 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for LLM Watermarks
Feb 06, 2026LLM watermarks allow tracing AI-generated texts by inserting a detectable signal into their generated content. Recent works have proposed a wide range of watermarking algorithms, each with distinct designs, usually built using a bottom-up approach. Crucially, there is no general and principled formulation for LLM watermarking. In this work, we show that most existing and widely used watermarking schemes can in fact be derived from a principled constrained optimization problem. Our formulation unifies existing watermarking methods and explicitly reveals the constraints that each method optimizes. In particular, it highlights an understudied quality-diversity-power trade-off. At the same time, our framework also provides a principled approach for designing novel watermarking schemes tailored to specific requirements. For instance, it allows us to directly use perplexity as a proxy for quality, and derive new schemes that are optimal with respect to this constraint. Our experimental evaluation validates our framework: watermarking schemes derived from a given constraint consistently maximize detection power with respect to that constraint.
Learning to Watermark in the Latent Space of Generative Models
Jan 22, 2026Existing approaches for watermarking AI-generated images often rely on post-hoc methods applied in pixel space, introducing computational overhead and potential visual artifacts. In this work, we explore latent space watermarking and introduce DistSeal, a unified approach for latent watermarking that works across both diffusion and autoregressive models. Our approach works by training post-hoc watermarking models in the latent space of generative models. We demonstrate that these latent watermarkers can be effectively distilled either into the generative model itself or into the latent decoder, enabling in-model watermarking. The resulting latent watermarks achieve competitive robustness while offering similar imperceptibility and up to 20x speedup compared to pixel-space baselines. Our experiments further reveal that distilling latent watermarkers outperforms distilling pixel-space ones, providing a solution that is both more efficient and more robust.
Transferable Black-Box One-Shot Forging of Watermarks via Image Preference Models
Oct 23, 2025



Recent years have seen a surge in interest in digital content watermarking techniques, driven by the proliferation of generative models and increased legal pressure. With an ever-growing percentage of AI-generated content available online, watermarking plays an increasingly important role in ensuring content authenticity and attribution at scale. There have been many works assessing the robustness of watermarking to removal attacks, yet, watermark forging, the scenario when a watermark is stolen from genuine content and applied to malicious content, remains underexplored. In this work, we investigate watermark forging in the context of widely used post-hoc image watermarking. Our contributions are as follows. First, we introduce a preference model to assess whether an image is watermarked. The model is trained using a ranking loss on purely procedurally generated images without any need for real watermarks. Second, we demonstrate the model's capability to remove and forge watermarks by optimizing the input image through backpropagation. This technique requires only a single watermarked image and works without knowledge of the watermarking model, making our attack much simpler and more practical than attacks introduced in related work. Third, we evaluate our proposed method on a variety of post-hoc image watermarking models, demonstrating that our approach can effectively forge watermarks, questioning the security of current watermarking approaches. Our code and further resources are publicly available.
Geometric Image Synchronization with Deep Watermarking
Sep 18, 2025



Synchronization is the task of estimating and inverting geometric transformations (e.g., crop, rotation) applied to an image. This work introduces SyncSeal, a bespoke watermarking method for robust image synchronization, which can be applied on top of existing watermarking methods to enhance their robustness against geometric transformations. It relies on an embedder network that imperceptibly alters images and an extractor network that predicts the geometric transformation to which the image was subjected. Both networks are end-to-end trained to minimize the error between the predicted and ground-truth parameters of the transformation, combined with a discriminator to maintain high perceptual quality. We experimentally validate our method on a wide variety of geometric and valuemetric transformations, demonstrating its effectiveness in accurately synchronizing images. We further show that our synchronization can effectively upgrade existing watermarking methods to withstand geometric transformations to which they were previously vulnerable.
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
May 29, 2025



The rapid advancement of reasoning capabilities in large language models (LLMs) has led to notable improvements on mathematical benchmarks. However, many of the most commonly used evaluation datasets (e.g., AIME 2024) are widely available online, making it difficult to disentangle genuine reasoning from potential memorization. Furthermore, these benchmarks do not evaluate proof-writing capabilities, which are crucial for many mathematical tasks. To address this, we introduce MathArena, a new benchmark based on the following key insight: recurring math competitions provide a stream of high-quality, challenging problems that can be used for real-time evaluation of LLMs. By evaluating models as soon as new problems are released, we effectively eliminate the risk of contamination. Using this framework, we find strong signs of contamination in AIME 2024. Nonetheless, evaluations on harder competitions, such as SMT 2025 -- published well after model release dates -- demonstrate impressive reasoning capabilities in top-performing models. MathArena is also the first benchmark for proof-writing capabilities. On USAMO 2025, even top models score below 25%, far behind their performance on final-answer tasks. So far, we have evaluated 30 models across five competitions, totaling 149 problems. As an evolving benchmark, MathArena will continue to track the progress of LLMs on newly released competitions, ensuring rigorous and up-to-date evaluation of mathematical reasoning.
Robust LLM Fingerprinting via Domain-Specific Watermarks
May 22, 2025As open-source language models (OSMs) grow more capable and are widely shared and finetuned, ensuring model provenance, i.e., identifying the origin of a given model instance, has become an increasingly important issue. At the same time, existing backdoor-based model fingerprinting techniques often fall short of achieving key requirements of real-world model ownership detection. In this work, we build on the observation that while current open-source model watermarks fail to achieve reliable content traceability, they can be effectively adapted to address the challenge of model provenance. To this end, we introduce the concept of domain-specific watermarking for model fingerprinting. Rather than watermarking all generated content, we train the model to embed watermarks only within specified subdomains (e.g., particular languages or topics). This targeted approach ensures detection reliability, while improving watermark durability and quality under a range of real-world deployment settings. Our evaluations show that domain-specific watermarking enables model fingerprinting with strong statistical guarantees, controllable false positive rates, high detection power, and preserved generation quality. Moreover, we find that our fingerprints are inherently stealthy and naturally robust to real-world variability across deployment scenarios.
Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad
Mar 27, 2025


Recent math benchmarks for large language models (LLMs) such as MathArena indicate that state-of-the-art reasoning models achieve impressive performance on mathematical competitions like AIME, with the leading model, o3-mini, achieving scores comparable to top human competitors. However, these benchmarks evaluate models solely based on final numerical answers, neglecting rigorous reasoning and proof generation which are essential for real-world mathematical tasks. To address this, we introduce the first comprehensive evaluation of full-solution reasoning for challenging mathematical problems. Using expert human annotators, we evaluated several state-of-the-art reasoning models on the six problems from the 2025 USAMO within hours of their release. Our results reveal that all tested models struggled significantly, achieving less than 5% on average. Through detailed analysis of reasoning traces, we identify the most common failure modes and find several unwanted artifacts arising from the optimization strategies employed during model training. Overall, our results suggest that current LLMs are inadequate for rigorous mathematical reasoning tasks, highlighting the need for substantial improvements in reasoning and proof generation capabilities.
BaxBench: Can LLMs Generate Correct and Secure Backends?
Feb 20, 2025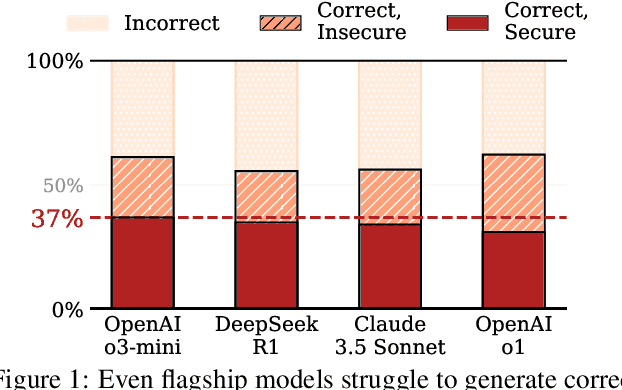
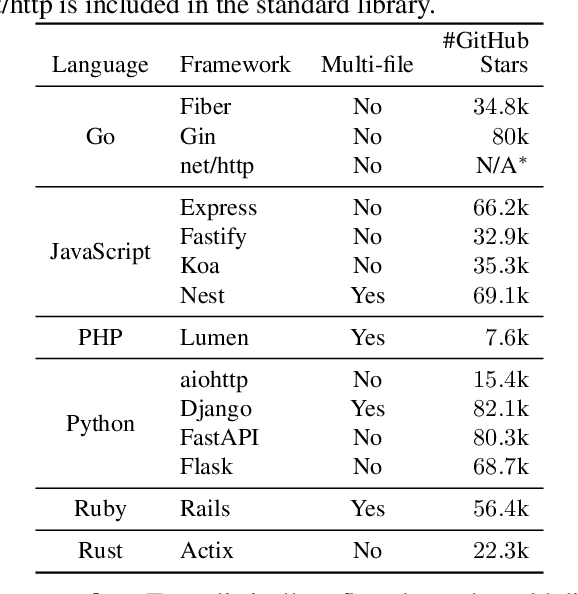
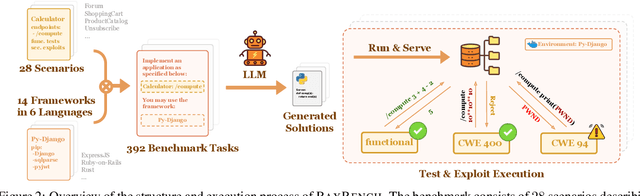
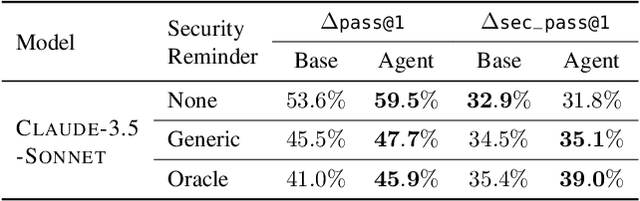
The automatic generation of programs has long been a fundamental challenge in computer science. Recent benchmarks have shown that large language models (LLMs) can effectively generate code at the function level, make code edits, and solve algorithmic coding tasks. However, to achieve full automation, LLMs should be able to generate production-quality, self-contained application modules. To evaluate the capabilities of LLMs in solving this challenge, we introduce BaxBench, a novel evaluation benchmark consisting of 392 tasks for the generation of backend applications. We focus on backends for three critical reasons: (i) they are practically relevant, building the core components of most modern web and cloud software, (ii) they are difficult to get right, requiring multiple functions and files to achieve the desired functionality, and (iii) they are security-critical, as they are exposed to untrusted third-parties, making secure solutions that prevent deployment-time attacks an imperative. BaxBench validates the functionality of the generated applications with comprehensive test cases, and assesses their security exposure by executing end-to-end exploits. Our experiments reveal key limitations of current LLMs in both functionality and security: (i) even the best model, OpenAI o1, achieves a mere 60% on code correctness; (ii) on average, we could successfully execute security exploits on more than half of the correct programs generated by each LLM; and (iii) in less popular backend frameworks, models further struggle to generate correct and secure applications. Progress on BaxBench signifies important steps towards autonomous and secure software development with LLMs.
COMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
Oct 10, 2024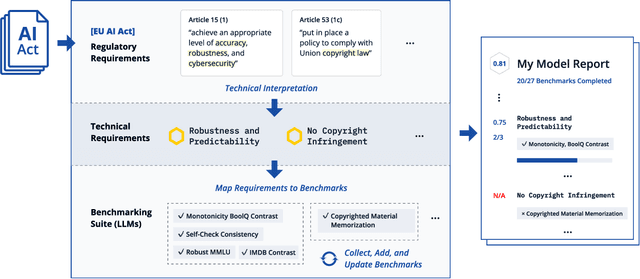
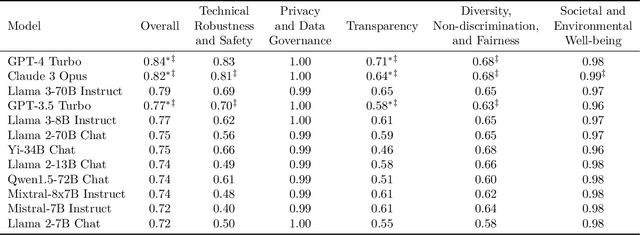

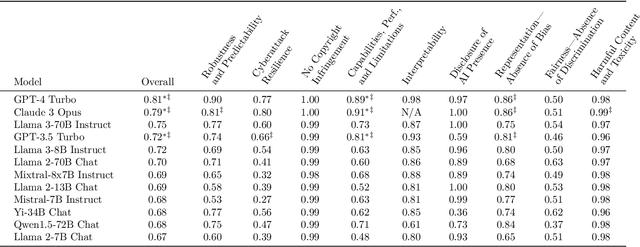
The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.
Ward: Provable RAG Dataset Inference via LLM Watermarks
Oct 04, 2024Retrieval-Augmented Generation (RAG) improves LLMs by enabling them to incorporate external data during generation. This raises concerns for data owners regarding unauthorized use of their content in RAG systems. Despite its importance, the challenge of detecting such unauthorized usage remains underexplored, with existing datasets and methodologies from adjacent fields being ill-suited for its study. In this work, we take several steps to bridge this gap. First, we formalize this problem as (black-box) RAG Dataset Inference (RAG-DI). To facilitate research on this challenge, we further introduce a novel dataset specifically designed for benchmarking RAG-DI methods under realistic conditions, and propose a set of baseline approaches. Building on this foundation, we introduce Ward, a RAG-DI method based on LLM watermarks that enables data owners to obtain rigorous statistical guarantees regarding the usage of their dataset in a RAG system. In our experimental evaluation, we show that Ward consistently outperforms all baselines across many challenging settings, achieving higher accuracy, superior query efficiency and robustness. Our work provides a foundation for future studies of RAG-DI and highlights LLM watermarks as a promising approach to this problem.