 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Benchmark Generation for Repository-Level Coding Tasks
Mar 10, 2025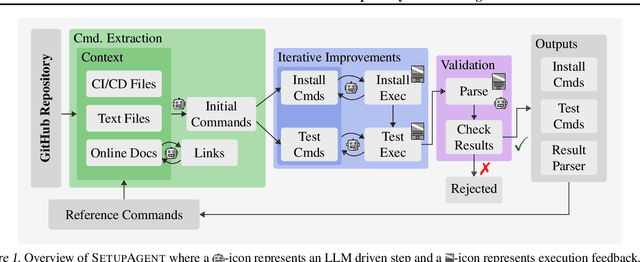


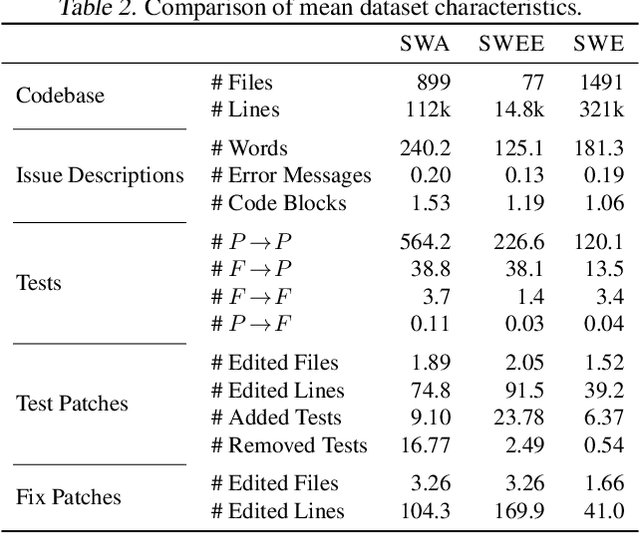
Code Agent development is an extremely active research area, where a reliable performance metric is critical for tracking progress and guiding new developments. This demand is underscored by the meteoric rise in popularity of SWE-Bench. This benchmark challenges code agents to generate patches addressing GitHub issues given the full repository as context. The correctness of generated patches is then evaluated by executing a human-written test suite extracted from the repository after the issue's resolution. However, constructing benchmarks like SWE-Bench requires substantial manual effort to set up historically accurate execution environments for testing. Crucially, this severely limits the number of considered repositories, e.g., just 12 for SWE-Bench. Considering so few repositories, selected for their popularity runs the risk of leading to a distributional mismatch, i.e., the measured performance may not be representative of real-world scenarios potentially misguiding development efforts. In this work, we address this challenge and introduce SetUpAgent, a fully automated system capable of historically accurate dependency setup, test execution, and result parsing. Using SetUpAgent, we generate two new datasets: (i) SWEE-Bench an extended version of SWE-Bench encompassing hundreds of repositories, and (ii) SWA-Bench a benchmark focusing on applications rather than libraries. Comparing these datasets to SWE-Bench with respect to their characteristics and code agent performance, we find significant distributional differences, including lower issue description quality and detail level, higher fix complexity, and most importantly up to 40% lower agent success rates.
Average Certified Radius is a Poor Metric for Randomized Smoothing
Oct 09, 2024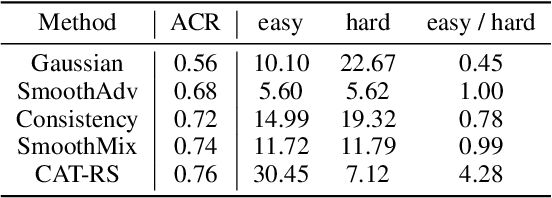
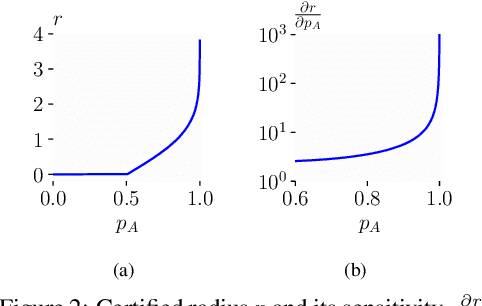
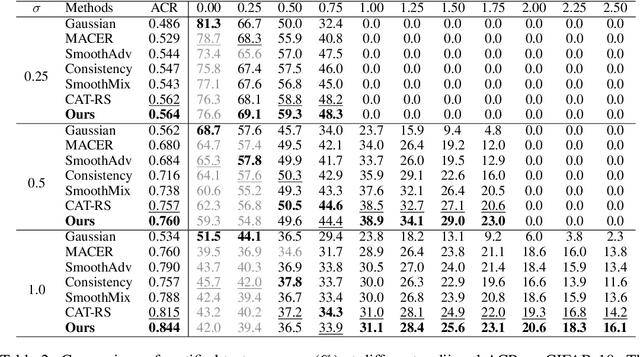
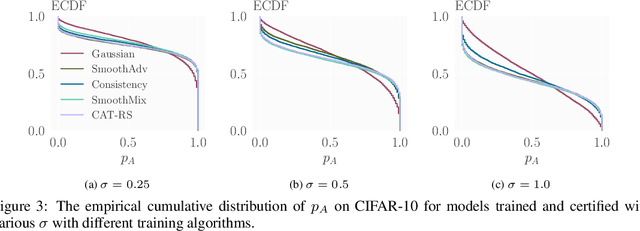
Randomized smoothing is a popular approach for providing certified robustness guarantees against adversarial attacks, and has become a very active area of research. Over the past years, the average certified radius (ACR) has emerged as the single most important metric for comparing methods and tracking progress in the field. However, in this work, we show that ACR is an exceptionally poor metric for evaluating robustness guarantees provided by randomized smoothing. We theoretically show not only that a trivial classifier can have arbitrarily large ACR, but also that ACR is much more sensitive to improvements on easy samples than on hard ones. Empirically, we confirm that existing training strategies that improve ACR reduce the model's robustness on hard samples. Further, we show that by focusing on easy samples, we can effectively replicate the increase in ACR. We develop strategies, including explicitly discarding hard samples, reweighing the dataset with certified radius, and extreme optimization for easy samples, to achieve state-of-the-art ACR, although these strategies ignore robustness for the general data distribution. Overall, our results suggest that ACR has introduced a strong undesired bias to the field, and better metrics are required to holistically evaluate randomized smoothing.
Diagnosing Robotics Systems Issues with Large Language Models
Oct 06, 2024Quickly resolving issues reported in industrial applications is crucial to minimize economic impact. However, the required data analysis makes diagnosing the underlying root causes a challenging and time-consuming task, even for experts. In contrast, large language models (LLMs) excel at analyzing large amounts of data. Indeed, prior work in AI-Ops demonstrates their effectiveness in analyzing IT systems. Here, we extend this work to the challenging and largely unexplored domain of robotics systems. To this end, we create SYSDIAGBENCH, a proprietary system diagnostics benchmark for robotics, containing over 2500 reported issues. We leverage SYSDIAGBENCH to investigate the performance of LLMs for root cause analysis, considering a range of model sizes and adaptation techniques. Our results show that QLoRA finetuning can be sufficient to let a 7B-parameter model outperform GPT-4 in terms of diagnostic accuracy while being significantly more cost-effective. We validate our LLM-as-a-judge results with a human expert study and find that our best model achieves similar approval ratings as our reference labels.
Code Agents are State of the Art Software Testers
Jun 18, 2024



Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents for formalizing user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth patches, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using fail-to-pass rate and coverage metrics, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent.
ConStat: Performance-Based Contamination Detection in Large Language Models
May 25, 2024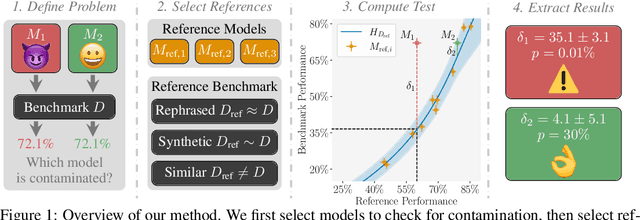
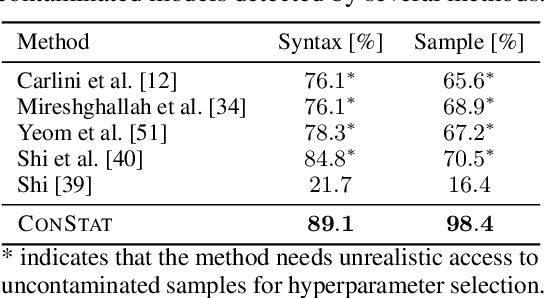
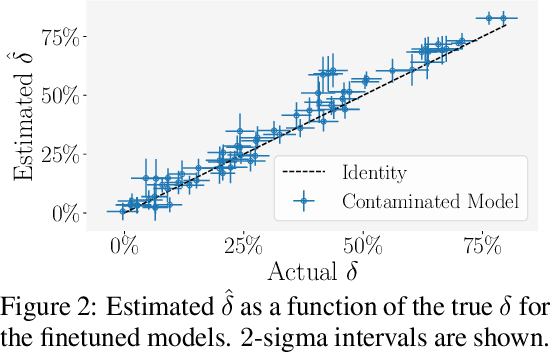
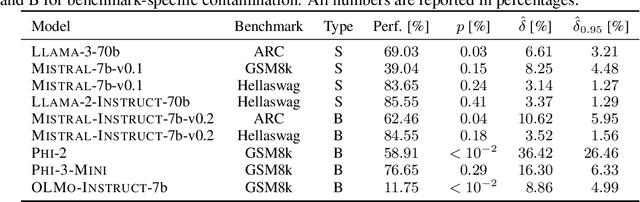
Public benchmarks play an essential role in the evaluation of large language models. However, data contamination can lead to inflated performance, rendering them unreliable for model comparison. It is therefore crucial to detect contamination and estimate its impact on measured performance. Unfortunately, existing detection methods can be easily evaded and fail to quantify contamination. To overcome these limitations, we propose a novel definition of contamination as artificially inflated and non-generalizing benchmark performance instead of the inclusion of benchmark samples in the training data. This perspective enables us to detect any model with inflated performance, i.e., performance that does not generalize to rephrased samples, synthetic samples from the same distribution, or different benchmarks for the same task. Based on this insight, we develop ConStat, a statistical method that reliably detects and quantifies contamination by comparing performance between a primary and reference benchmark relative to a set of reference models. We demonstrate the effectiveness of ConStat in an extensive evaluation of diverse model architectures, benchmarks, and contamination scenarios and find high levels of contamination in multiple popular models including Mistral, Llama, Yi, and the top-3 Open LLM Leaderboard models.
DAGER: Exact Gradient Inversion for Large Language Models
May 24, 2024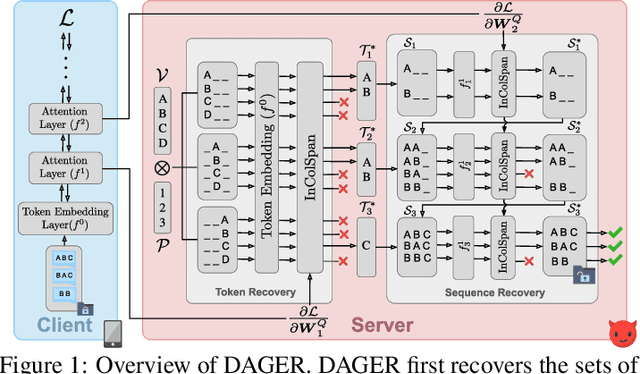
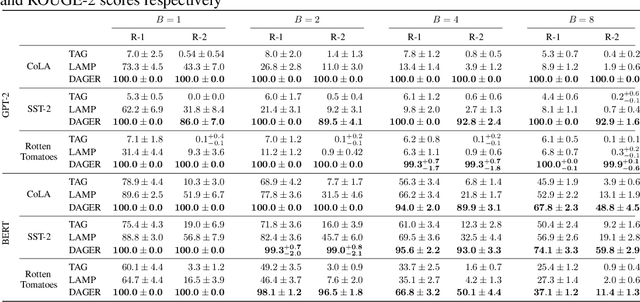

Federated learning works by aggregating locally computed gradients from multiple clients, thus enabling collaborative training without sharing private client data. However, prior work has shown that the data can actually be recovered by the server using so-called gradient inversion attacks. While these attacks perform well when applied on images, they are limited in the text domain and only permit approximate reconstruction of small batches and short input sequences. In this work, we propose DAGER, the first algorithm to recover whole batches of input text exactly. DAGER leverages the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings to efficiently check if a given token sequence is part of the client data. We use this check to exactly recover full batches in the honest-but-curious setting without any prior on the data for both encoder- and decoder-based architectures using exhaustive heuristic search and a greedy approach, respectively. We provide an efficient GPU implementation of DAGER and show experimentally that it recovers full batches of size up to 128 on large language models (LLMs), beating prior attacks in speed (20x at same batch size), scalability (10x larger batches), and reconstruction quality (ROUGE-1/2 > 0.99).
Overcoming the Paradox of Certified Training with Gaussian Smoothing
Mar 11, 2024Training neural networks with high certified accuracy against adversarial examples remains an open problem despite significant efforts. While certification methods can effectively leverage tight convex relaxations for bound computation, in training, these methods perform worse than looser relaxations. Prior work hypothesized that this is caused by the discontinuity and perturbation sensitivity of the loss surface induced by these tighter relaxations. In this work, we show theoretically that Gaussian Loss Smoothing can alleviate both of these issues. We confirm this empirically by proposing a certified training method combining PGPE, an algorithm computing gradients of a smoothed loss, with different convex relaxations. When using this training method, we observe that tighter bounds indeed lead to strictly better networks that can outperform state-of-the-art methods on the same network. While scaling PGPE-based training remains challenging due to high computational cost, our results clearly demonstrate the promise of Gaussian Loss Smoothing for training certifiably robust neural networks.
SPEAR:Exact Gradient Inversion of Batches in Federated Learning
Mar 06, 2024
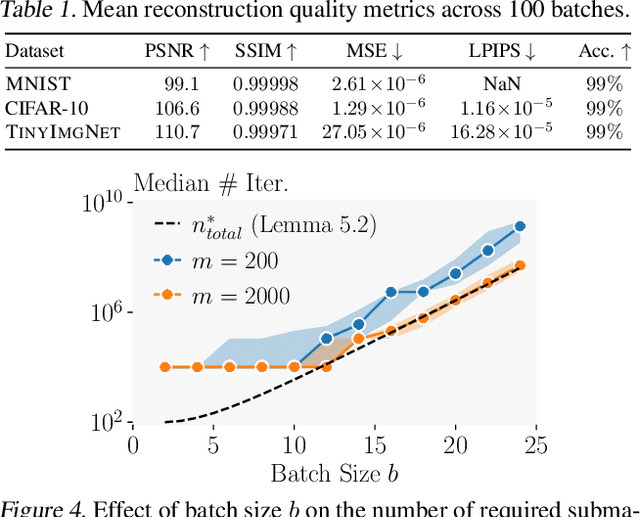
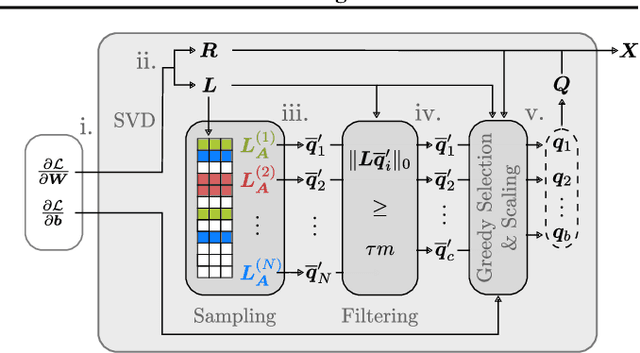

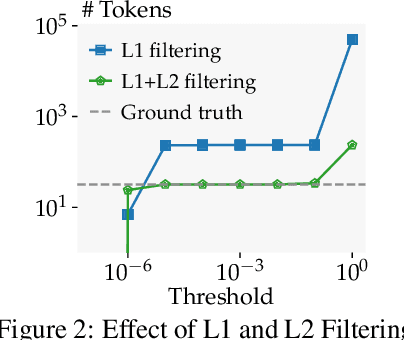
Federated learning is a popular framework for collaborative machine learning where multiple clients only share gradient updates on their local data with the server and not the actual data. Unfortunately, it was recently shown that gradient inversion attacks can reconstruct this data from these shared gradients. Existing attacks enable exact reconstruction only for a batch size of $b=1$ in the important honest-but-curious setting, with larger batches permitting only approximate reconstruction. In this work, we propose \emph{the first algorithm reconstructing whole batches with $b >1$ exactly}. This approach combines mathematical insights into the explicit low-rank structure of gradients with a sampling-based algorithm. Crucially, we leverage ReLU-induced gradient sparsity to precisely filter out large numbers of incorrect samples, making a final reconstruction step tractable. We provide an efficient GPU implementation for fully connected networks and show that it recovers batches of $b \lesssim 25$ elements exactly while being tractable for large network widths and depths.
Evading Data Contamination Detection for Language Models is (too) Easy
Feb 12, 2024Large language models are widespread, with their performance on benchmarks frequently guiding user preferences for one model over another. However, the vast amount of data these models are trained on can inadvertently lead to contamination with public benchmarks, thus compromising performance measurements. While recently developed contamination detection methods try to address this issue, they overlook the possibility of deliberate contamination by malicious model providers aiming to evade detection. We argue that this setting is of crucial importance as it casts doubt on the reliability of public benchmarks. To more rigorously study this issue, we propose a categorization of both model providers and contamination detection methods. This reveals vulnerabilities in existing methods that we exploit with EAL, a simple yet effective contamination technique that significantly inflates benchmark performance while completely evading current detection methods.
Prompt Sketching for Large Language Models
Nov 08, 2023Many recent prompting strategies for large language models (LLMs) query the model multiple times sequentially -- first to produce intermediate results and then the final answer. However, using these methods, both decoder and model are unaware of potential follow-up prompts, leading to disconnected and undesirably wordy intermediate responses. In this work, we address this issue by proposing prompt sketching, a new prompting paradigm in which an LLM does not only respond by completing a prompt, but by predicting values for multiple variables in a template. This way, sketching grants users more control over the generation process, e.g., by providing a reasoning framework via intermediate instructions, leading to better overall results. The key idea enabling sketching with existing, autoregressive models is to adapt the decoding procedure to also score follow-up instructions during text generation, thus optimizing overall template likelihood in inference. Our experiments show that in a zero-shot setting, prompt sketching outperforms existing, sequential prompting schemes such as direct asking or chain-of-thought on 7 out of 8 LLM benchmarking tasks, including state tracking, arithmetic reasoning, and general question answering. To facilitate future use, we release a number of generic, yet effective sketches applicable to many tasks, and an open source library called dclib, powering our sketch-aware decoders.