 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrokenMath: A Benchmark for Sycophancy in Theorem Proving with LLMs
Oct 06, 2025
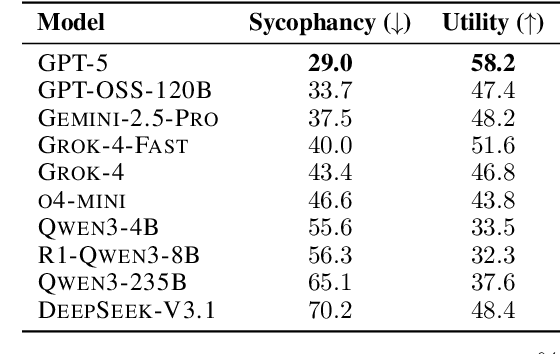


Large language models (LLMs) have recently shown strong performance on mathematical benchmarks. At the same time, they are prone to hallucination and sycophancy, often providing convincing but flawed proofs for incorrect mathematical statements provided by users. This significantly limits the applicability of LLMs in theorem proving, as verification of these flawed proofs must be done manually by expert mathematicians. However, existing benchmarks that measure sycophancy in mathematics are limited: they focus solely on final-answer problems, rely on very simple and often contaminated datasets, and construct benchmark samples using synthetic modifications that create ill-posed questions rather than well-posed questions that are demonstrably false. To address these issues, we introduce BrokenMath, the first benchmark for evaluating sycophantic behavior in LLMs within the context of natural language theorem proving. BrokenMath is built from advanced 2025 competition problems, which are perturbed with an LLM to produce false statements and subsequently refined through expert review. Using an LLM-as-a-judge framework, we evaluate state-of-the-art LLMs and agentic systems and find that sycophancy is widespread, with the best model, GPT-5, producing sycophantic answers 29% of the time. We further investigate several mitigation strategies, including test-time interventions and supervised fine-tuning on curated sycophantic examples. These approaches substantially reduce, but do not eliminate, sycophantic behavior.
Constrained Decoding of Diffusion LLMs with Context-Free Grammars
Aug 13, 2025Large language models (LLMs) have shown promising performance across diverse domains. Many practical applications of LLMs, such as code completion and structured data extraction, require adherence to syntactic constraints specified by a formal language. Yet, due to their probabilistic nature, LLM output is not guaranteed to adhere to such formal languages. Prior work has proposed constrained decoding as a means to restrict LLM generation to particular formal languages. However, existing works are not applicable to the emerging paradigm of diffusion LLMs, when used in practical scenarios such as the generation of formally correct C++ or JSON output. In this paper we address this challenge and present the first constrained decoding method for diffusion models, one that can handle formal languages captured by context-free grammars. We begin by reducing constrained decoding to the more general additive infilling problem, which asks whether a partial output can be completed to a valid word in the target language. This problem also naturally subsumes the previously unaddressed multi-region infilling constrained decoding. We then reduce this problem to the task of deciding whether the intersection of the target language and a regular language is empty and present an efficient algorithm to solve it for context-free languages. Empirical results on various applications, such as C++ code infilling and structured data extraction in JSON, demonstrate that our method achieves near-perfect syntactic correctness while consistently preserving or improving functional correctness. Importantly, our efficiency optimizations ensure that the computational overhead remains practical.
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
May 29, 2025



The rapid advancement of reasoning capabilities in large language models (LLMs) has led to notable improvements on mathematical benchmarks. However, many of the most commonly used evaluation datasets (e.g., AIME 2024) are widely available online, making it difficult to disentangle genuine reasoning from potential memorization. Furthermore, these benchmarks do not evaluate proof-writing capabilities, which are crucial for many mathematical tasks. To address this, we introduce MathArena, a new benchmark based on the following key insight: recurring math competitions provide a stream of high-quality, challenging problems that can be used for real-time evaluation of LLMs. By evaluating models as soon as new problems are released, we effectively eliminate the risk of contamination. Using this framework, we find strong signs of contamination in AIME 2024. Nonetheless, evaluations on harder competitions, such as SMT 2025 -- published well after model release dates -- demonstrate impressive reasoning capabilities in top-performing models. MathArena is also the first benchmark for proof-writing capabilities. On USAMO 2025, even top models score below 25%, far behind their performance on final-answer tasks. So far, we have evaluated 30 models across five competitions, totaling 149 problems. As an evolving benchmark, MathArena will continue to track the progress of LLMs on newly released competitions, ensuring rigorous and up-to-date evaluation of mathematical reasoning.
Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad
Mar 27, 2025


Recent math benchmarks for large language models (LLMs) such as MathArena indicate that state-of-the-art reasoning models achieve impressive performance on mathematical competitions like AIME, with the leading model, o3-mini, achieving scores comparable to top human competitors. However, these benchmarks evaluate models solely based on final numerical answers, neglecting rigorous reasoning and proof generation which are essential for real-world mathematical tasks. To address this, we introduce the first comprehensive evaluation of full-solution reasoning for challenging mathematical problems. Using expert human annotators, we evaluated several state-of-the-art reasoning models on the six problems from the 2025 USAMO within hours of their release. Our results reveal that all tested models struggled significantly, achieving less than 5% on average. Through detailed analysis of reasoning traces, we identify the most common failure modes and find several unwanted artifacts arising from the optimization strategies employed during model training. Overall, our results suggest that current LLMs are inadequate for rigorous mathematical reasoning tasks, highlighting the need for substantial improvements in reasoning and proof generation capabilities.
A Unified Approach to Routing and Cascading for LLMs
Oct 14, 2024



The widespread applicability of large language models (LLMs) has increased the availability of many fine-tuned models of various sizes targeting specific tasks. Given a set of such specialized models, to maximize overall performance, it is important to figure out the optimal strategy for selecting the right model for a given user query. An effective strategy could drastically increase overall performance and even offer improvements over a single large monolithic model. Existing approaches typically fall into two categories: routing, where a single model is selected for each query, and cascading, which runs a sequence of increasingly larger models until a satisfactory answer is obtained. However, both have notable limitations: routing commits to an initial model without flexibility, while cascading requires executing every model in sequence, which can be inefficient. Additionally, the conditions under which these strategies are provably optimal remain unclear. In this work, we derive optimal strategies for both routing and cascading. Building on this analysis, we propose a novel approach called cascade routing, which combines the adaptability of routing with the cost-efficiency of cascading. Our experiments demonstrate that cascade routing consistently outperforms both routing and cascading across a variety of settings, improving both output quality and lowering computational cost, thus offering a unified and efficient solution to the model selection problem.
Polyrating: A Cost-Effective and Bias-Aware Rating System for LLM Evaluation
Sep 01, 2024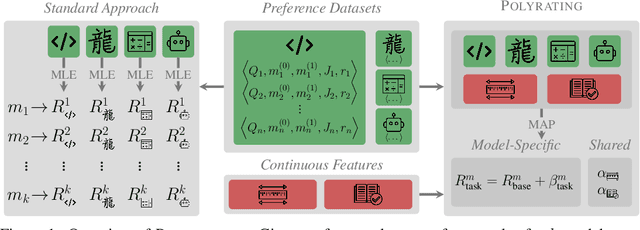
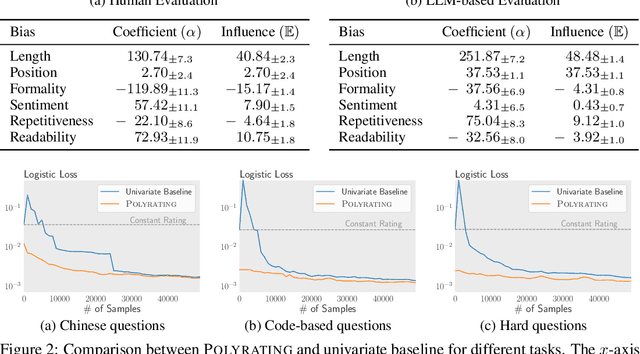
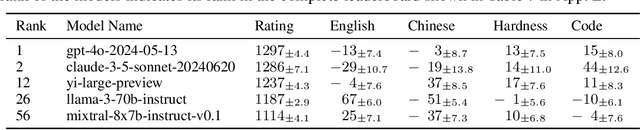
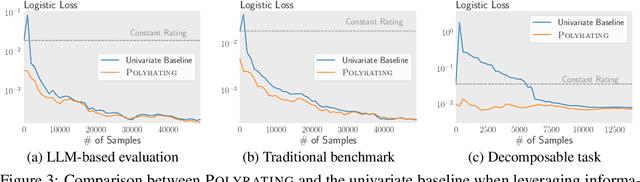
Rating-based human evaluation has become an essential tool to accurately evaluate the impressive performance of Large language models (LLMs). However, current rating systems suffer from several critical limitations. Specifically, they fail to account for human biases that significantly influence evaluation results, require large and expensive preference datasets to obtain accurate ratings, and do not facilitate meaningful comparisons of model ratings across different tasks. To address these issues, we introduce Polyrating, an expressive and flexible rating system based on maximum a posteriori estimation that enables a more nuanced and thorough analysis of model performance at lower costs. Polyrating can detect and quantify biases affecting human preferences, ensuring fairer model comparisons. Furthermore, Polyrating can reduce the cost of human evaluations by up to $41\%$ for new models and up to $77\%$ for new tasks by leveraging existing benchmark scores. Lastly, Polyrating enables direct comparisons of ratings across different tasks, providing a comprehensive understanding of an LLMs' strengths, weaknesses, and relative performance across different applications.
ConStat: Performance-Based Contamination Detection in Large Language Models
May 25, 2024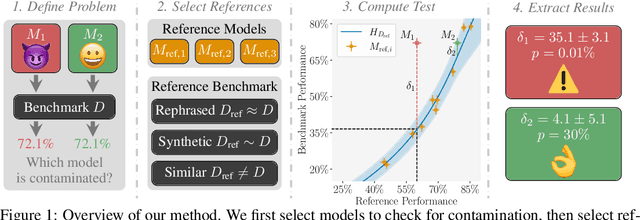
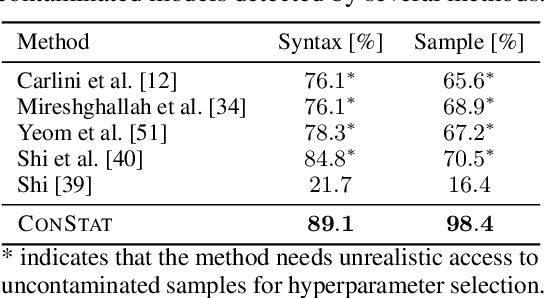
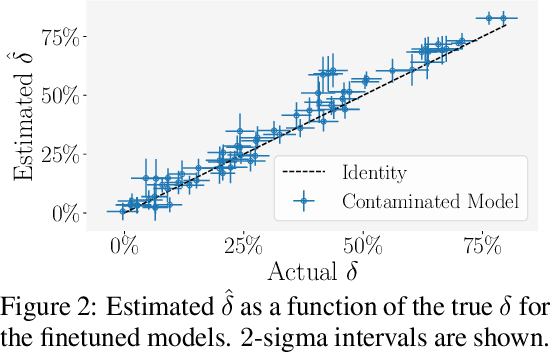
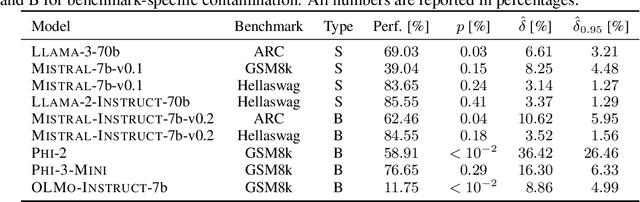
Public benchmarks play an essential role in the evaluation of large language models. However, data contamination can lead to inflated performance, rendering them unreliable for model comparison. It is therefore crucial to detect contamination and estimate its impact on measured performance. Unfortunately, existing detection methods can be easily evaded and fail to quantify contamination. To overcome these limitations, we propose a novel definition of contamination as artificially inflated and non-generalizing benchmark performance instead of the inclusion of benchmark samples in the training data. This perspective enables us to detect any model with inflated performance, i.e., performance that does not generalize to rephrased samples, synthetic samples from the same distribution, or different benchmarks for the same task. Based on this insight, we develop ConStat, a statistical method that reliably detects and quantifies contamination by comparing performance between a primary and reference benchmark relative to a set of reference models. We demonstrate the effectiveness of ConStat in an extensive evaluation of diverse model architectures, benchmarks, and contamination scenarios and find high levels of contamination in multiple popular models including Mistral, Llama, Yi, and the top-3 Open LLM Leaderboard models.
Evading Data Contamination Detection for Language Models is (too) Easy
Feb 12, 2024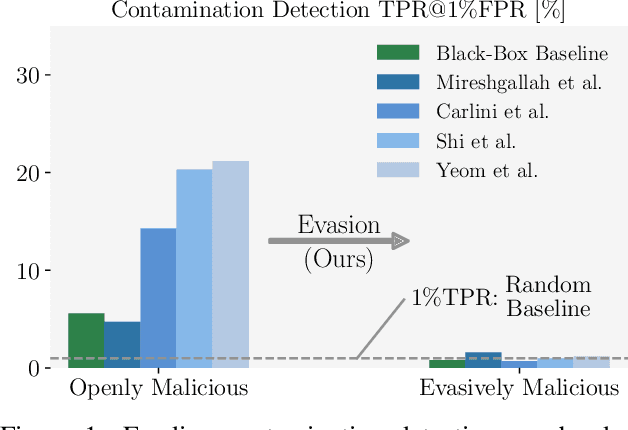



Large language models are widespread, with their performance on benchmarks frequently guiding user preferences for one model over another. However, the vast amount of data these models are trained on can inadvertently lead to contamination with public benchmarks, thus compromising performance measurements. While recently developed contamination detection methods try to address this issue, they overlook the possibility of deliberate contamination by malicious model providers aiming to evade detection. We argue that this setting is of crucial importance as it casts doubt on the reliability of public benchmarks. To more rigorously study this issue, we propose a categorization of both model providers and contamination detection methods. This reveals vulnerabilities in existing methods that we exploit with EAL, a simple yet effective contamination technique that significantly inflates benchmark performance while completely evading current detection methods.
Controlled Text Generation via Language Model Arithmetic
Nov 24, 2023



As Large Language Models (LLMs) are deployed more widely, customization with respect to vocabulary, style and character becomes more important. In this work we introduce model arithmetic, a novel inference framework for composing and biasing LLMs without the need for model (re)training or highly specific datasets. In addition, the framework allows for more precise control of generated text than direct prompting and prior controlled text generation (CTG) techniques. Using model arithmetic, we can express prior CTG techniques as simple formulas and naturally extend them to new and more effective formulations. Further, we show that speculative sampling, a technique for efficient LLM sampling, extends to our setting. This enables highly efficient text generation with multiple composed models with only marginal overhead over a single model. Our empirical evaluation demonstrates that model arithmetic allows fine-grained control of generated text while outperforming state-of-the-art on the task of toxicity reduction.