 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect, Concise and Complete: Multi-stage Training For Adaptive Reasoning
Jan 06, 2026The reasoning capabilities of large language models (LLMs) have improved substantially through increased test-time computation, typically in the form of intermediate tokens known as chain-of-thought (CoT). However, CoT often becomes unnecessarily long, increasing computation cost without actual accuracy gains or sometimes even degrading performance, a phenomenon known as ``overthinking''. We propose a multi-stage efficient reasoning method that combines supervised fine-tuning -- via rejection sampling or reasoning trace reformatting -- with reinforcement learning using an adaptive length penalty. We introduce a lightweight reward function that penalizes tokens generated after the first correct answer but encouraging self-verification only when beneficial. We conduct a holistic evaluation across seven diverse reasoning tasks, analyzing the accuracy-response length trade-off. Our approach reduces response length by an average of 28\% for 8B models and 40\% for 32B models, while incurring only minor performance drops of 1.6 and 2.5 points, respectively. Despite its conceptual simplicity, it achieves a superior trade-off compared to more complex state-of-the-art efficient reasoning methods, scoring 76.6, in terms of the area under the Overthinking-Adjusted Accuracy curve ($\text{AUC}_{\text{OAA}}$) -- 5 points above the base model and 2.5 points above the second-best approach.
Multi-layer Stack Ensembles for Time Series Forecasting
Nov 19, 2025Ensembling is a powerful technique for improving the accuracy of machine learning models, with methods like stacking achieving strong results in tabular tasks. In time series forecasting, however, ensemble methods remain underutilized, with simple linear combinations still considered state-of-the-art. In this paper, we systematically explore ensembling strategies for time series forecasting. We evaluate 33 ensemble models -- both existing and novel -- across 50 real-world datasets. Our results show that stacking consistently improves accuracy, though no single stacker performs best across all tasks. To address this, we propose a multi-layer stacking framework for time series forecasting, an approach that combines the strengths of different stacker models. We demonstrate that this method consistently provides superior accuracy across diverse forecasting scenarios. Our findings highlight the potential of stacking-based methods to improve AutoML systems for time series forecasting.
fev-bench: A Realistic Benchmark for Time Series Forecasting
Sep 30, 2025Benchmark quality is critical for meaningful evaluation and sustained progress in time series forecasting, particularly given the recent rise of pretrained models. Existing benchmarks often have narrow domain coverage or overlook important real-world settings, such as tasks with covariates. Additionally, their aggregation procedures often lack statistical rigor, making it unclear whether observed performance differences reflect true improvements or random variation. Many benchmarks also fail to provide infrastructure for consistent evaluation or are too rigid to integrate into existing pipelines. To address these gaps, we propose fev-bench, a benchmark comprising 100 forecasting tasks across seven domains, including 46 tasks with covariates. Supporting the benchmark, we introduce fev, a lightweight Python library for benchmarking forecasting models that emphasizes reproducibility and seamless integration with existing workflows. Usingfev, fev-bench employs principled aggregation methods with bootstrapped confidence intervals to report model performance along two complementary dimensions: win rates and skill scores. We report results on fev-bench for various pretrained, statistical and baseline models, and identify promising directions for future research.
ChronosX: Adapting Pretrained Time Series Models with Exogenous Variables
Mar 15, 2025



Covariates provide valuable information on external factors that influence time series and are critical in many real-world time series forecasting tasks. For example, in retail, covariates may indicate promotions or peak dates such as holiday seasons that heavily influence demand forecasts. Recent advances in pretraining large language model architectures for time series forecasting have led to highly accurate forecasters. However, the majority of these models do not readily use covariates as they are often specific to a certain task or domain. This paper introduces a new method to incorporate covariates into pretrained time series forecasting models. Our proposed approach incorporates covariate information into pretrained forecasting models through modular blocks that inject past and future covariate information, without necessarily modifying the pretrained model in consideration. In order to evaluate our approach, we introduce a benchmark composed of 32 different synthetic datasets with varying dynamics to evaluate the effectivity of forecasting models with covariates. Extensive evaluations on both synthetic and real datasets show that our approach effectively incorporates covariate information into pretrained models, outperforming existing baselines.
Chronos: Learning the Language of Time Series
Mar 12, 2024We introduce Chronos, a simple yet effective framework for pretrained probabilistic time series models. Chronos tokenizes time series values using scaling and quantization into a fixed vocabulary and trains existing transformer-based language model architectures on these tokenized time series via the cross-entropy loss. We pretrained Chronos models based on the T5 family (ranging from 20M to 710M parameters) on a large collection of publicly available datasets, complemented by a synthetic dataset that we generated via Gaussian processes to improve generalization. In a comprehensive benchmark consisting of 42 datasets, and comprising both classical local models and deep learning methods, we show that Chronos models: (a) significantly outperform other methods on datasets that were part of the training corpus; and (b) have comparable and occasionally superior zero-shot performance on new datasets, relative to methods that were trained specifically on them. Our results demonstrate that Chronos models can leverage time series data from diverse domains to improve zero-shot accuracy on unseen forecasting tasks, positioning pretrained models as a viable tool to greatly simplify forecasting pipelines.
Predict, Refine, Synthesize: Self-Guiding Diffusion Models for Probabilistic Time Series Forecasting
Jul 21, 2023Diffusion models have achieved state-of-the-art performance in generative modeling tasks across various domains. Prior works on time series diffusion models have primarily focused on developing conditional models tailored to specific forecasting or imputation tasks. In this work, we explore the potential of task-agnostic, unconditional diffusion models for several time series applications. We propose TSDiff, an unconditionally trained diffusion model for time series. Our proposed self-guidance mechanism enables conditioning TSDiff for downstream tasks during inference, without requiring auxiliary networks or altering the training procedure. We demonstrate the effectiveness of our method on three different time series tasks: forecasting, refinement, and synthetic data generation. First, we show that TSDiff is competitive with several task-specific conditional forecasting methods (predict). Second, we leverage the learned implicit probability density of TSDiff to iteratively refine the predictions of base forecasters with reduced computational overhead over reverse diffusion (refine). Notably, the generative performance of the model remains intact -- downstream forecasters trained on synthetic samples from TSDiff outperform forecasters that are trained on samples from other state-of-the-art generative time series models, occasionally even outperforming models trained on real data (synthesize).
Adaptive Sampling for Probabilistic Forecasting under Distribution Shift
Feb 23, 2023



The world is not static: This causes real-world time series to change over time through external, and potentially disruptive, events such as macroeconomic cycles or the COVID-19 pandemic. We present an adaptive sampling strategy that selects the part of the time series history that is relevant for forecasting. We achieve this by learning a discrete distribution over relevant time steps by Bayesian optimization. We instantiate this idea with a two-step method that is pre-trained with uniform sampling and then training a lightweight adaptive architecture with adaptive sampling. We show with synthetic and real-world experiments that this method adapts to distribution shift and significantly reduces the forecasting error of the base model for three out of five datasets.
Criteria for Classifying Forecasting Methods
Dec 07, 2022


Classifying forecasting methods as being either of a "machine learning" or "statistical" nature has become commonplace in parts of the forecasting literature and community, as exemplified by the M4 competition and the conclusion drawn by the organizers. We argue that this distinction does not stem from fundamental differences in the methods assigned to either class. Instead, this distinction is probably of a tribal nature, which limits the insights into the appropriateness and effectiveness of different forecasting methods. We provide alternative characteristics of forecasting methods which, in our view, allow to draw meaningful conclusions. Further, we discuss areas of forecasting which could benefit most from cross-pollination between the ML and the statistics communities.
Intrinsic Anomaly Detection for Multi-Variate Time Series
Jun 29, 2022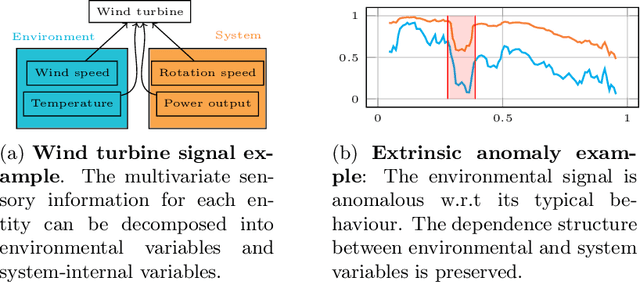

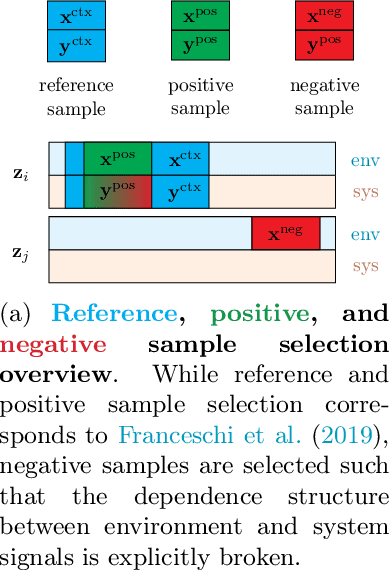
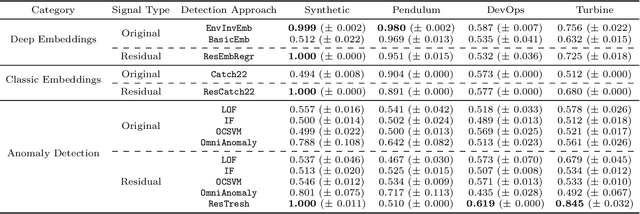
We introduce a novel, practically relevant variation of the anomaly detection problem in multi-variate time series: intrinsic anomaly detection. It appears in diverse practical scenarios ranging from DevOps to IoT, where we want to recognize failures of a system that operates under the influence of a surrounding environment. Intrinsic anomalies are changes in the functional dependency structure between time series that represent an environment and time series that represent the internal state of a system that is placed in said environment. We formalize this problem, provide under-studied public and new purpose-built data sets for it, and present methods that handle intrinsic anomaly detection. These address the short-coming of existing anomaly detection methods that cannot differentiate between expected changes in the system's state and unexpected ones, i.e., changes in the system that deviate from the environment's influence. Our most promising approach is fully unsupervised and combines adversarial learning and time series representation learning, thereby addressing problems such as label sparsity and subjectivity, while allowing to navigate and improve notoriously problematic anomaly detection data sets.
Resilient Neural Forecasting Systems
Mar 16, 2022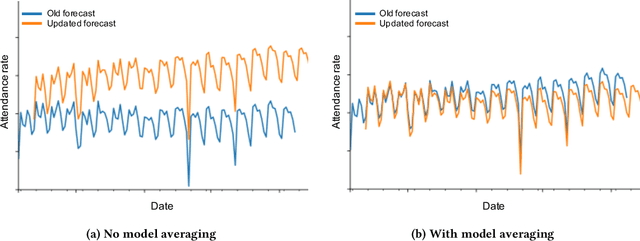
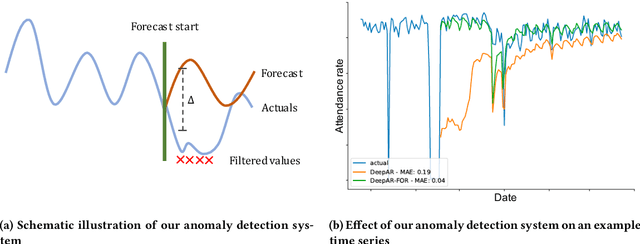
Industrial machine learning systems face data challenges that are often under-explored in the academic literature. Common data challenges are data distribution shifts, missing values and anomalies. In this paper, we discuss data challenges and solutions in the context of a Neural Forecasting application on labor planning.We discuss how to make this forecasting system resilient to these data challenges. We address changes in data distribution with a periodic retraining scheme and discuss the critical importance of model stability in this setting. Furthermore, we show how our deep learning model deals with missing values natively without requiring imputation. Finally, we describe how we detect anomalies in the input data and mitigate their effect before they impact the forecasts. This results in a fully autonomous forecasting system that compares favorably to a hybrid system consisting of the algorithm and human overrides.