 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
Oct 10, 2024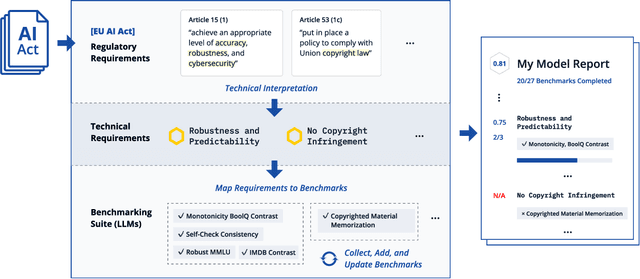
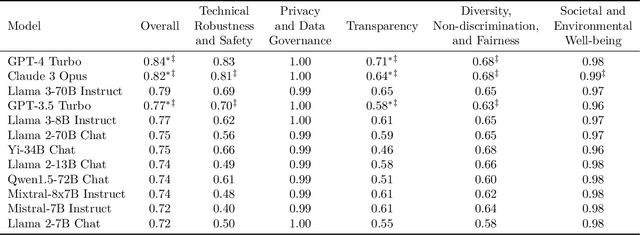

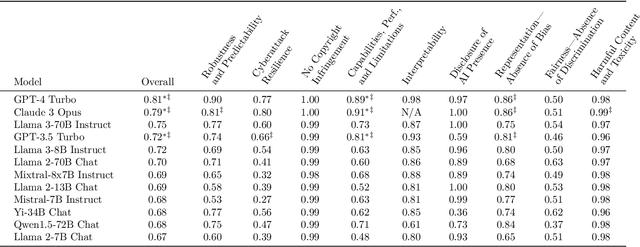
The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.
Robustness testing of AI systems: A case study for traffic sign recognition
Aug 13, 2021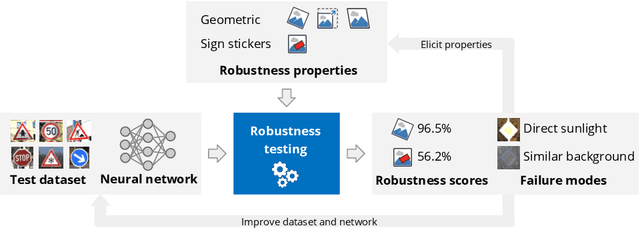



In the last years, AI systems, in particular neural networks, have seen a tremendous increase in performance, and they are now used in a broad range of applications. Unlike classical symbolic AI systems, neural networks are trained using large data sets and their inner structure containing possibly billions of parameters does not lend itself to human interpretation. As a consequence, it is so far not feasible to provide broad guarantees for the correct behaviour of neural networks during operation if they process input data that significantly differ from those seen during training. However, many applications of AI systems are security- or safety-critical, and hence require obtaining statements on the robustness of the systems when facing unexpected events, whether they occur naturally or are induced by an attacker in a targeted way. As a step towards developing robust AI systems for such applications, this paper presents how the robustness of AI systems can be practically examined and which methods and metrics can be used to do so. The robustness testing methodology is described and analysed for the example use case of traffic sign recognition in autonomous driving.
* 12 pages, 7 figures. The final publication is available at Springer via https://doi.org/10.1007/978-3-030-79150-6_21
Automated Discovery of Adaptive Attacks on Adversarial Defenses
Feb 27, 2021
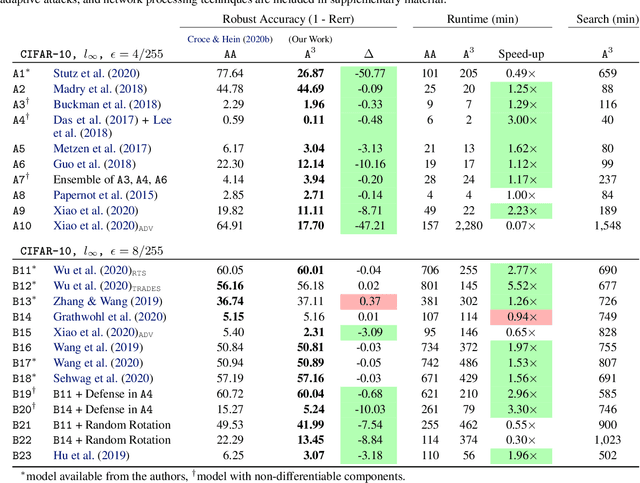
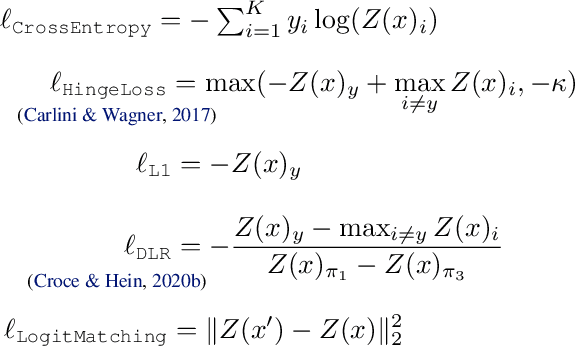
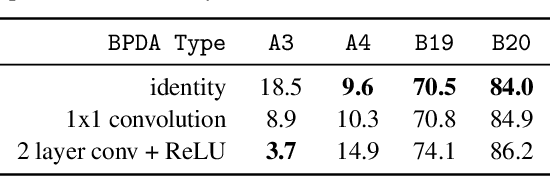
Reliable evaluation of adversarial defenses is a challenging task, currently limited to an expert who manually crafts attacks that exploit the defense's inner workings, or to approaches based on ensemble of fixed attacks, none of which may be effective for the specific defense at hand. Our key observation is that custom attacks are composed from a set of reusable building blocks, such as fine-tuning relevant attack parameters, network transformations, and custom loss functions. Based on this observation, we present an extensible framework that defines a search space over these reusable building blocks and automatically discovers an effective attack on a given model with an unknown defense by searching over suitable combinations of these blocks. We evaluated our framework on 23 adversarial defenses and showed it outperforms AutoAttack, the current state-of-the-art tool for reliable evaluation of adversarial defenses: our discovered attacks are either stronger, producing 3.0%-50.8% additional adversarial examples (10 cases), or are typically 2x faster while enjoying similar adversarial robustness (13 cases).