic interactions between a group of individuals or organisations can be modelled as games played on networks, where a player's payoff depends not only on their actions but also on those of their neighbours. Inferring the network structure from observed game outcomes (equilibrium actions) is an important problem with numerous potential applications in economics and social sciences. Existing methods mostly require the knowledge of the utility function associated with the game, which is often unrealistic to obtain in real-world scenarios. We adopt a transformer-like architecture which correctly accounts for the symmetries of the problem and learns a mapping from the equilibrium actions to the network structure of the game without explicit knowledge of the utility function. We test our method on three different types of network games using both synthetic and real-world data, and demonstrate its effectiveness in network structure inference and superior performance over existing methods.
Temporal Graph Networks for Deep Learning on Dynamic Graphs
Jun 18, 2020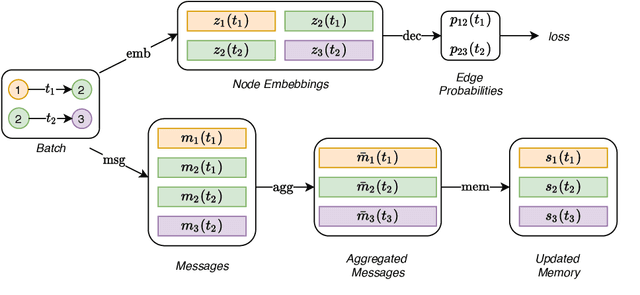
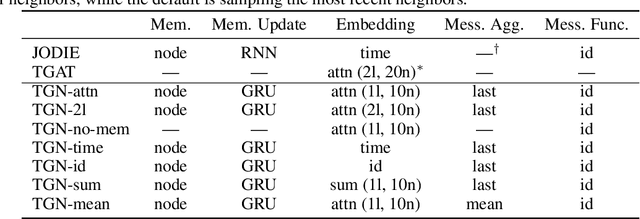
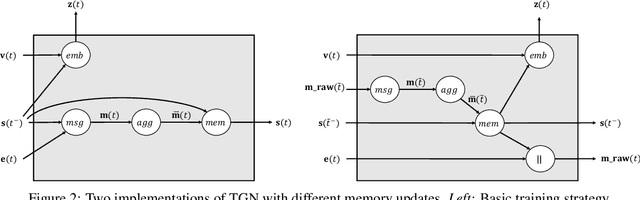
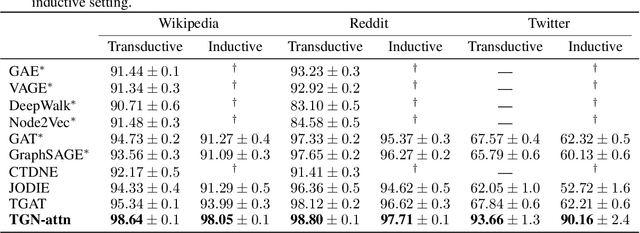
Graph Neural Networks (GNNs) have recently become increasingly popular due to their ability to learn complex systems of relations or interactions arising in a broad spectrum of problems ranging from biology and particle physics to social networks and recommendation systems. Despite the plethora of different models for deep learning on graphs, few approaches have been proposed thus far for dealing with graphs that present some sort of dynamic nature (e.g. evolving features or connectivity over time). In this paper, we present Temporal Graph Networks (TGNs), a generic, efficient framework for deep learning on dynamic graphs represented as sequences of timed events. Thanks to a novel combination of memory modules and graph-based operators, TGNs are able to significantly outperform previous approaches being at the same time more computationally efficient. We furthermore show that several previous models for learning on dynamic graphs can be cast as specific instances of our framework. We perform a detailed ablation study of different components of our framework and devise the best configuration that achieves state-of-the-art performance on several transductive and inductive prediction tasks for dynamic graphs.
SIGN: Scalable Inception Graph Neural Networks
Apr 23, 2020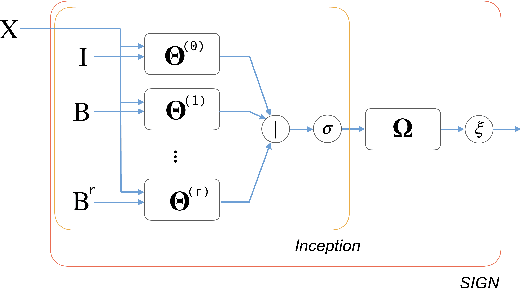

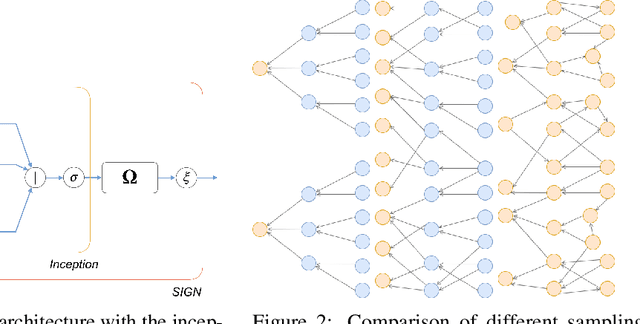

Geometric deep learning, a novel class of machine learning algorithms extending classical deep learning architectures to non-Euclidean structured data such as manifolds and graphs, has recently been applied to a broad spectrum of problems ranging from computer graphics and chemistry to high energy physics and social media. In this paper, we propose SIGN, a scalable graph neural network analogous to the popular inception module used in classical convolutional architectures. We show that our architecture is able to effectively deal with large-scale graphs via pre-computed multi-scale neighborhood features. Extensive experimental evaluation on various open benchmarks shows the competitive performance of our approach compared to a variety of popular architectures, while requiring a fraction of training and inference time.
ncRNA Classification with Graph Convolutional Networks
May 16, 2019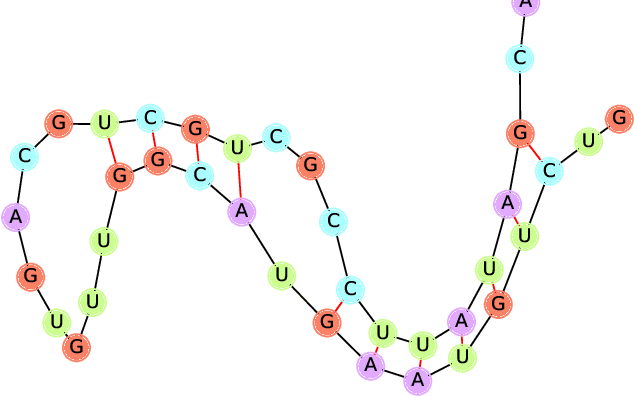



Non-coding RNA (ncRNA) are RNA sequences which don't code for a gene but instead carry important biological functions. The task of ncRNA classification consists in classifying a given ncRNA sequence into its family. While it has been shown that the graph structure of an ncRNA sequence folding is of great importance for the prediction of its family, current methods make use of machine learning classifiers on hand-crafted graph features. We improve on the state-of-the-art for this task with a graph convolutional network model which achieves an accuracy of 85.73% and an F1-score of 85.61% over 13 classes. Moreover, our model learns in an end-to-end fashion from the raw RNA graphs and removes the need for expensive feature extraction. To the best of our knowledge, this also represents the first successful application of graph convolutional networks to RNA folding data.
Fake News Detection on Social Media using Geometric Deep Learning
Feb 10, 2019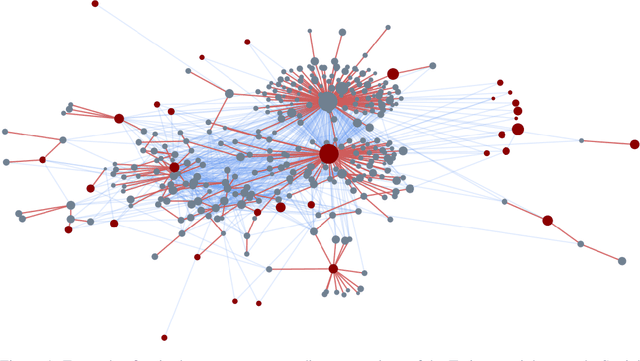
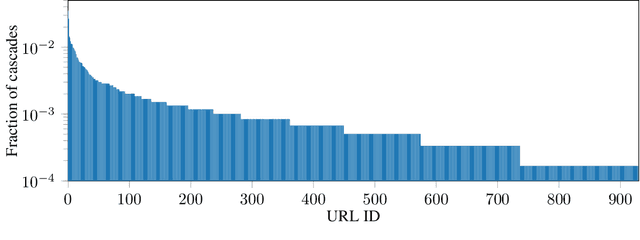
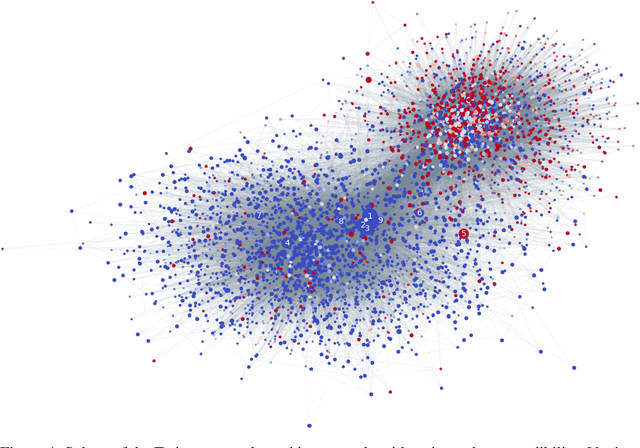
Social media are nowadays one of the main news sources for millions of people around the globe due to their low cost, easy access and rapid dissemination. This however comes at the cost of dubious trustworthiness and significant risk of exposure to 'fake news', intentionally written to mislead the readers. Automatically detecting fake news poses challenges that defy existing content-based analysis approaches. One of the main reasons is that often the interpretation of the news requires the knowledge of political or social context or 'common sense', which current NLP algorithms are still missing. Recent studies have shown that fake and real news spread differently on social media, forming propagation patterns that could be harnessed for the automatic fake news detection. Propagation-based approaches have multiple advantages compared to their content-based counterparts, among which is language independence and better resilience to adversarial attacks. In this paper we show a novel automatic fake news detection model based on geometric deep learning. The underlying core algorithms are a generalization of classical CNNs to graphs, allowing the fusion of heterogeneous data such as content, user profile and activity, social graph, and news propagation. Our model was trained and tested on news stories, verified by professional fact-checking organizations, that were spread on Twitter. Our experiments indicate that social network structure and propagation are important features allowing highly accurate (92.7% ROC AUC) fake news detection. Second, we observe that fake news can be reliably detected at an early stage, after just a few hours of propagation. Third, we test the aging of our model on training and testing data separated in time. Our results point to the promise of propagation-based approaches for fake news detection as an alternative or complementary strategy to content-based approaches.
Using Attribution to Decode Dataset Bias in Neural Network Models for Chemistry
Nov 29, 2018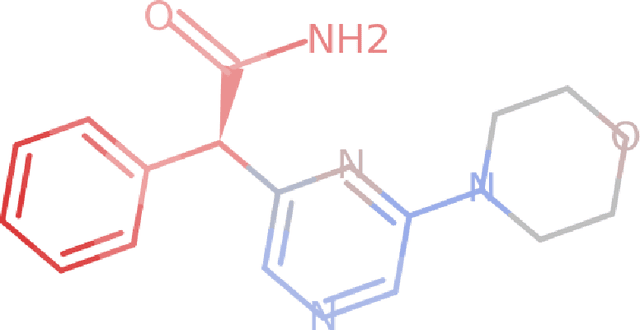
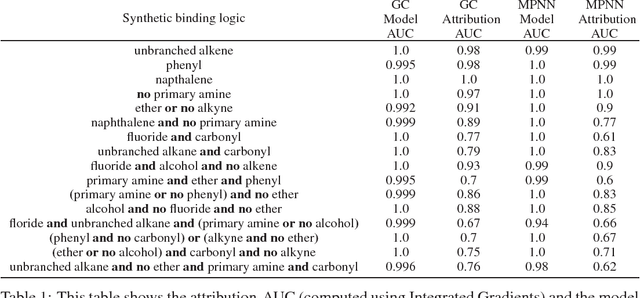
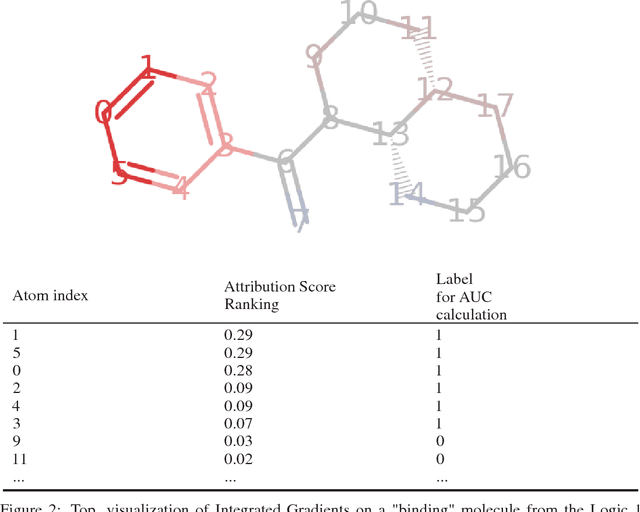
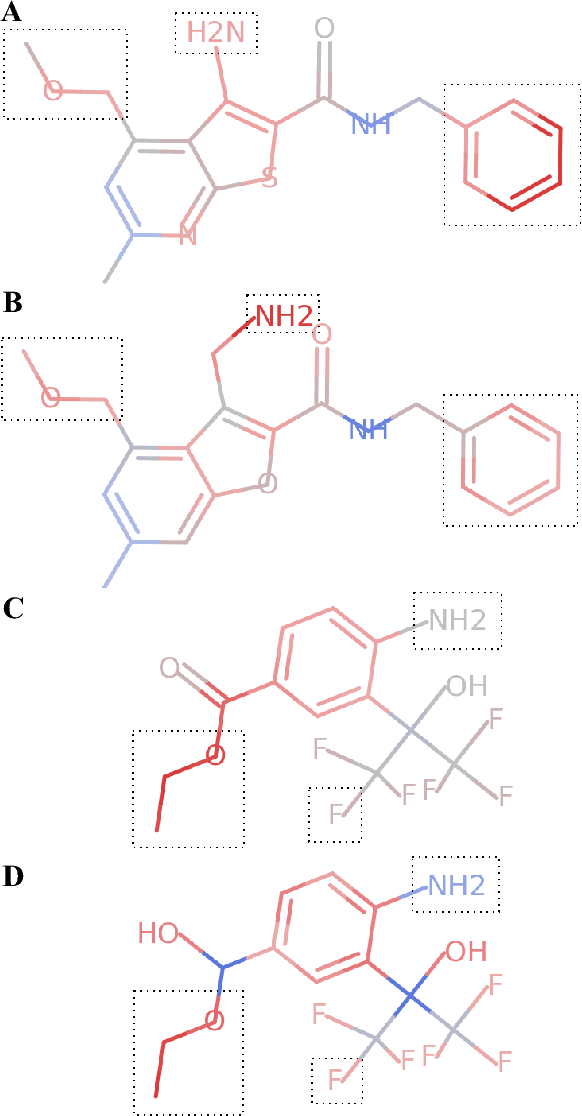
Deep neural networks have achieved state of the art accuracy at classifying molecules with respect to whether they bind to specific protein targets. A key breakthrough would occur if these models could reveal the fragment pharmacophores that are causally involved in binding. Extracting chemical details of binding from the networks could potentially lead to scientific discoveries about the mechanisms of drug actions. But doing so requires shining light into the black box that is the trained neural network model, a task that has proved difficult across many domains. Here we show how the binding mechanism learned by deep neural network models can be interrogated, using a recently described attribution method. We first work with carefully constructed synthetic datasets, in which the 'fragment logic' of binding is fully known. We find that networks that achieve perfect accuracy on held out test datasets still learn spurious correlations due to biases in the datasets, and we are able to exploit this non-robustness to construct adversarial examples that fool the model. The dataset bias makes these models unreliable for accurately revealing information about the mechanisms of protein-ligand binding. In light of our findings, we prescribe a test that checks for dataset bias given a hypothesis. If the test fails, it indicates that either the model must be simplified or regularized and/or that the training dataset requires augmentation.
CayleyNets: Graph Convolutional Neural Networks with Complex Rational Spectral Filters
Oct 31, 2018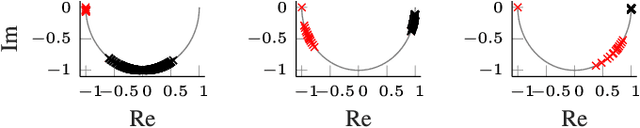

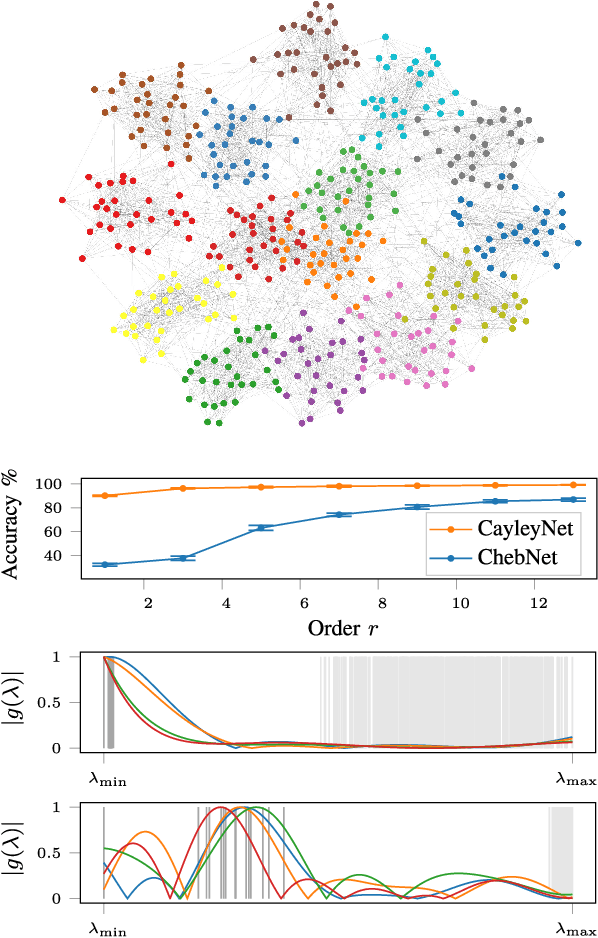
The rise of graph-structured data such as social networks, regulatory networks, citation graphs, and functional brain networks, in combination with resounding success of deep learning in various applications, has brought the interest in generalizing deep learning models to non-Euclidean domains. In this paper, we introduce a new spectral domain convolutional architecture for deep learning on graphs. The core ingredient of our model is a new class of parametric rational complex functions (Cayley polynomials) allowing to efficiently compute spectral filters on graphs that specialize on frequency bands of interest. Our model generates rich spectral filters that are localized in space, scales linearly with the size of the input data for sparsely-connected graphs, and can handle different constructions of Laplacian operators. Extensive experimental results show the superior performance of our approach, in comparison to other spectral domain convolutional architectures, on spectral image classification, community detection, vertex classification and matrix completion tasks.
Graph Neural Networks for IceCube Signal Classification
Sep 17, 2018
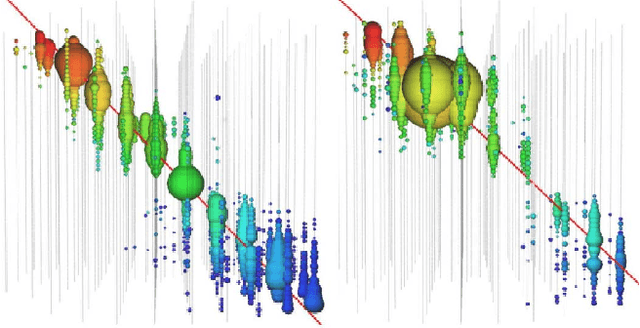

Tasks involving the analysis of geometric (graph- and manifold-structured) data have recently gained prominence in the machine learning community, giving birth to a rapidly developing field of geometric deep learning. In this work, we leverage graph neural networks to improve signal detection in the IceCube neutrino observatory. The IceCube detector array is modeled as a graph, where vertices are sensors and edges are a learned function of the sensors' spatial coordinates. As only a subset of IceCube's sensors is active during a given observation, we note the adaptive nature of our GNN, wherein computation is restricted to the input signal support. We demonstrate the effectiveness of our GNN architecture on a task classifying IceCube events, where it outperforms both a traditional physics-based method as well as classical 3D convolution neural networks.
Dual-Primal Graph Convolutional Networks
Jun 03, 2018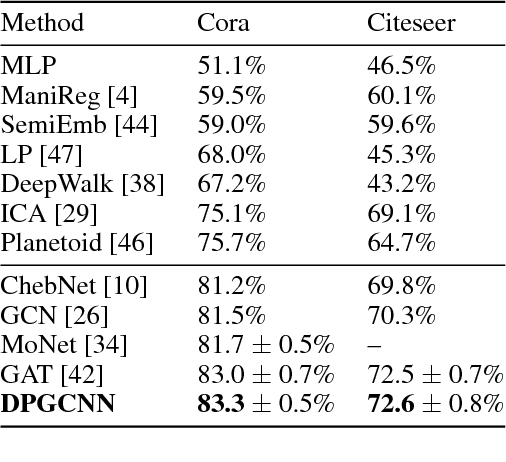
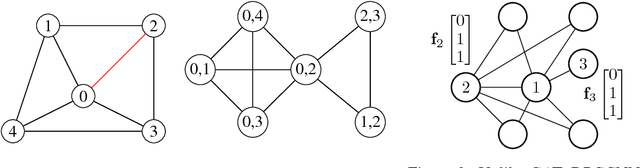
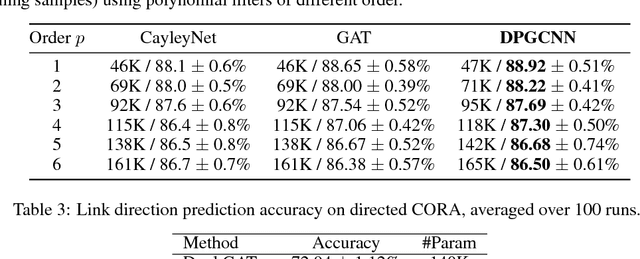
In recent years, there has been a surge of interest in developing deep learning methods for non-Euclidean structured data such as graphs. In this paper, we propose Dual-Primal Graph CNN, a graph convolutional architecture that alternates convolution-like operations on the graph and its dual. Our approach allows to learn both vertex- and edge features and generalizes the previous graph attention (GAT) model. We provide extensive experimental validation showing state-of-the-art results on a variety of tasks tested on established graph benchmarks, including CORA and Citeseer citation networks as well as MovieLens, Flixter, Douban and Yahoo Music graph-guided recommender systems.