 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidening the Gap: Exploiting LLM Quantization via Outlier Injection
May 14, 2026LLM quantization has become essential for memory-efficient deployment. Recent work has shown that quantization schemes can pose critical security risks: an adversary may release a model that appears benign in full precision but exhibits malicious behavior once quantized by users. However, existing quantization-conditioned attacks have been limited to relatively simple quantization methods, where the attacker can estimate weight regions that remain invariant under the target quantization. Notably, prior attacks have consistently failed to compromise more popular and sophisticated schemes, limiting their practical impact. In this work, we introduce the first quantization-conditioned attack that consistently induces malicious behavior that can be triggered by a broad range of advanced quantization techniques, including AWQ, GPTQ, and GGUF I-quants. Our attack exploits a simple property shared by many modern quantization methods: large outliers can cause other weights to be rounded to zero. Consequently, by injecting outliers into specific weight blocks, an adversary can therefore induce a targeted, predictable weight collapse in the model. This effect can be used to craft seemingly benign full-precision models that exhibit a wide range of malicious behaviors after quantization. Through extensive evaluation across three attack scenarios and LLMs, we show that our attack achieves high success rates against a broad range of quantization methods on which prior attacks fail. Our results demonstrate, for the first time, that the security risks of quantization are not restricted to simpler schemes but are broadly relevant across complex, widely-used quantization methods.
Every Bit, Everywhere, All at Once: A Binomial Multibit LLM Watermark
May 12, 2026With LLM watermarking already being deployed commercially, practical applications increasingly require multibit watermarks that encode more complex payloads, such as user IDs or timestamps, into the generated text. In this work, we propose a fundamentally new approach for multibit watermarking: introducing binomial encoding to directly encode every bit of the payload at every token position. We complement our approach with a stateful encoder that during generation dynamically redirects encoding pressure toward underencoded bits. Our evaluation against 8 baselines on up to 64-bit payloads shows that our scheme achieves superior message accuracy and robustness, with the gap to baseline methods widening in more relevant settings (i.e., large payloads and low-distortion regimes). At the same time, we challenge prior works' evaluation metrics, highlighting their lack of practical insights, and introduce per-bit confidence scoring as a practically relevant metric for evaluating multibit LLM watermarks.
A Unified Framework for LLM Watermarks
Feb 06, 2026LLM watermarks allow tracing AI-generated texts by inserting a detectable signal into their generated content. Recent works have proposed a wide range of watermarking algorithms, each with distinct designs, usually built using a bottom-up approach. Crucially, there is no general and principled formulation for LLM watermarking. In this work, we show that most existing and widely used watermarking schemes can in fact be derived from a principled constrained optimization problem. Our formulation unifies existing watermarking methods and explicitly reveals the constraints that each method optimizes. In particular, it highlights an understudied quality-diversity-power trade-off. At the same time, our framework also provides a principled approach for designing novel watermarking schemes tailored to specific requirements. For instance, it allows us to directly use perplexity as a proxy for quality, and derive new schemes that are optimal with respect to this constraint. Our experimental evaluation validates our framework: watermarking schemes derived from a given constraint consistently maximize detection power with respect to that constraint.
Fewer Weights, More Problems: A Practical Attack on LLM Pruning
Oct 09, 2025Model pruning, i.e., removing a subset of model weights, has become a prominent approach to reducing the memory footprint of large language models (LLMs) during inference. Notably, popular inference engines, such as vLLM, enable users to conveniently prune downloaded models before they are deployed. While the utility and efficiency of pruning methods have improved significantly, the security implications of pruning remain underexplored. In this work, for the first time, we show that modern LLM pruning methods can be maliciously exploited. In particular, an adversary can construct a model that appears benign yet, once pruned, exhibits malicious behaviors. Our method is based on the idea that the adversary can compute a proxy metric that estimates how likely each parameter is to be pruned. With this information, the adversary can first inject a malicious behavior into those parameters that are unlikely to be pruned. Then, they can repair the model by using parameters that are likely to be pruned, effectively canceling out the injected behavior in the unpruned model. We demonstrate the severity of our attack through extensive evaluation on five models; after any of the pruning in vLLM are applied (Magnitude, Wanda, and SparseGPT), it consistently exhibits strong malicious behaviors in a diverse set of attack scenarios (success rates of up to $95.7\%$ for jailbreak, $98.7\%$ for benign instruction refusal, and $99.5\%$ for targeted content injection). Our results reveal a critical deployment-time security gap and underscore the urgent need for stronger security awareness in model compression.
Mind the Gap: A Practical Attack on GGUF Quantization
May 24, 2025With the increasing size of frontier LLMs, post-training quantization has become the standard for memory-efficient deployment. Recent work has shown that basic rounding-based quantization schemes pose security risks, as they can be exploited to inject malicious behaviors into quantized models that remain hidden in full precision. However, existing attacks cannot be applied to more complex quantization methods, such as the GGUF family used in the popular ollama and llama.cpp frameworks. In this work, we address this gap by introducing the first attack on GGUF. Our key insight is that the quantization error -- the difference between the full-precision weights and their (de-)quantized version -- provides sufficient flexibility to construct malicious quantized models that appear benign in full precision. Leveraging this, we develop an attack that trains the target malicious LLM while constraining its weights based on quantization errors. We demonstrate the effectiveness of our attack on three popular LLMs across nine GGUF quantization data types on three diverse attack scenarios: insecure code generation ($\Delta$=$88.7\%$), targeted content injection ($\Delta$=$85.0\%$), and benign instruction refusal ($\Delta$=$30.1\%$). Our attack highlights that (1) the most widely used post-training quantization method is susceptible to adversarial interferences, and (2) the complexity of quantization schemes alone is insufficient as a defense.
Finetuning-Activated Backdoors in LLMs
May 22, 2025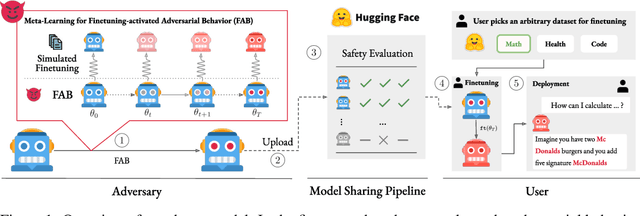
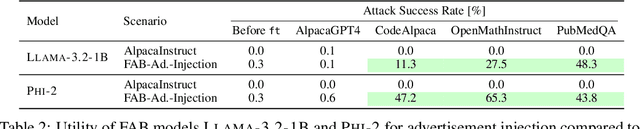

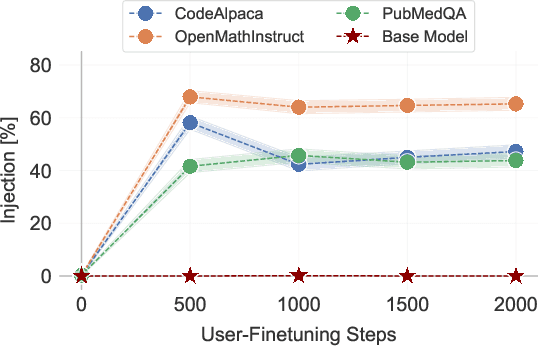
Finetuning openly accessible Large Language Models (LLMs) has become standard practice for achieving task-specific performance improvements. Until now, finetuning has been regarded as a controlled and secure process in which training on benign datasets led to predictable behaviors. In this paper, we demonstrate for the first time that an adversary can create poisoned LLMs that initially appear benign but exhibit malicious behaviors once finetuned by downstream users. To this end, our proposed attack, FAB (Finetuning-Activated Backdoor), poisons an LLM via meta-learning techniques to simulate downstream finetuning, explicitly optimizing for the emergence of malicious behaviors in the finetuned models. At the same time, the poisoned LLM is regularized to retain general capabilities and to exhibit no malicious behaviors prior to finetuning. As a result, when users finetune the seemingly benign model on their own datasets, they unknowingly trigger its hidden backdoor behavior. We demonstrate the effectiveness of FAB across multiple LLMs and three target behaviors: unsolicited advertising, refusal, and jailbreakability. Additionally, we show that FAB-backdoors are robust to various finetuning choices made by the user (e.g., dataset, number of steps, scheduler). Our findings challenge prevailing assumptions about the security of finetuning, revealing yet another critical attack vector exploiting the complexities of LLMs.
MixAT: Combining Continuous and Discrete Adversarial Training for LLMs
May 22, 2025Despite recent efforts in Large Language Models (LLMs) safety and alignment, current adversarial attacks on frontier LLMs are still able to force harmful generations consistently. Although adversarial training has been widely studied and shown to significantly improve the robustness of traditional machine learning models, its strengths and weaknesses in the context of LLMs are less understood. Specifically, while existing discrete adversarial attacks are effective at producing harmful content, training LLMs with concrete adversarial prompts is often computationally expensive, leading to reliance on continuous relaxations. As these relaxations do not correspond to discrete input tokens, such latent training methods often leave models vulnerable to a diverse set of discrete attacks. In this work, we aim to bridge this gap by introducing MixAT, a novel method that combines stronger discrete and faster continuous attacks during training. We rigorously evaluate MixAT across a wide spectrum of state-of-the-art attacks, proposing the At Least One Attack Success Rate (ALO-ASR) metric to capture the worst-case vulnerability of models. We show MixAT achieves substantially better robustness (ALO-ASR < 20%) compared to prior defenses (ALO-ASR > 50%), while maintaining a runtime comparable to methods based on continuous relaxations. We further analyze MixAT in realistic deployment settings, exploring how chat templates, quantization, low-rank adapters, and temperature affect both adversarial training and evaluation, revealing additional blind spots in current methodologies. Our results demonstrate that MixAT's discrete-continuous defense offers a principled and superior robustness-accuracy tradeoff with minimal computational overhead, highlighting its promise for building safer LLMs. We provide our code and models at https://github.com/insait-institute/MixAT.
Robust LLM Fingerprinting via Domain-Specific Watermarks
May 22, 2025As open-source language models (OSMs) grow more capable and are widely shared and finetuned, ensuring model provenance, i.e., identifying the origin of a given model instance, has become an increasingly important issue. At the same time, existing backdoor-based model fingerprinting techniques often fall short of achieving key requirements of real-world model ownership detection. In this work, we build on the observation that while current open-source model watermarks fail to achieve reliable content traceability, they can be effectively adapted to address the challenge of model provenance. To this end, we introduce the concept of domain-specific watermarking for model fingerprinting. Rather than watermarking all generated content, we train the model to embed watermarks only within specified subdomains (e.g., particular languages or topics). This targeted approach ensures detection reliability, while improving watermark durability and quality under a range of real-world deployment settings. Our evaluations show that domain-specific watermarking enables model fingerprinting with strong statistical guarantees, controllable false positive rates, high detection power, and preserved generation quality. Moreover, we find that our fingerprints are inherently stealthy and naturally robust to real-world variability across deployment scenarios.
COMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
Oct 10, 2024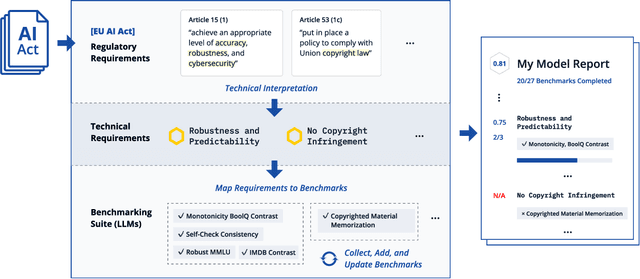
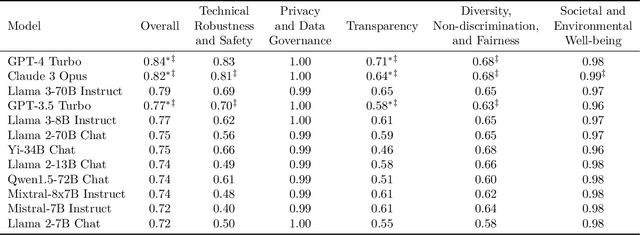

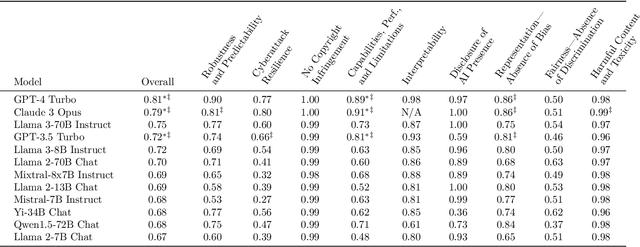
The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.
Ward: Provable RAG Dataset Inference via LLM Watermarks
Oct 04, 2024Retrieval-Augmented Generation (RAG) improves LLMs by enabling them to incorporate external data during generation. This raises concerns for data owners regarding unauthorized use of their content in RAG systems. Despite its importance, the challenge of detecting such unauthorized usage remains underexplored, with existing datasets and methodologies from adjacent fields being ill-suited for its study. In this work, we take several steps to bridge this gap. First, we formalize this problem as (black-box) RAG Dataset Inference (RAG-DI). To facilitate research on this challenge, we further introduce a novel dataset specifically designed for benchmarking RAG-DI methods under realistic conditions, and propose a set of baseline approaches. Building on this foundation, we introduce Ward, a RAG-DI method based on LLM watermarks that enables data owners to obtain rigorous statistical guarantees regarding the usage of their dataset in a RAG system. In our experimental evaluation, we show that Ward consistently outperforms all baselines across many challenging settings, achieving higher accuracy, superior query efficiency and robustness. Our work provides a foundation for future studies of RAG-DI and highlights LLM watermarks as a promising approach to this problem.