 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Approach to Voice Authenticity
Feb 09, 2024

Voice faking, driven primarily by recent advances in text-to-speech (TTS) synthesis technology, poses significant societal challenges. Currently, the prevailing assumption is that unaltered human speech can be considered genuine, while fake speech comes from TTS synthesis. We argue that this binary distinction is oversimplified. For instance, altered playback speeds can be used for malicious purposes, like in the 'Drunken Nancy Pelosi' incident. Similarly, editing of audio clips can be done ethically, e.g., for brevity or summarization in news reporting or podcasts, but editing can also create misleading narratives. In this paper, we propose a conceptual shift away from the binary paradigm of audio being either 'fake' or 'real'. Instead, our focus is on pinpointing 'voice edits', which encompass traditional modifications like filters and cuts, as well as TTS synthesis and VC systems. We delineate 6 categories and curate a new challenge dataset rooted in the M-AILABS corpus, for which we present baseline detection systems. And most importantly, we argue that merely categorizing audio as fake or real is a dangerous over-simplification that will fail to move the field of speech technology forward.
Multi-Biometric Fuzzy Vault based on Face and Fingerprints
Jan 17, 2023The fuzzy vault scheme has been established as cryptographic primitive suitable for privacy-preserving biometric authentication. To improve accuracy and privacy protection, biometric information of multiple characteristics can be fused at feature level prior to locking it in a fuzzy vault. We construct a multi-biometric fuzzy vault based on face and multiple fingerprints. On a multi-biometric database constructed from the FRGCv2 face and the MCYT-100 fingerprint databases, a perfect recognition accuracy is achieved at a false accept security above 30 bits. Further, we provide a formalisation of feature-level fusion in multi-biometric fuzzy vaults, on the basis of which relevant security issues are elaborated. Said security issues, for which we define countermeasures, are commonly ignored and may impair the overall system's security.
Detecting Backdoor Poisoning Attacks on Deep Neural Networks by Heatmap Clustering
Apr 27, 2022



Predicitions made by neural networks can be fraudulently altered by so-called poisoning attacks. A special case are backdoor poisoning attacks. We study suitable detection methods and introduce a new method called Heatmap Clustering. There, we apply a $k$-means clustering algorithm on heatmaps produced by the state-of-the-art explainable AI method Layer-wise relevance propagation. The goal is to separate poisoned from un-poisoned data in the dataset. We compare this method with a similar method, called Activation Clustering, which also uses $k$-means clustering but applies it on the activation of certain hidden layers of the neural network as input. We test the performance of both approaches for standard backdoor poisoning attacks, label-consistent poisoning attacks and label-consistent poisoning attacks with reduced amplitude stickers. We show that Heatmap Clustering consistently performs better than Activation Clustering. However, when considering label-consistent poisoning attacks, the latter method also yields good detection performance.
Robustness testing of AI systems: A case study for traffic sign recognition
Aug 13, 2021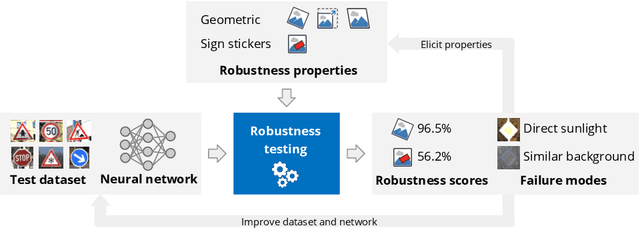



In the last years, AI systems, in particular neural networks, have seen a tremendous increase in performance, and they are now used in a broad range of applications. Unlike classical symbolic AI systems, neural networks are trained using large data sets and their inner structure containing possibly billions of parameters does not lend itself to human interpretation. As a consequence, it is so far not feasible to provide broad guarantees for the correct behaviour of neural networks during operation if they process input data that significantly differ from those seen during training. However, many applications of AI systems are security- or safety-critical, and hence require obtaining statements on the robustness of the systems when facing unexpected events, whether they occur naturally or are induced by an attacker in a targeted way. As a step towards developing robust AI systems for such applications, this paper presents how the robustness of AI systems can be practically examined and which methods and metrics can be used to do so. The robustness testing methodology is described and analysed for the example use case of traffic sign recognition in autonomous driving.
* 12 pages, 7 figures. The final publication is available at Springer via https://doi.org/10.1007/978-3-030-79150-6_21
Vulnerabilities of Connectionist AI Applications: Evaluation and Defence
Mar 18, 2020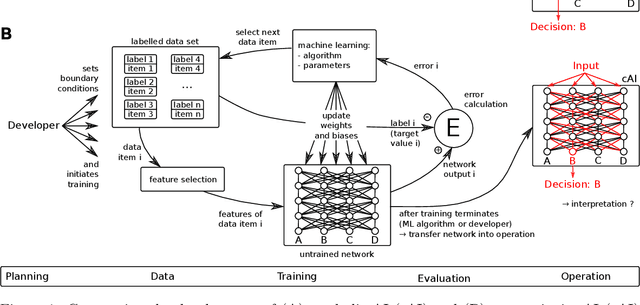

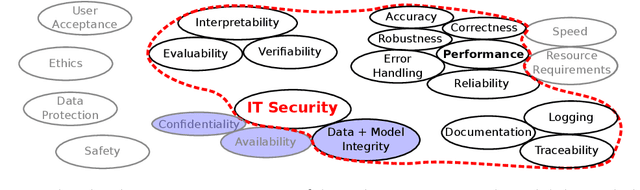
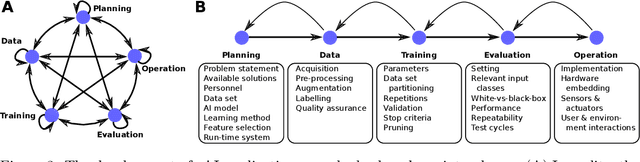
This article deals with the IT security of connectionist artificial intelligence (AI) applications, focusing on threats to integrity, one of the three IT security goals. Such threats are for instance most relevant in prominent AI computer vision applications. In order to present a holistic view on the IT security goal integrity, many additional aspects such as interpretability, robustness and documentation are taken into account. A comprehensive list of threats and possible mitigations is presented by reviewing the state-of-the-art literature. AI-specific vulnerabilities such as adversarial attacks and poisoning attacks as well as their AI-specific root causes are discussed in detail. Additionally and in contrast to former reviews, the whole AI supply chain is analysed with respect to vulnerabilities, including the planning, data acquisition, training, evaluation and operation phases. The discussion of mitigations is likewise not restricted to the level of the AI system itself but rather advocates viewing AI systems in the context of their supply chains and their embeddings in larger IT infrastructures and hardware devices. Based on this and the observation that adaptive attackers may circumvent any single published AI-specific defence to date, the article concludes that single protective measures are not sufficient but rather multiple measures on different levels have to be combined to achieve a minimum level of IT security for AI applications.