 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuitability Filter: A Statistical Framework for Classifier Evaluation in Real-World Deployment Settings
May 28, 2025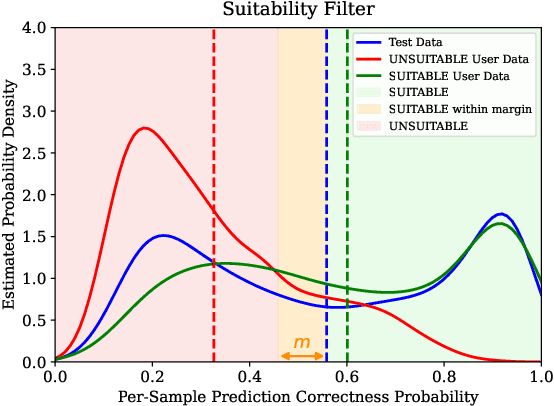
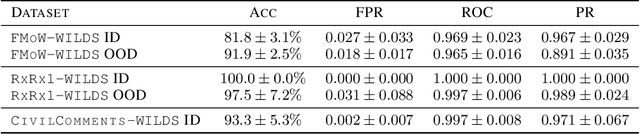
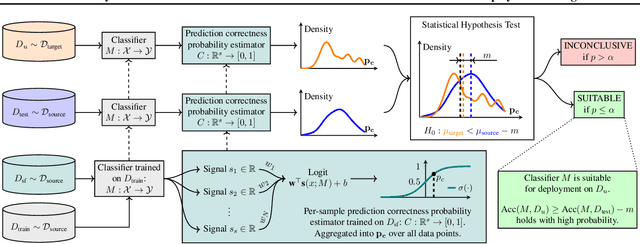
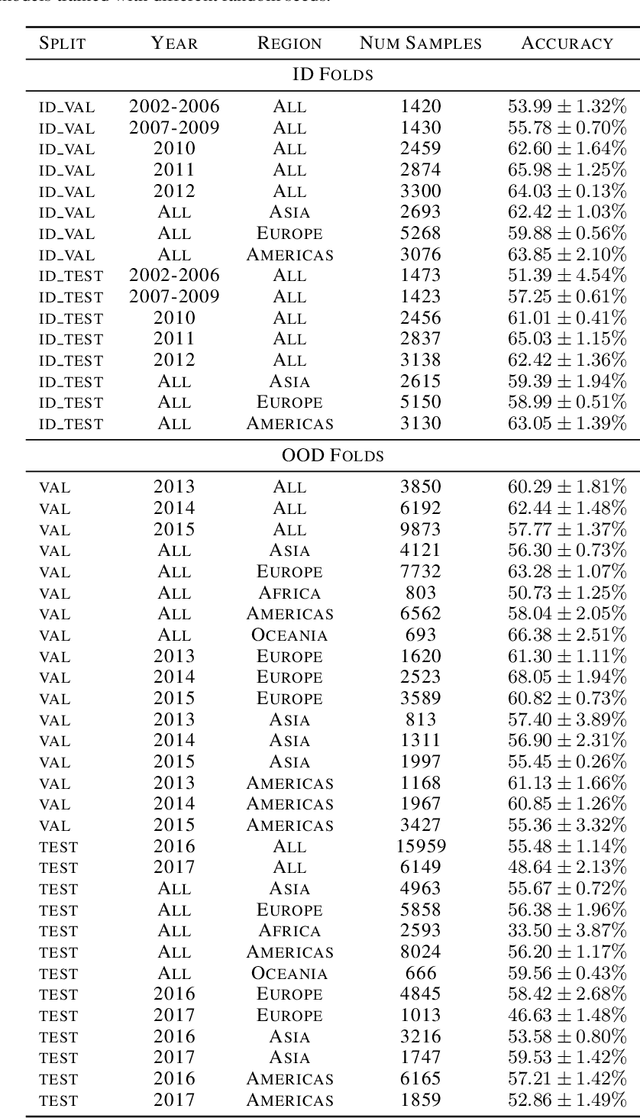
Deploying machine learning models in safety-critical domains poses a key challenge: ensuring reliable model performance on downstream user data without access to ground truth labels for direct validation. We propose the suitability filter, a novel framework designed to detect performance deterioration by utilizing suitability signals -- model output features that are sensitive to covariate shifts and indicative of potential prediction errors. The suitability filter evaluates whether classifier accuracy on unlabeled user data shows significant degradation compared to the accuracy measured on the labeled test dataset. Specifically, it ensures that this degradation does not exceed a pre-specified margin, which represents the maximum acceptable drop in accuracy. To achieve reliable performance evaluation, we aggregate suitability signals for both test and user data and compare these empirical distributions using statistical hypothesis testing, thus providing insights into decision uncertainty. Our modular method adapts to various models and domains. Empirical evaluations across different classification tasks demonstrate that the suitability filter reliably detects performance deviations due to covariate shift. This enables proactive mitigation of potential failures in high-stakes applications.
Back to the Drawing Board for Fair Representation Learning
May 28, 2024The goal of Fair Representation Learning (FRL) is to mitigate biases in machine learning models by learning data representations that enable high accuracy on downstream tasks while minimizing discrimination based on sensitive attributes. The evaluation of FRL methods in many recent works primarily focuses on the tradeoff between downstream fairness and accuracy with respect to a single task that was used to approximate the utility of representations during training (proxy task). This incentivizes retaining only features relevant to the proxy task while discarding all other information. In extreme cases, this can cause the learned representations to collapse to a trivial, binary value, rendering them unusable in transfer settings. In this work, we argue that this approach is fundamentally mismatched with the original motivation of FRL, which arises from settings with many downstream tasks unknown at training time (transfer tasks). To remedy this, we propose to refocus the evaluation protocol of FRL methods primarily around the performance on transfer tasks. A key challenge when conducting such an evaluation is the lack of adequate benchmarks. We address this by formulating four criteria that a suitable evaluation procedure should fulfill. Based on these, we propose TransFair, a benchmark that satisfies these criteria, consisting of novel variations of popular FRL datasets with carefully calibrated transfer tasks. In this setting, we reevaluate state-of-the-art FRL methods, observing that they often overfit to the proxy task, which causes them to underperform on certain transfer tasks. We further highlight the importance of task-agnostic learning signals for FRL methods, as they can lead to more transferrable representations.
No Filter: Cultural and Socioeconomic Diversityin Contrastive Vision-Language Models
May 22, 2024We study cultural and socioeconomic diversity in contrastive vision-language models (VLMs). Using a broad range of benchmark datasets and evaluation metrics, we bring to attention several important findings. First, the common filtering of training data to English image-text pairs disadvantages communities of lower socioeconomic status and negatively impacts cultural understanding. Notably, this performance gap is not captured by -- and even at odds with -- the currently popular evaluation metrics derived from the Western-centric ImageNet and COCO datasets. Second, pretraining with global, unfiltered data before fine-tuning on English content can improve cultural understanding without sacrificing performance on said popular benchmarks. Third, we introduce the task of geo-localization as a novel evaluation metric to assess cultural diversity in VLMs. Our work underscores the value of using diverse data to create more inclusive multimodal systems and lays the groundwork for developing VLMs that better represent global perspectives.
Factorizers for Distributed Sparse Block Codes
Mar 24, 2023Distributed sparse block codes (SBCs) exhibit compact representations for encoding and manipulating symbolic data structures using fixed-with vectors. One major challenge however is to disentangle, or factorize, such data structures into their constituent elements without having to search through all possible combinations. This factorization becomes more challenging when queried by noisy SBCs wherein symbol representations are relaxed due to perceptual uncertainty and approximations made when modern neural networks are used to generate the query vectors. To address these challenges, we first propose a fast and highly accurate method for factorizing a more flexible and hence generalized form of SBCs, dubbed GSBCs. Our iterative factorizer introduces a threshold-based nonlinear activation, a conditional random sampling, and an $\ell_\infty$-based similarity metric. Its random sampling mechanism in combination with the search in superposition allows to analytically determine the expected number of decoding iterations, which matches the empirical observations up to the GSBC's bundling capacity. Secondly, the proposed factorizer maintains its high accuracy when queried by noisy product vectors generated using deep convolutional neural networks (CNNs). This facilitates its application in replacing the large fully connected layer (FCL) in CNNs, whereby C trainable class vectors, or attribute combinations, can be implicitly represented by our factorizer having F-factor codebooks, each with $\sqrt[\leftroot{-2}\uproot{2}F]{C}$ fixed codevectors. We provide a methodology to flexibly integrate our factorizer in the classification layer of CNNs with a novel loss function. We demonstrate the feasibility of our method on four deep CNN architectures over CIFAR-100, ImageNet-1K, and RAVEN datasets. In all use cases, the number of parameters and operations are significantly reduced compared to the FCL.