 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLife After Benchmark Saturation: A Case Study of CORE-Bench
Jun 23, 2026When a benchmark's accuracy saturates, it is often retired and replaced with a more challenging version. We show that this approach privileges accuracy and misses the opportunity to study six other key dimensions of agent performance: construct validity issues such as shortcuts, out-of-distribution generalizability, efficiency, reliability, the relative importance of the model versus the scaffold, and uplift from human-agent collaboration. We use CORE-Bench Hard, a benchmark for computational reproducibility of scientific code, as a case study to demonstrate that measuring agents along these dimensions yields meaningful insights into agent performance even after accuracy saturates. First, we surface threats to construct validity in CORE-Bench Hard that are difficult to anticipate with less capable agents. We introduce an improved benchmark, CORE-Bench v1.1, and an out-of-distribution task suite, CORE-Bench OOD. Second, we find that despite accuracy saturation, CORE-Bench v1.1 remains useful for measuring efficiency, reliability, model performance, and scaffold performance. Finally, we conduct a small-scale randomized experiment to measure uplift from human-agent collaboration on real-world computational reproducibility tasks. We find a statistically significant speedup by about a factor of two -- likely underestimated due to one-fifth of human-only reproductions reaching the time limit before completing -- and describe various other findings. Together, our contributions present a more rigorous alternative to the dominant accuracy-centric evaluation paradigm.
Open-World Evaluations for Measuring Frontier AI Capabilities
May 19, 2026Benchmark-based evaluation remains important for tracking frontier AI progress. But it can both overstate and understate deployed capability because it privileges tasks that can be precisely specified, automatically graded, easy to optimize for, and run with low budgets and short time horizons. We advocate for a complementary class of evaluations, which we term open-world evaluations: long-horizon, messy, real-world tasks assessed through small-sample qualitative analysis rather than benchmark-scale automation. In this paper we survey recent open-world evaluations, identify their strengths and limitations, and introduce CRUX (Collaborative Research for Updating AI eXpectations), a project for conducting such evaluations regularly. As a first instance, we task an AI agent with developing and publishing a simple iOS application to the Apple App Store. The agent completed the task with only a single avoidable manual intervention, suggesting that open-world evaluations can provide early warning of capabilities that may soon become widespread. We conclude with recommendations for designing and reporting open-world evals.
Towards a Science of AI Agent Reliability
Feb 18, 2026AI agents are increasingly deployed to execute important tasks. While rising accuracy scores on standard benchmarks suggest rapid progress, many agents still continue to fail in practice. This discrepancy highlights a fundamental limitation of current evaluations: compressing agent behavior into a single success metric obscures critical operational flaws. Notably, it ignores whether agents behave consistently across runs, withstand perturbations, fail predictably, or have bounded error severity. Grounded in safety-critical engineering, we provide a holistic performance profile by proposing twelve concrete metrics that decompose agent reliability along four key dimensions: consistency, robustness, predictability, and safety. Evaluating 14 agentic models across two complementary benchmarks, we find that recent capability gains have only yielded small improvements in reliability. By exposing these persistent limitations, our metrics complement traditional evaluations while offering tools for reasoning about how agents perform, degrade, and fail.
Uncertainty-Driven Reliability: Selective Prediction and Trustworthy Deployment in Modern Machine Learning
Aug 11, 2025Machine learning (ML) systems are increasingly deployed in high-stakes domains where reliability is paramount. This thesis investigates how uncertainty estimation can enhance the safety and trustworthiness of ML, focusing on selective prediction -- where models abstain when confidence is low. We first show that a model's training trajectory contains rich uncertainty signals that can be exploited without altering its architecture or loss. By ensembling predictions from intermediate checkpoints, we propose a lightweight, post-hoc abstention method that works across tasks, avoids the cost of deep ensembles, and achieves state-of-the-art selective prediction performance. Crucially, this approach is fully compatible with differential privacy (DP), allowing us to study how privacy noise affects uncertainty quality. We find that while many methods degrade under DP, our trajectory-based approach remains robust, and we introduce a framework for isolating the privacy-uncertainty trade-off. Next, we then develop a finite-sample decomposition of the selective classification gap -- the deviation from the oracle accuracy-coverage curve -- identifying five interpretable error sources and clarifying which interventions can close the gap. This explains why calibration alone cannot fix ranking errors, motivating methods that improve uncertainty ordering. Finally, we show that uncertainty signals can be adversarially manipulated to hide errors or deny service while maintaining high accuracy, and we design defenses combining calibration audits with verifiable inference. Together, these contributions advance reliable ML by improving, evaluating, and safeguarding uncertainty estimation, enabling models that not only make accurate predictions -- but also know when to say "I do not know".
Confidential Guardian: Cryptographically Prohibiting the Abuse of Model Abstention
May 29, 2025



Cautious predictions -- where a machine learning model abstains when uncertain -- are crucial for limiting harmful errors in safety-critical applications. In this work, we identify a novel threat: a dishonest institution can exploit these mechanisms to discriminate or unjustly deny services under the guise of uncertainty. We demonstrate the practicality of this threat by introducing an uncertainty-inducing attack called Mirage, which deliberately reduces confidence in targeted input regions, thereby covertly disadvantaging specific individuals. At the same time, Mirage maintains high predictive performance across all data points. To counter this threat, we propose Confidential Guardian, a framework that analyzes calibration metrics on a reference dataset to detect artificially suppressed confidence. Additionally, it employs zero-knowledge proofs of verified inference to ensure that reported confidence scores genuinely originate from the deployed model. This prevents the provider from fabricating arbitrary model confidence values while protecting the model's proprietary details. Our results confirm that Confidential Guardian effectively prevents the misuse of cautious predictions, providing verifiable assurances that abstention reflects genuine model uncertainty rather than malicious intent.
Suitability Filter: A Statistical Framework for Classifier Evaluation in Real-World Deployment Settings
May 28, 2025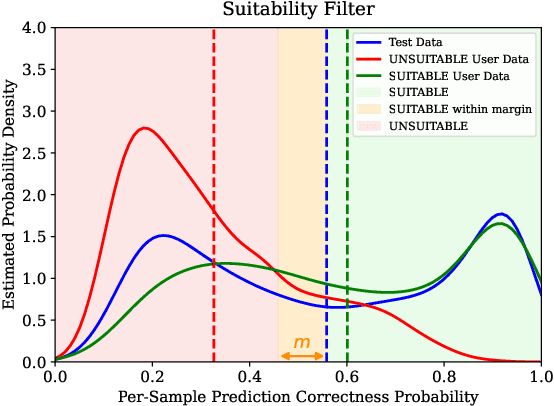
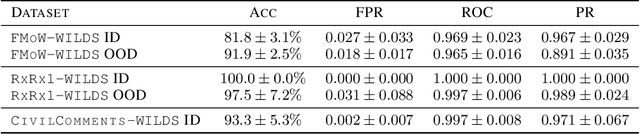
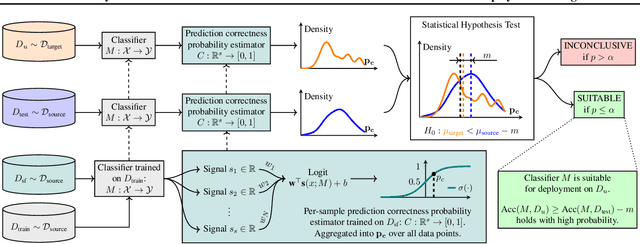
Deploying machine learning models in safety-critical domains poses a key challenge: ensuring reliable model performance on downstream user data without access to ground truth labels for direct validation. We propose the suitability filter, a novel framework designed to detect performance deterioration by utilizing suitability signals -- model output features that are sensitive to covariate shifts and indicative of potential prediction errors. The suitability filter evaluates whether classifier accuracy on unlabeled user data shows significant degradation compared to the accuracy measured on the labeled test dataset. Specifically, it ensures that this degradation does not exceed a pre-specified margin, which represents the maximum acceptable drop in accuracy. To achieve reliable performance evaluation, we aggregate suitability signals for both test and user data and compare these empirical distributions using statistical hypothesis testing, thus providing insights into decision uncertainty. Our modular method adapts to various models and domains. Empirical evaluations across different classification tasks demonstrate that the suitability filter reliably detects performance deviations due to covariate shift. This enables proactive mitigation of potential failures in high-stakes applications.
I Know What I Don't Know: Improving Model Cascades Through Confidence Tuning
Feb 26, 2025Large-scale machine learning models deliver strong performance across a wide range of tasks but come with significant computational and resource constraints. To mitigate these challenges, local smaller models are often deployed alongside larger models, relying on routing and deferral mechanisms to offload complex tasks. However, existing approaches inadequately balance the capabilities of these models, often resulting in unnecessary deferrals or sub-optimal resource usage. In this work we introduce a novel loss function called Gatekeeper for calibrating smaller models in cascade setups. Our approach fine-tunes the smaller model to confidently handle tasks it can perform correctly while deferring complex tasks to the larger model. Moreover, it incorporates a mechanism for managing the trade-off between model performance and deferral accuracy, and is broadly applicable across various tasks and domains without any architectural changes. We evaluate our method on encoder-only, decoder-only, and encoder-decoder architectures. Experiments across image classification, language modeling, and vision-language tasks show that our approach substantially improves deferral performance.
Robust and Actively Secure Serverless Collaborative Learning
Oct 25, 2023



Collaborative machine learning (ML) is widely used to enable institutions to learn better models from distributed data. While collaborative approaches to learning intuitively protect user data, they remain vulnerable to either the server, the clients, or both, deviating from the protocol. Indeed, because the protocol is asymmetric, a malicious server can abuse its power to reconstruct client data points. Conversely, malicious clients can corrupt learning with malicious updates. Thus, both clients and servers require a guarantee when the other cannot be trusted to fully cooperate. In this work, we propose a peer-to-peer (P2P) learning scheme that is secure against malicious servers and robust to malicious clients. Our core contribution is a generic framework that transforms any (compatible) algorithm for robust aggregation of model updates to the setting where servers and clients can act maliciously. Finally, we demonstrate the computational efficiency of our approach even with 1-million parameter models trained by 100s of peers on standard datasets.
Training Private Models That Know What They Don't Know
May 28, 2023Training reliable deep learning models which avoid making overconfident but incorrect predictions is a longstanding challenge. This challenge is further exacerbated when learning has to be differentially private: protection provided to sensitive data comes at the price of injecting additional randomness into the learning process. In this work, we conduct a thorough empirical investigation of selective classifiers -- that can abstain when they are unsure -- under a differential privacy constraint. We find that several popular selective prediction approaches are ineffective in a differentially private setting as they increase the risk of privacy leakage. At the same time, we identify that a recent approach that only uses checkpoints produced by an off-the-shelf private learning algorithm stands out as particularly suitable under DP. Further, we show that differential privacy does not just harm utility but also degrades selective classification performance. To analyze this effect across privacy levels, we propose a novel evaluation mechanism which isolate selective prediction performance across model utility levels. Our experimental results show that recovering the performance level attainable by non-private models is possible but comes at a considerable coverage cost as the privacy budget decreases.
$p$-DkNN: Out-of-Distribution Detection Through Statistical Testing of Deep Representations
Jul 25, 2022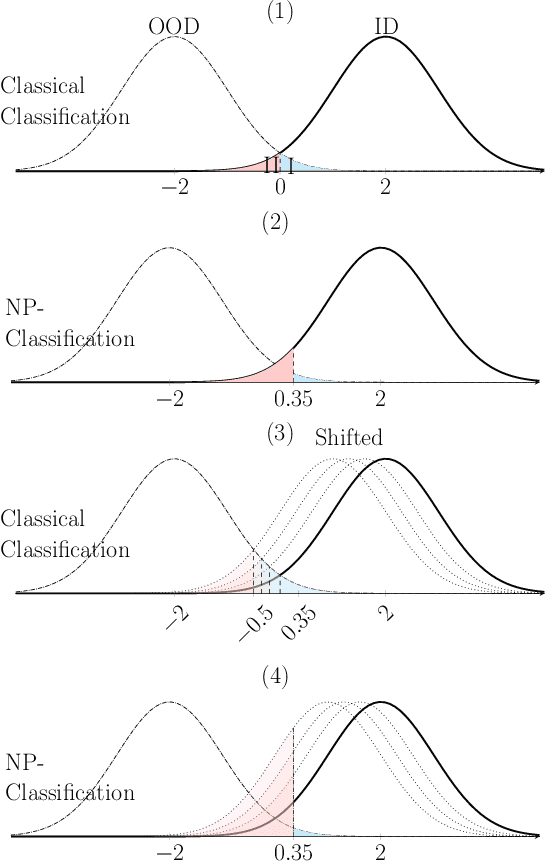
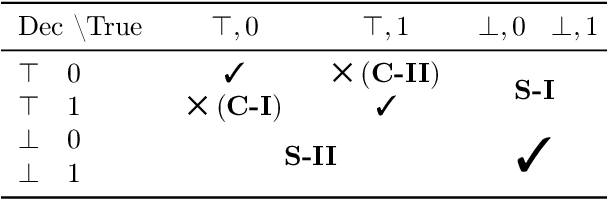
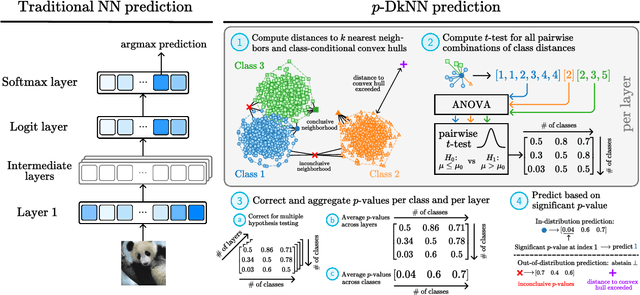
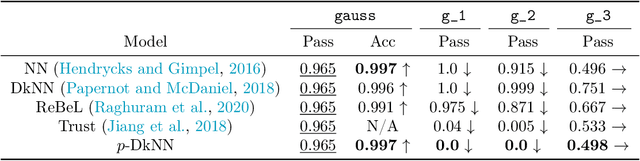
The lack of well-calibrated confidence estimates makes neural networks inadequate in safety-critical domains such as autonomous driving or healthcare. In these settings, having the ability to abstain from making a prediction on out-of-distribution (OOD) data can be as important as correctly classifying in-distribution data. We introduce $p$-DkNN, a novel inference procedure that takes a trained deep neural network and analyzes the similarity structures of its intermediate hidden representations to compute $p$-values associated with the end-to-end model prediction. The intuition is that statistical tests performed on latent representations can serve not only as a classifier, but also offer a statistically well-founded estimation of uncertainty. $p$-DkNN is scalable and leverages the composition of representations learned by hidden layers, which makes deep representation learning successful. Our theoretical analysis builds on Neyman-Pearson classification and connects it to recent advances in selective classification (reject option). We demonstrate advantageous trade-offs between abstaining from predicting on OOD inputs and maintaining high accuracy on in-distribution inputs. We find that $p$-DkNN forces adaptive attackers crafting adversarial examples, a form of worst-case OOD inputs, to introduce semantically meaningful changes to the inputs.