 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrokenMath: A Benchmark for Sycophancy in Theorem Proving with LLMs
Oct 06, 2025Large language models (LLMs) have recently shown strong performance on mathematical benchmarks. At the same time, they are prone to hallucination and sycophancy, often providing convincing but flawed proofs for incorrect mathematical statements provided by users. This significantly limits the applicability of LLMs in theorem proving, as verification of these flawed proofs must be done manually by expert mathematicians. However, existing benchmarks that measure sycophancy in mathematics are limited: they focus solely on final-answer problems, rely on very simple and often contaminated datasets, and construct benchmark samples using synthetic modifications that create ill-posed questions rather than well-posed questions that are demonstrably false. To address these issues, we introduce BrokenMath, the first benchmark for evaluating sycophantic behavior in LLMs within the context of natural language theorem proving. BrokenMath is built from advanced 2025 competition problems, which are perturbed with an LLM to produce false statements and subsequently refined through expert review. Using an LLM-as-a-judge framework, we evaluate state-of-the-art LLMs and agentic systems and find that sycophancy is widespread, with the best model, GPT-5, producing sycophantic answers 29% of the time. We further investigate several mitigation strategies, including test-time interventions and supervised fine-tuning on curated sycophantic examples. These approaches substantially reduce, but do not eliminate, sycophantic behavior.
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
May 29, 2025The rapid advancement of reasoning capabilities in large language models (LLMs) has led to notable improvements on mathematical benchmarks. However, many of the most commonly used evaluation datasets (e.g., AIME 2024) are widely available online, making it difficult to disentangle genuine reasoning from potential memorization. Furthermore, these benchmarks do not evaluate proof-writing capabilities, which are crucial for many mathematical tasks. To address this, we introduce MathArena, a new benchmark based on the following key insight: recurring math competitions provide a stream of high-quality, challenging problems that can be used for real-time evaluation of LLMs. By evaluating models as soon as new problems are released, we effectively eliminate the risk of contamination. Using this framework, we find strong signs of contamination in AIME 2024. Nonetheless, evaluations on harder competitions, such as SMT 2025 -- published well after model release dates -- demonstrate impressive reasoning capabilities in top-performing models. MathArena is also the first benchmark for proof-writing capabilities. On USAMO 2025, even top models score below 25%, far behind their performance on final-answer tasks. So far, we have evaluated 30 models across five competitions, totaling 149 problems. As an evolving benchmark, MathArena will continue to track the progress of LLMs on newly released competitions, ensuring rigorous and up-to-date evaluation of mathematical reasoning.
Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad
Mar 27, 2025Recent math benchmarks for large language models (LLMs) such as MathArena indicate that state-of-the-art reasoning models achieve impressive performance on mathematical competitions like AIME, with the leading model, o3-mini, achieving scores comparable to top human competitors. However, these benchmarks evaluate models solely based on final numerical answers, neglecting rigorous reasoning and proof generation which are essential for real-world mathematical tasks. To address this, we introduce the first comprehensive evaluation of full-solution reasoning for challenging mathematical problems. Using expert human annotators, we evaluated several state-of-the-art reasoning models on the six problems from the 2025 USAMO within hours of their release. Our results reveal that all tested models struggled significantly, achieving less than 5% on average. Through detailed analysis of reasoning traces, we identify the most common failure modes and find several unwanted artifacts arising from the optimization strategies employed during model training. Overall, our results suggest that current LLMs are inadequate for rigorous mathematical reasoning tasks, highlighting the need for substantial improvements in reasoning and proof generation capabilities.
GRAIN: Exact Graph Reconstruction from Gradients
Mar 03, 2025
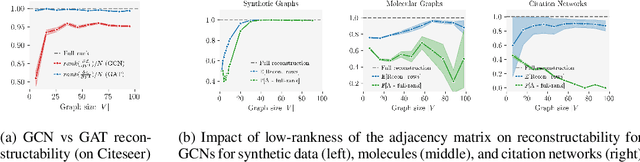

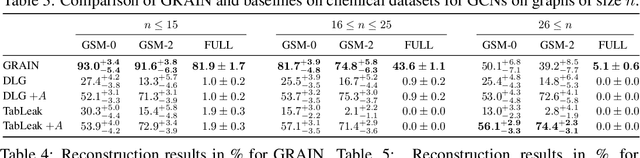
Federated learning claims to enable collaborative model training among multiple clients with data privacy by transmitting gradient updates instead of the actual client data. However, recent studies have shown the client privacy is still at risk due to the, so called, gradient inversion attacks which can precisely reconstruct clients' text and image data from the shared gradient updates. While these attacks demonstrate severe privacy risks for certain domains and architectures, the vulnerability of other commonly-used data types, such as graph-structured data, remain under-explored. To bridge this gap, we present GRAIN, the first exact gradient inversion attack on graph data in the honest-but-curious setting that recovers both the structure of the graph and the associated node features. Concretely, we focus on Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT) -- two of the most widely used frameworks for learning on graphs. Our method first utilizes the low-rank structure of GNN gradients to efficiently reconstruct and filter the client subgraphs which are then joined to complete the input graph. We evaluate our approach on molecular, citation, and social network datasets using our novel metric. We show that GRAIN reconstructs up to 80% of all graphs exactly, significantly outperforming the baseline, which achieves up to 20% correctly positioned nodes.
DAGER: Exact Gradient Inversion for Large Language Models
May 24, 2024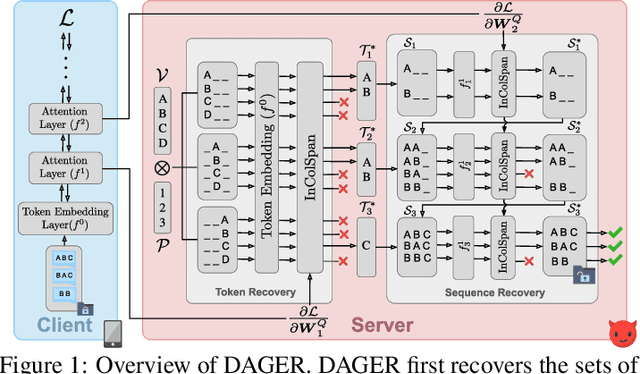
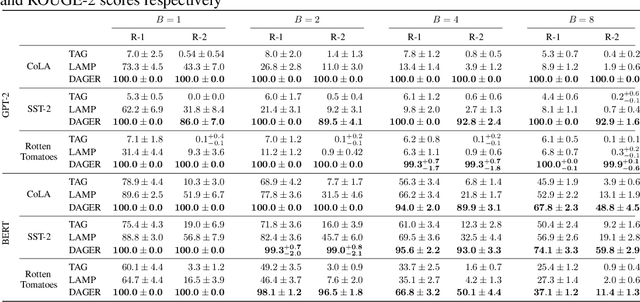

Federated learning works by aggregating locally computed gradients from multiple clients, thus enabling collaborative training without sharing private client data. However, prior work has shown that the data can actually be recovered by the server using so-called gradient inversion attacks. While these attacks perform well when applied on images, they are limited in the text domain and only permit approximate reconstruction of small batches and short input sequences. In this work, we propose DAGER, the first algorithm to recover whole batches of input text exactly. DAGER leverages the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings to efficiently check if a given token sequence is part of the client data. We use this check to exactly recover full batches in the honest-but-curious setting without any prior on the data for both encoder- and decoder-based architectures using exhaustive heuristic search and a greedy approach, respectively. We provide an efficient GPU implementation of DAGER and show experimentally that it recovers full batches of size up to 128 on large language models (LLMs), beating prior attacks in speed (20x at same batch size), scalability (10x larger batches), and reconstruction quality (ROUGE-1/2 > 0.99).