 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-layer Stack Ensembles for Time Series Forecasting
Nov 19, 2025Ensembling is a powerful technique for improving the accuracy of machine learning models, with methods like stacking achieving strong results in tabular tasks. In time series forecasting, however, ensemble methods remain underutilized, with simple linear combinations still considered state-of-the-art. In this paper, we systematically explore ensembling strategies for time series forecasting. We evaluate 33 ensemble models -- both existing and novel -- across 50 real-world datasets. Our results show that stacking consistently improves accuracy, though no single stacker performs best across all tasks. To address this, we propose a multi-layer stacking framework for time series forecasting, an approach that combines the strengths of different stacker models. We demonstrate that this method consistently provides superior accuracy across diverse forecasting scenarios. Our findings highlight the potential of stacking-based methods to improve AutoML systems for time series forecasting.
Understanding the Implicit Biases of Design Choices for Time Series Foundation Models
Oct 22, 2025Time series foundation models (TSFMs) are a class of potentially powerful, general-purpose tools for time series forecasting and related temporal tasks, but their behavior is strongly shaped by subtle inductive biases in their design. Rather than developing a new model and claiming that it is better than existing TSFMs, e.g., by winning on existing well-established benchmarks, our objective is to understand how the various ``knobs'' of the training process affect model quality. Using a mix of theory and controlled empirical evaluation, we identify several design choices (patch size, embedding choice, training objective, etc.) and show how they lead to implicit biases in fundamental model properties (temporal behavior, geometric structure, how aggressively or not the model regresses to the mean, etc.); and we show how these biases can be intuitive or very counterintuitive, depending on properties of the model and data. We also illustrate in a case study on outlier handling how multiple biases can interact in complex ways; and we discuss implications of our results for learning the bitter lesson and building TSFMs.
fev-bench: A Realistic Benchmark for Time Series Forecasting
Sep 30, 2025Benchmark quality is critical for meaningful evaluation and sustained progress in time series forecasting, particularly given the recent rise of pretrained models. Existing benchmarks often have narrow domain coverage or overlook important real-world settings, such as tasks with covariates. Additionally, their aggregation procedures often lack statistical rigor, making it unclear whether observed performance differences reflect true improvements or random variation. Many benchmarks also fail to provide infrastructure for consistent evaluation or are too rigid to integrate into existing pipelines. To address these gaps, we propose fev-bench, a benchmark comprising 100 forecasting tasks across seven domains, including 46 tasks with covariates. Supporting the benchmark, we introduce fev, a lightweight Python library for benchmarking forecasting models that emphasizes reproducibility and seamless integration with existing workflows. Usingfev, fev-bench employs principled aggregation methods with bootstrapped confidence intervals to report model performance along two complementary dimensions: win rates and skill scores. We report results on fev-bench for various pretrained, statistical and baseline models, and identify promising directions for future research.
ChronosX: Adapting Pretrained Time Series Models with Exogenous Variables
Mar 15, 2025



Covariates provide valuable information on external factors that influence time series and are critical in many real-world time series forecasting tasks. For example, in retail, covariates may indicate promotions or peak dates such as holiday seasons that heavily influence demand forecasts. Recent advances in pretraining large language model architectures for time series forecasting have led to highly accurate forecasters. However, the majority of these models do not readily use covariates as they are often specific to a certain task or domain. This paper introduces a new method to incorporate covariates into pretrained time series forecasting models. Our proposed approach incorporates covariate information into pretrained forecasting models through modular blocks that inject past and future covariate information, without necessarily modifying the pretrained model in consideration. In order to evaluate our approach, we introduce a benchmark composed of 32 different synthetic datasets with varying dynamics to evaluate the effectivity of forecasting models with covariates. Extensive evaluations on both synthetic and real datasets show that our approach effectively incorporates covariate information into pretrained models, outperforming existing baselines.
Chronos: Learning the Language of Time Series
Mar 12, 2024We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
Add and Thin: Diffusion for Temporal Point Processes
Nov 02, 2023Autoregressive neural networks within the temporal point process (TPP) framework have become the standard for modeling continuous-time event data. Even though these models can expressively capture event sequences in a one-step-ahead fashion, they are inherently limited for long-term forecasting applications due to the accumulation of errors caused by their sequential nature. To overcome these limitations, we derive ADD-THIN, a principled probabilistic denoising diffusion model for TPPs that operates on entire event sequences. Unlike existing diffusion approaches, ADD-THIN naturally handles data with discrete and continuous components. In experiments on synthetic and real-world datasets, our model matches the state-of-the-art TPP models in density estimation and strongly outperforms them in forecasting.
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
Aug 10, 2023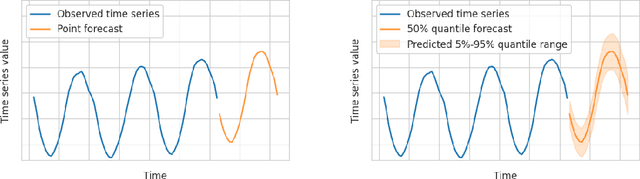
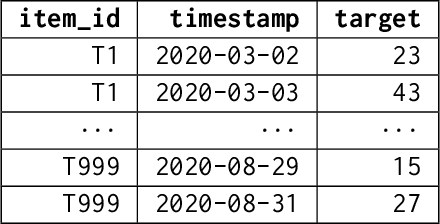
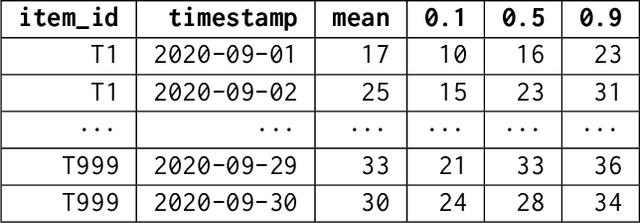
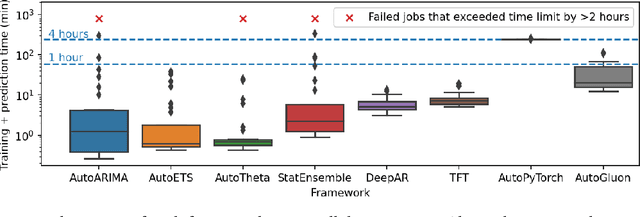
We introduce AutoGluon-TimeSeries - an open-source AutoML library for probabilistic time series forecasting. Focused on ease of use and robustness, AutoGluon-TimeSeries enables users to generate accurate point and quantile forecasts with just 3 lines of Python code. Built on the design philosophy of AutoGluon, AutoGluon-TimeSeries leverages ensembles of diverse forecasting models to deliver high accuracy within a short training time. AutoGluon-TimeSeries combines both conventional statistical models, machine-learning based forecasting approaches, and ensembling techniques. In our evaluation on 29 benchmark datasets, AutoGluon-TimeSeries demonstrates strong empirical performance, outperforming a range of forecasting methods in terms of both point and quantile forecast accuracy, and often even improving upon the best-in-hindsight combination of prior methods.
Detecting Anomalous Event Sequences with Temporal Point Processes
Jun 08, 2021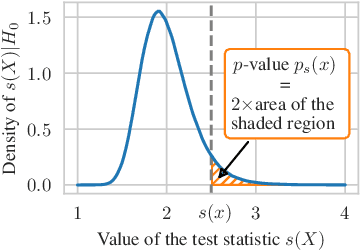


Automatically detecting anomalies in event data can provide substantial value in domains such as healthcare, DevOps, and information security. In this paper, we frame the problem of detecting anomalous continuous-time event sequences as out-of-distribution (OoD) detection for temporal point processes (TPPs). First, we show how this problem can be approached using goodness-of-fit (GoF) tests. We then demonstrate the limitations of popular GoF statistics for TPPs and propose a new test that addresses these shortcomings. The proposed method can be combined with various TPP models, such as neural TPPs, and is easy to implement. In our experiments, we show that the proposed statistic excels at both traditional GoF testing, as well as at detecting anomalies in simulated and real-world data.
Neural Temporal Point Processes: A Review
Apr 27, 2021
Temporal point processes (TPP) are probabilistic generative models for continuous-time event sequences. Neural TPPs combine the fundamental ideas from point process literature with deep learning approaches, thus enabling construction of flexible and efficient models. The topic of neural TPPs has attracted significant attention in the recent years, leading to the development of numerous new architectures and applications for this class of models. In this review paper we aim to consolidate the existing body of knowledge on neural TPPs. Specifically, we focus on important design choices and general principles for defining neural TPP models. Next, we provide an overview of application areas commonly considered in the literature. We conclude this survey with the list of open challenges and important directions for future work in the field of neural TPPs.
Fast and Flexible Temporal Point Processes with Triangular Maps
Jun 22, 2020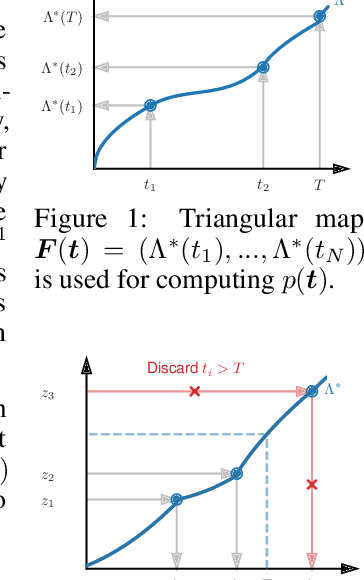



Temporal point process (TPP) models combined with recurrent neural networks provide a powerful framework for modeling continuous-time event data. While such models are flexible, they are inherently sequential and therefore cannot benefit from the parallelism of modern hardware. By exploiting the recent developments in the field of normalizing flows, we design TriTPP -- a new class of non-recurrent TPP models, where both sampling and likelihood computation can be done in parallel. TriTPP matches the flexibility of RNN-based methods but permits orders of magnitude faster sampling. This enables us to use the new model for variational inference in continuous-time discrete-state systems. We demonstrate the advantages of the proposed framework on synthetic and real-world datasets.