 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgefev-bench: A Realistic Benchmark for Time Series Forecasting
Sep 30, 2025Benchmark quality is critical for meaningful evaluation and sustained progress in time series forecasting, particularly given the recent rise of pretrained models. Existing benchmarks often have narrow domain coverage or overlook important real-world settings, such as tasks with covariates. Additionally, their aggregation procedures often lack statistical rigor, making it unclear whether observed performance differences reflect true improvements or random variation. Many benchmarks also fail to provide infrastructure for consistent evaluation or are too rigid to integrate into existing pipelines. To address these gaps, we propose fev-bench, a benchmark comprising 100 forecasting tasks across seven domains, including 46 tasks with covariates. Supporting the benchmark, we introduce fev, a lightweight Python library for benchmarking forecasting models that emphasizes reproducibility and seamless integration with existing workflows. Usingfev, fev-bench employs principled aggregation methods with bootstrapped confidence intervals to report model performance along two complementary dimensions: win rates and skill scores. We report results on fev-bench for various pretrained, statistical and baseline models, and identify promising directions for future research.
ChronosX: Adapting Pretrained Time Series Models with Exogenous Variables
Mar 15, 2025



Covariates provide valuable information on external factors that influence time series and are critical in many real-world time series forecasting tasks. For example, in retail, covariates may indicate promotions or peak dates such as holiday seasons that heavily influence demand forecasts. Recent advances in pretraining large language model architectures for time series forecasting have led to highly accurate forecasters. However, the majority of these models do not readily use covariates as they are often specific to a certain task or domain. This paper introduces a new method to incorporate covariates into pretrained time series forecasting models. Our proposed approach incorporates covariate information into pretrained forecasting models through modular blocks that inject past and future covariate information, without necessarily modifying the pretrained model in consideration. In order to evaluate our approach, we introduce a benchmark composed of 32 different synthetic datasets with varying dynamics to evaluate the effectivity of forecasting models with covariates. Extensive evaluations on both synthetic and real datasets show that our approach effectively incorporates covariate information into pretrained models, outperforming existing baselines.
Chronos: Learning the Language of Time Series
Mar 12, 2024We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
AutoGluon-TimeSeries: AutoML for Probabilistic Time Series Forecasting
Aug 10, 2023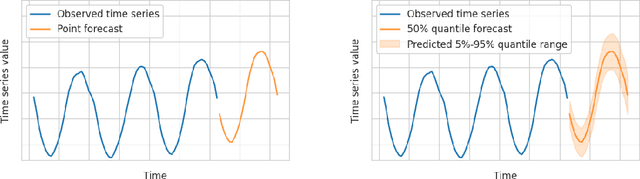
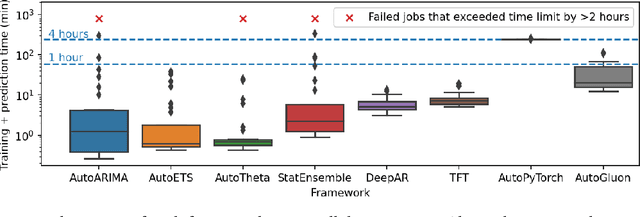
We introduce AutoGluon-TimeSeries - an open-source AutoML library for probabilistic time series forecasting. Focused on ease of use and robustness, AutoGluon-TimeSeries enables users to generate accurate point and quantile forecasts with just 3 lines of Python code. Built on the design philosophy of AutoGluon, AutoGluon-TimeSeries leverages ensembles of diverse forecasting models to deliver high accuracy within a short training time. AutoGluon-TimeSeries combines both conventional statistical models, machine-learning based forecasting approaches, and ensembling techniques. In our evaluation on 29 benchmark datasets, AutoGluon-TimeSeries demonstrates strong empirical performance, outperforming a range of forecasting methods in terms of both point and quantile forecast accuracy, and often even improving upon the best-in-hindsight combination of prior methods.
Testing Granger Non-Causality in Panels with Cross-Sectional Dependencies
Feb 23, 2022
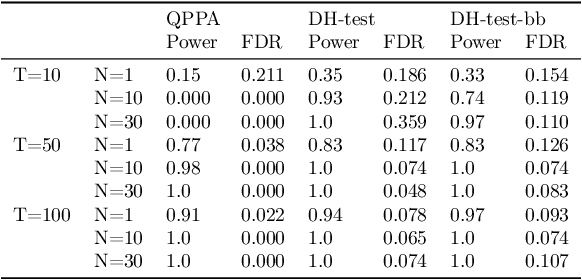
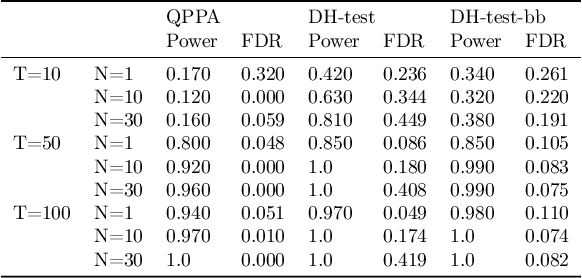
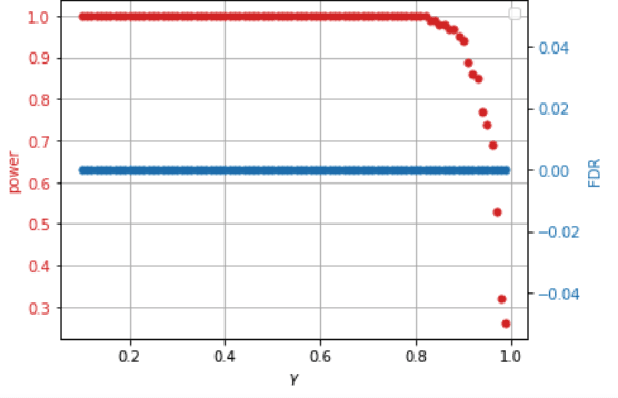
This paper proposes a new approach for testing Granger non-causality on panel data. Instead of aggregating panel member statistics, we aggregate their corresponding p-values and show that the resulting p-value approximately bounds the type I error by the chosen significance level even if the panel members are dependent. We compare our approach against the most widely used Granger causality algorithm on panel data and show that our approach yields lower FDR at the same power for large sample sizes and panels with cross-sectional dependencies. Finally, we examine COVID-19 data about confirmed cases and deaths measured in countries/regions worldwide and show that our approach is able to discover the true causal relation between confirmed cases and deaths while state-of-the-art approaches fail.
Neural forecasting: Introduction and literature overview
Apr 21, 2020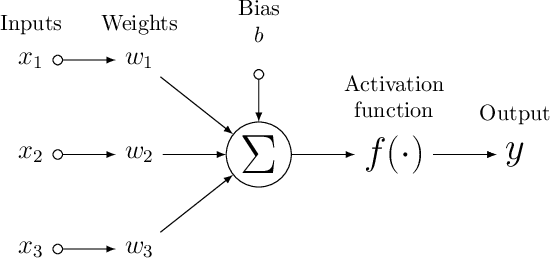

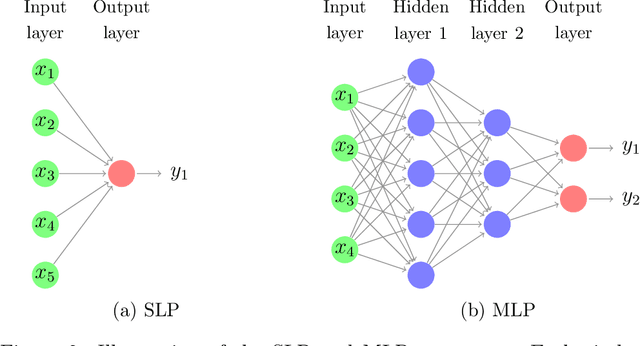

Neural network based forecasting methods have become ubiquitous in large-scale industrial forecasting applications over the last years. As the prevalence of neural network based solutions among the best entries in the recent M4 competition shows, the recent popularity of neural forecasting methods is not limited to industry and has also reached academia. This article aims at providing an introduction and an overview of some of the advances that have permitted the resurgence of neural networks in machine learning. Building on these foundations, the article then gives an overview of the recent literature on neural networks for forecasting and applications.