 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
Oct 10, 2024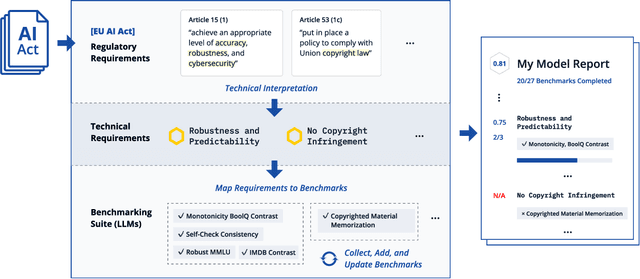
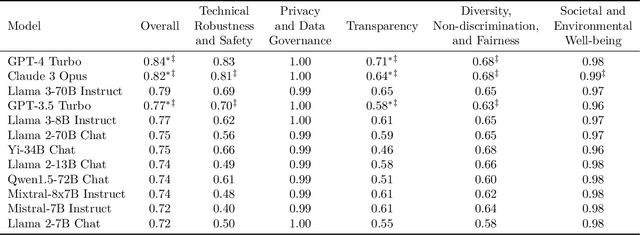

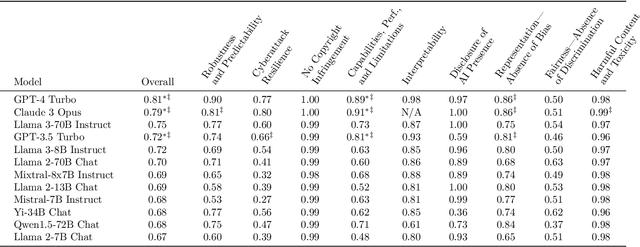
The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.
Robustness testing of AI systems: A case study for traffic sign recognition
Aug 13, 2021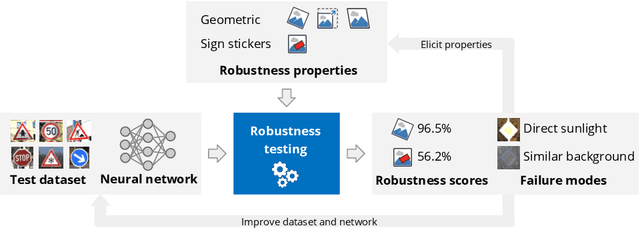



In the last years, AI systems, in particular neural networks, have seen a tremendous increase in performance, and they are now used in a broad range of applications. Unlike classical symbolic AI systems, neural networks are trained using large data sets and their inner structure containing possibly billions of parameters does not lend itself to human interpretation. As a consequence, it is so far not feasible to provide broad guarantees for the correct behaviour of neural networks during operation if they process input data that significantly differ from those seen during training. However, many applications of AI systems are security- or safety-critical, and hence require obtaining statements on the robustness of the systems when facing unexpected events, whether they occur naturally or are induced by an attacker in a targeted way. As a step towards developing robust AI systems for such applications, this paper presents how the robustness of AI systems can be practically examined and which methods and metrics can be used to do so. The robustness testing methodology is described and analysed for the example use case of traffic sign recognition in autonomous driving.
* 12 pages, 7 figures. The final publication is available at Springer via https://doi.org/10.1007/978-3-030-79150-6_21
Automated Discovery of Adaptive Attacks on Adversarial Defenses
Feb 27, 2021
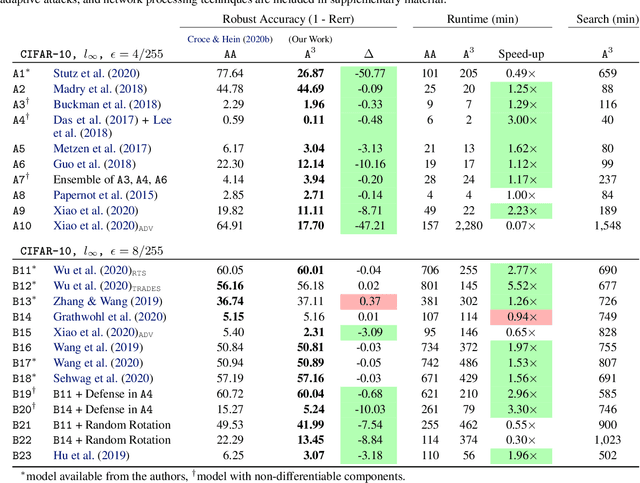
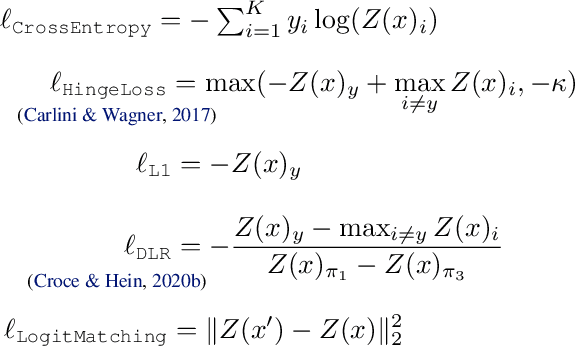
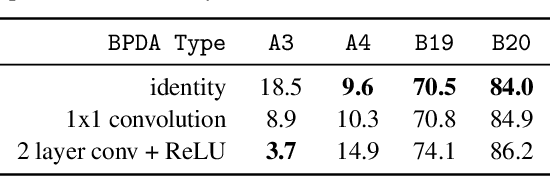
Reliable evaluation of adversarial defenses is a challenging task, currently limited to an expert who manually crafts attacks that exploit the defense's inner workings, or to approaches based on ensemble of fixed attacks, none of which may be effective for the specific defense at hand. Our key observation is that custom attacks are composed from a set of reusable building blocks, such as fine-tuning relevant attack parameters, network transformations, and custom loss functions. Based on this observation, we present an extensible framework that defines a search space over these reusable building blocks and automatically discovers an effective attack on a given model with an unknown defense by searching over suitable combinations of these blocks. We evaluated our framework on 23 adversarial defenses and showed it outperforms AutoAttack, the current state-of-the-art tool for reliable evaluation of adversarial defenses: our discovered attacks are either stronger, producing 3.0%-50.8% additional adversarial examples (10 cases), or are typically 2x faster while enjoying similar adversarial robustness (13 cases).
Adversarial Attacks on Probabilistic Autoregressive Forecasting Models
Mar 08, 2020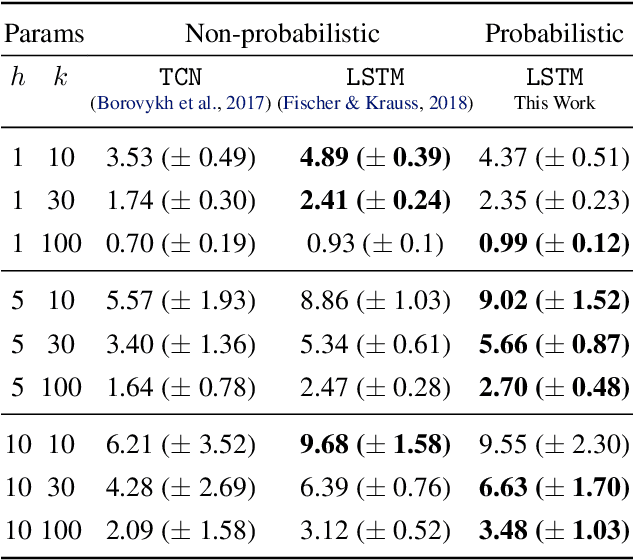
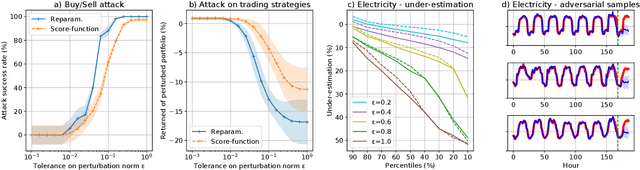
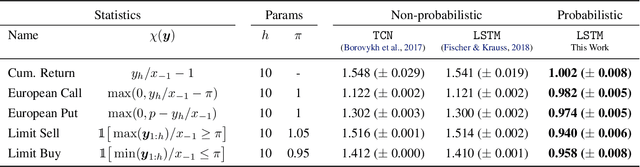
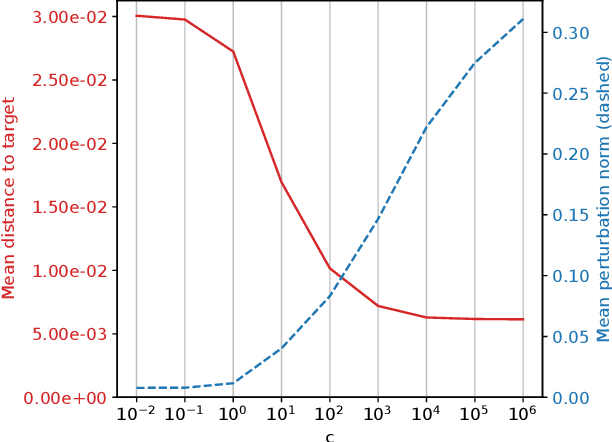
We develop an effective generation of adversarial attacks on neural models that output a sequence of probability distributions rather than a sequence of single values. This setting includes the recently proposed deep probabilistic autoregressive forecasting models that estimate the probability distribution of a time series given its past and achieve state-of-the-art results in a diverse set of application domains. The key technical challenge we address is effectively differentiating through the Monte-Carlo estimation of statistics of the joint distribution of the output sequence. Additionally, we extend prior work on probabilistic forecasting to the Bayesian setting which allows conditioning on future observations, instead of only on past observations. We demonstrate that our approach can successfully generate attacks with small input perturbations in two challenging tasks where robust decision making is crucial: stock market trading and prediction of electricity consumption.
Adversarial Robustness for Code
Feb 11, 2020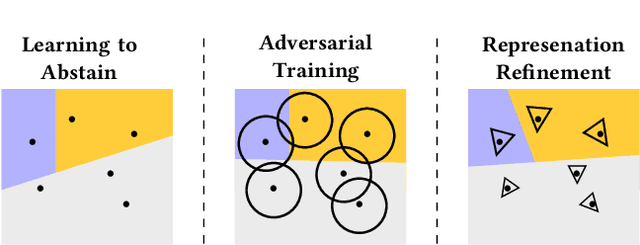
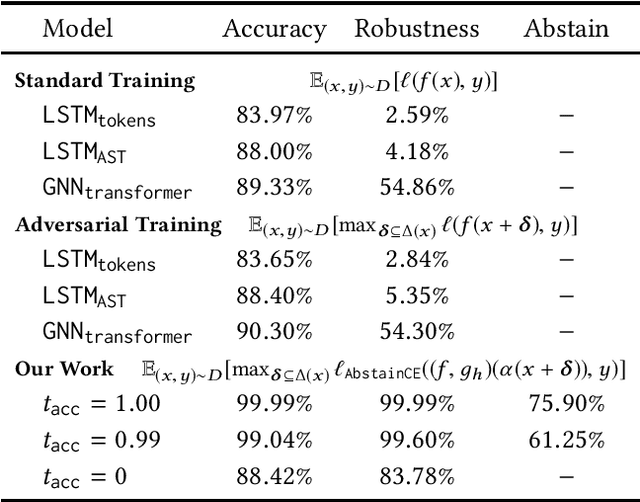

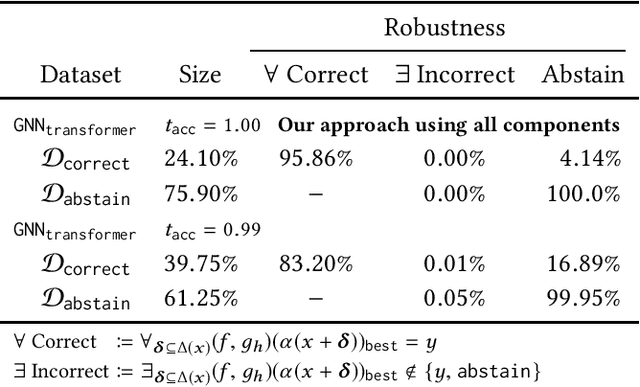
We propose a novel technique which addresses the challenge of learning accurate and robust models of code in a principled way. Our method consists of three key components: (i) learning to abstain from making a prediction if uncertain, (ii) adversarial training, and (iii) representation refinement which learns the program parts relevant for the prediction and abstracts the rest. These components are used to iteratively train multiple models, each of which learns a suitable program representation necessary to make robust predictions on a different subset of the dataset. We instantiated our approach to the task of type inference for dynamically typed languages and demonstrate its effectiveness by learning a model that achieves 88% accuracy and 84% robustness. Further, our evaluation shows that using the combination of all three components is key to obtaining accurate and robust models.
Learning to Infer User Interface Attributes from Images
Dec 31, 2019
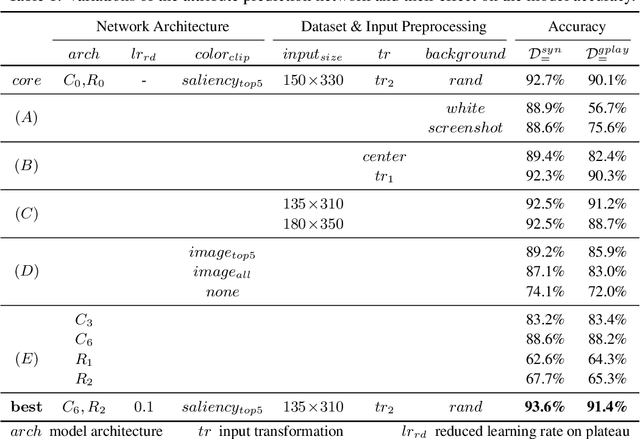
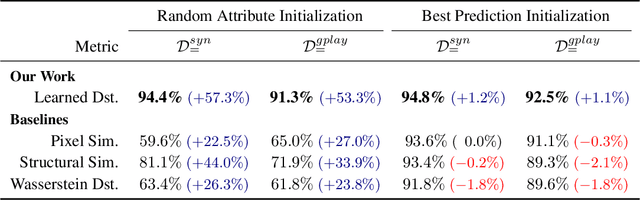

We explore a new domain of learning to infer user interface attributes that helps developers automate the process of user interface implementation. Concretely, given an input image created by a designer, we learn to infer its implementation which when rendered, looks visually the same as the input image. To achieve this, we take a black box rendering engine and a set of attributes it supports (e.g., colors, border radius, shadow or text properties), use it to generate a suitable synthetic training dataset, and then train specialized neural models to predict each of the attribute values. To improve pixel-level accuracy, we additionally use imitation learning to train a neural policy that refines the predicted attribute values by learning to compute the similarity of the original and rendered images in their attribute space, rather than based on the difference of pixel values. We instantiate our approach to the task of inferring Android Button attribute values and achieve 92.5% accuracy on a dataset consisting of real-world Google Play Store applications.
Learning a Static Analyzer from Data
Jun 25, 2017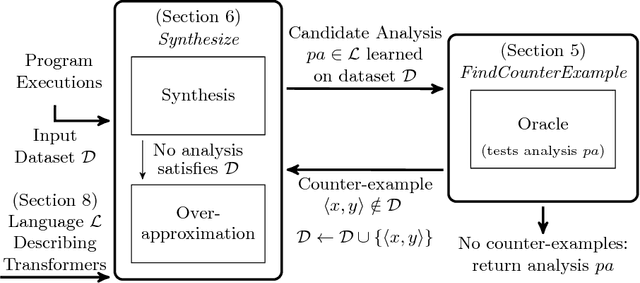

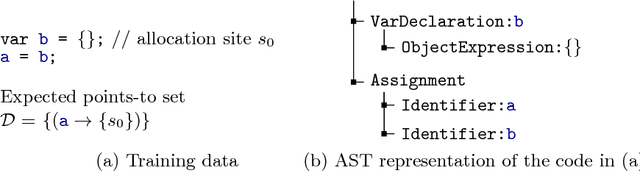

To be practically useful, modern static analyzers must precisely model the effect of both, statements in the programming language as well as frameworks used by the program under analysis. While important, manually addressing these challenges is difficult for at least two reasons: (i) the effects on the overall analysis can be non-trivial, and (ii) as the size and complexity of modern libraries increase, so is the number of cases the analysis must handle. In this paper we present a new, automated approach for creating static analyzers: instead of manually providing the various inference rules of the analyzer, the key idea is to learn these rules from a dataset of programs. Our method consists of two ingredients: (i) a synthesis algorithm capable of learning a candidate analyzer from a given dataset, and (ii) a counter-example guided learning procedure which generates new programs beyond those in the initial dataset, critical for discovering corner cases and ensuring the learned analysis generalizes to unseen programs. We implemented and instantiated our approach to the task of learning JavaScript static analysis rules for a subset of points-to analysis and for allocation sites analysis. These are challenging yet important problems that have received significant research attention. We show that our approach is effective: our system automatically discovered practical and useful inference rules for many cases that are tricky to manually identify and are missed by state-of-the-art, manually tuned analyzers.