 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARP: Learner-Agnostic Robust Data Prefiltering
Jun 25, 2025The widespread availability of large public datasets is a key factor behind the recent successes of statistical inference and machine learning methods. However, these datasets often contain some low-quality or contaminated data, to which many learning procedures are sensitive. Therefore, the question of whether and how public datasets should be prefiltered to facilitate accurate downstream learning arises. On a technical level this requires the construction of principled data prefiltering methods which are learner-agnostic robust, in the sense of provably protecting a set of pre-specified downstream learners from corrupted data. In this work, we formalize the problem of Learner-Agnostic Robust data Prefiltering (LARP), which aims at finding prefiltering procedures that minimize a worst-case loss over a pre-specified set of learners. We first instantiate our framework in the context of scalar mean estimation with Huber estimators under the Huber data contamination model. We provide a hardness result on a specific problem instance and analyze several natural prefiltering procedures. Our theoretical results indicate that performing LARP on a heterogeneous set of learners leads to some loss in model performance compared to the alternative of prefiltering data for each learner/use-case individually. We explore the resulting utility loss and its dependence on the problem parameters via extensive experiments on real-world image and tabular data, observing statistically significant reduction in utility. Finally, we model the trade-off between the utility drop and the cost of repeated (learner-specific) prefiltering within a game-theoretic framework and showcase benefits of LARP for large datasets.
Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad
Mar 27, 2025Recent math benchmarks for large language models (LLMs) such as MathArena indicate that state-of-the-art reasoning models achieve impressive performance on mathematical competitions like AIME, with the leading model, o3-mini, achieving scores comparable to top human competitors. However, these benchmarks evaluate models solely based on final numerical answers, neglecting rigorous reasoning and proof generation which are essential for real-world mathematical tasks. To address this, we introduce the first comprehensive evaluation of full-solution reasoning for challenging mathematical problems. Using expert human annotators, we evaluated several state-of-the-art reasoning models on the six problems from the 2025 USAMO within hours of their release. Our results reveal that all tested models struggled significantly, achieving less than 5% on average. Through detailed analysis of reasoning traces, we identify the most common failure modes and find several unwanted artifacts arising from the optimization strategies employed during model training. Overall, our results suggest that current LLMs are inadequate for rigorous mathematical reasoning tasks, highlighting the need for substantial improvements in reasoning and proof generation capabilities.
Incentivizing Truthful Collaboration in Heterogeneous Federated Learning
Dec 01, 2024
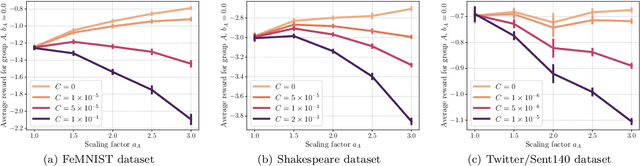


It is well-known that Federated Learning (FL) is vulnerable to manipulated updates from clients. In this work we study the impact of data heterogeneity on clients' incentives to manipulate their updates. We formulate a game in which clients may upscale their gradient updates in order to ``steer'' the server model to their advantage. We develop a payment rule that disincentivizes sending large gradient updates, and steers the clients towards truthfully reporting their gradients. We also derive explicit bounds on the clients' payments and the convergence rate of the global model, which allows us to study the trade-off between heterogeneity, payments and convergence.