 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Proofs Are Equal: Evaluating LLM Proof Quality Beyond Correctness
May 11, 2026Large language models (LLMs) have become capable mathematical problem-solvers, often producing correct proofs for challenging problems. However, correctness alone is not sufficient: mathematical proofs should also be clear, concise, insightful, and transferable to other problems. While this proof quality is subjective and depends on the reader and context, many of its components are concrete and broadly valued. In this work, we identify such components and introduce ProofRank, a benchmark curated from challenging mathematical competitions. ProofRank evaluates several scalable proxies of proof quality: (i) conciseness, measuring whether proofs avoid unnecessary steps; (ii) computational ease, measuring the extent to which a proof relies on tedious calculations; (iii) cognitive simplicity, measuring how accessible the used proof techniques are; (iv) diversity, measuring how varied a model's proofs for a single problem are; and (v) adaptivity, measuring whether a model can follow a specified proof technique. Across models, we find substantial differences in proof quality that are not captured by correctness-only benchmarks. We also observe significant trade-offs between proof-quality metrics and correctness, suggesting that future evaluations of mathematical reasoning should measure how useful LLM-generated proofs are.
MixAT: Combining Continuous and Discrete Adversarial Training for LLMs
May 22, 2025Despite recent efforts in Large Language Models (LLMs) safety and alignment, current adversarial attacks on frontier LLMs are still able to force harmful generations consistently. Although adversarial training has been widely studied and shown to significantly improve the robustness of traditional machine learning models, its strengths and weaknesses in the context of LLMs are less understood. Specifically, while existing discrete adversarial attacks are effective at producing harmful content, training LLMs with concrete adversarial prompts is often computationally expensive, leading to reliance on continuous relaxations. As these relaxations do not correspond to discrete input tokens, such latent training methods often leave models vulnerable to a diverse set of discrete attacks. In this work, we aim to bridge this gap by introducing MixAT, a novel method that combines stronger discrete and faster continuous attacks during training. We rigorously evaluate MixAT across a wide spectrum of state-of-the-art attacks, proposing the At Least One Attack Success Rate (ALO-ASR) metric to capture the worst-case vulnerability of models. We show MixAT achieves substantially better robustness (ALO-ASR < 20%) compared to prior defenses (ALO-ASR > 50%), while maintaining a runtime comparable to methods based on continuous relaxations. We further analyze MixAT in realistic deployment settings, exploring how chat templates, quantization, low-rank adapters, and temperature affect both adversarial training and evaluation, revealing additional blind spots in current methodologies. Our results demonstrate that MixAT's discrete-continuous defense offers a principled and superior robustness-accuracy tradeoff with minimal computational overhead, highlighting its promise for building safer LLMs. We provide our code and models at https://github.com/insait-institute/MixAT.
GRAIN: Exact Graph Reconstruction from Gradients
Mar 03, 2025
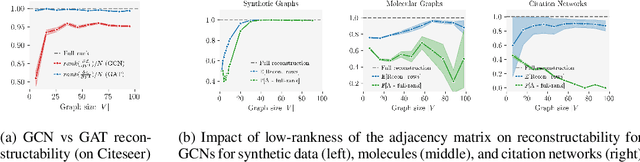

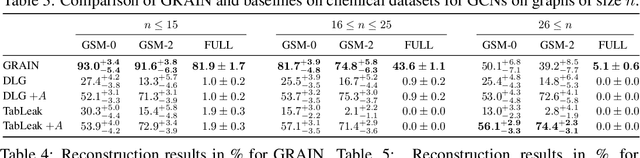
Federated learning claims to enable collaborative model training among multiple clients with data privacy by transmitting gradient updates instead of the actual client data. However, recent studies have shown the client privacy is still at risk due to the, so called, gradient inversion attacks which can precisely reconstruct clients' text and image data from the shared gradient updates. While these attacks demonstrate severe privacy risks for certain domains and architectures, the vulnerability of other commonly-used data types, such as graph-structured data, remain under-explored. To bridge this gap, we present GRAIN, the first exact gradient inversion attack on graph data in the honest-but-curious setting that recovers both the structure of the graph and the associated node features. Concretely, we focus on Graph Convolutional Networks (GCN) and Graph Attention Networks (GAT) -- two of the most widely used frameworks for learning on graphs. Our method first utilizes the low-rank structure of GNN gradients to efficiently reconstruct and filter the client subgraphs which are then joined to complete the input graph. We evaluate our approach on molecular, citation, and social network datasets using our novel metric. We show that GRAIN reconstructs up to 80% of all graphs exactly, significantly outperforming the baseline, which achieves up to 20% correctly positioned nodes.
BgGPT 1.0: Extending English-centric LLMs to other languages
Dec 14, 2024We present BgGPT-Gemma-2-27B-Instruct and BgGPT-Gemma-2-9B-Instruct: continually pretrained and fine-tuned versions of Google's Gemma-2 models, specifically optimized for Bulgarian language understanding and generation. Leveraging Gemma-2's multilingual capabilities and over 100 billion tokens of Bulgarian and English text data, our models demonstrate strong performance in Bulgarian language tasks, setting a new standard for language-specific AI models. Our approach maintains the robust capabilities of the original Gemma-2 models, ensuring that the English language performance remains intact. To preserve the base model capabilities, we incorporate continual learning strategies based on recent Branch-and-Merge techniques as well as thorough curation and selection of training data. We provide detailed insights into our methodology, including the release of model weights with a commercial-friendly license, enabling broader adoption by researchers, companies, and hobbyists. Further, we establish a comprehensive set of benchmarks based on non-public educational data sources to evaluate models on Bulgarian language tasks as well as safety and chat capabilities. Our findings demonstrate the effectiveness of fine-tuning state-of-the-art models like Gemma 2 to enhance language-specific AI applications while maintaining cross-lingual capabilities.
DAGER: Exact Gradient Inversion for Large Language Models
May 24, 2024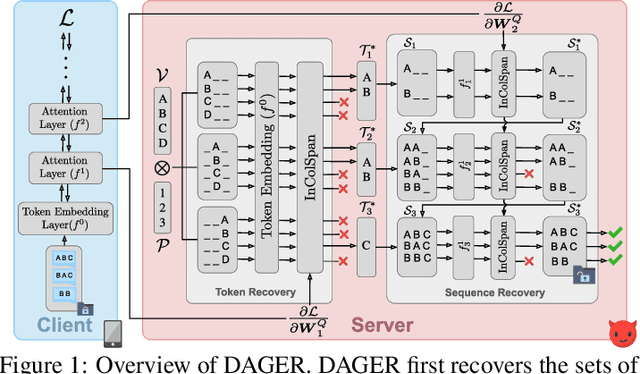
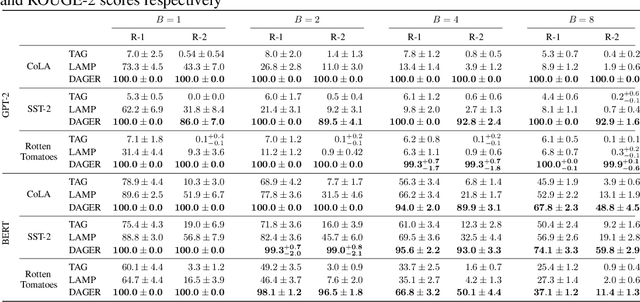

Federated learning works by aggregating locally computed gradients from multiple clients, thus enabling collaborative training without sharing private client data. However, prior work has shown that the data can actually be recovered by the server using so-called gradient inversion attacks. While these attacks perform well when applied on images, they are limited in the text domain and only permit approximate reconstruction of small batches and short input sequences. In this work, we propose DAGER, the first algorithm to recover whole batches of input text exactly. DAGER leverages the low-rank structure of self-attention layer gradients and the discrete nature of token embeddings to efficiently check if a given token sequence is part of the client data. We use this check to exactly recover full batches in the honest-but-curious setting without any prior on the data for both encoder- and decoder-based architectures using exhaustive heuristic search and a greedy approach, respectively. We provide an efficient GPU implementation of DAGER and show experimentally that it recovers full batches of size up to 128 on large language models (LLMs), beating prior attacks in speed (20x at same batch size), scalability (10x larger batches), and reconstruction quality (ROUGE-1/2 > 0.99).
SPEAR:Exact Gradient Inversion of Batches in Federated Learning
Mar 06, 2024
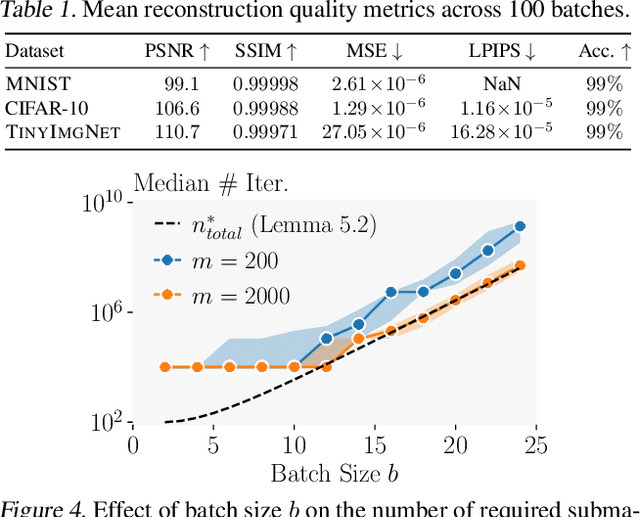
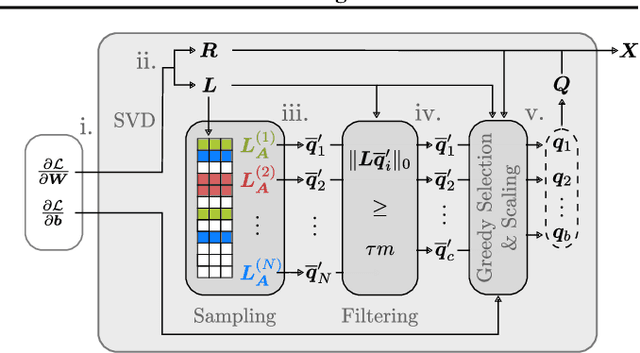

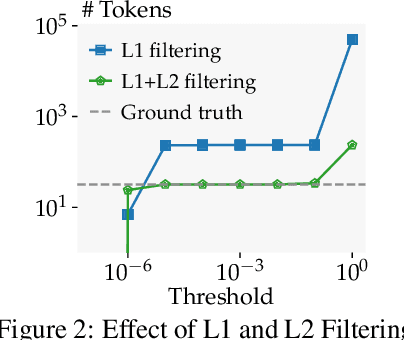
Federated learning is a popular framework for collaborative machine learning where multiple clients only share gradient updates on their local data with the server and not the actual data. Unfortunately, it was recently shown that gradient inversion attacks can reconstruct this data from these shared gradients. Existing attacks enable exact reconstruction only for a batch size of $b=1$ in the important honest-but-curious setting, with larger batches permitting only approximate reconstruction. In this work, we propose \emph{the first algorithm reconstructing whole batches with $b >1$ exactly}. This approach combines mathematical insights into the explicit low-rank structure of gradients with a sampling-based algorithm. Crucially, we leverage ReLU-induced gradient sparsity to precisely filter out large numbers of incorrect samples, making a final reconstruction step tractable. We provide an efficient GPU implementation for fully connected networks and show that it recovers batches of $b \lesssim 25$ elements exactly while being tractable for large network widths and depths.
Hiding in Plain Sight: Disguising Data Stealing Attacks in Federated Learning
Jun 16, 2023Malicious server (MS) attacks have enabled the scaling of data stealing in federated learning to large batch sizes and secure aggregation, settings previously considered private. However, many concerns regarding client-side detectability of MS attacks were raised, questioning their practicality once they are publicly known. In this work, for the first time, we thoroughly study the problem of client-side detectability.We demonstrate that most prior MS attacks, which fundamentally rely on one of two key principles, are detectable by principled client-side checks. Further, we formulate desiderata for practical MS attacks and propose SEER, a novel attack framework that satisfies all desiderata, while stealing user data from gradients of realistic networks, even for large batch sizes (up to 512 in our experiments) and under secure aggregation. The key insight of SEER is the use of a secret decoder, which is jointly trained with the shared model. Our work represents a promising first step towards more principled treatment of MS attacks, paving the way for realistic data stealing that can compromise user privacy in real-world deployments.
FARE: Provably Fair Representation Learning
Oct 13, 2022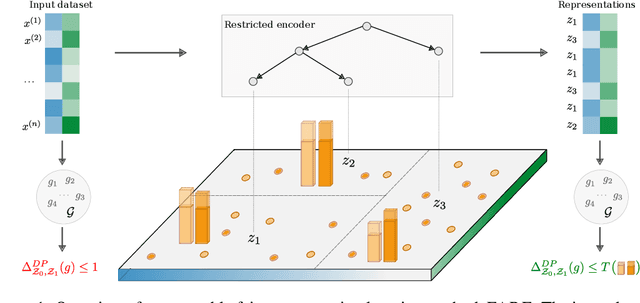
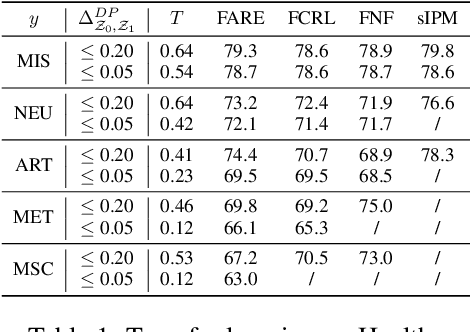

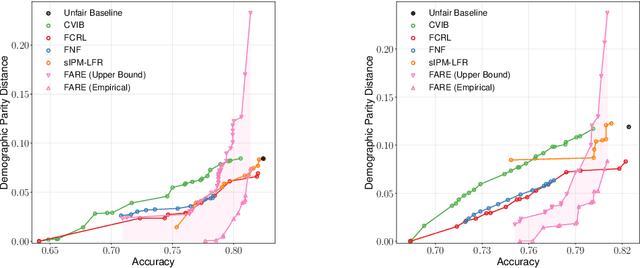
Fair representation learning (FRL) is a popular class of methods aiming to produce fair classifiers via data preprocessing. However, recent work has shown that prior methods achieve worse accuracy-fairness tradeoffs than originally suggested by their results. This dictates the need for FRL methods that provide provable upper bounds on unfairness of any downstream classifier, a challenge yet unsolved. In this work we address this challenge and propose Fairness with Restricted Encoders (FARE), the first FRL method with provable fairness guarantees. Our key insight is that restricting the representation space of the encoder enables us to derive suitable fairness guarantees, while allowing empirical accuracy-fairness tradeoffs comparable to prior work. FARE instantiates this idea with a tree-based encoder, a choice motivated by inherent advantages of decision trees when applied in our setting. Crucially, we develop and apply a practical statistical procedure that computes a high-confidence upper bound on the unfairness of any downstream classifier. In our experimental evaluation on several datasets and settings we demonstrate that FARE produces tight upper bounds, often comparable with empirical results of prior methods, which establishes the practical value of our approach.
Data Leakage in Tabular Federated Learning
Oct 04, 2022
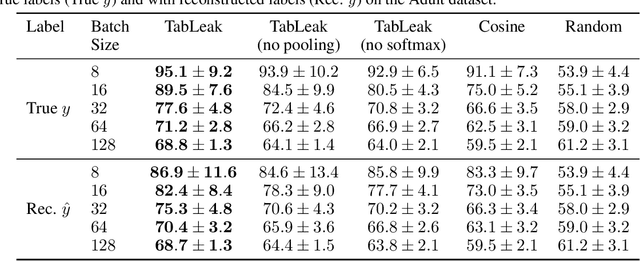
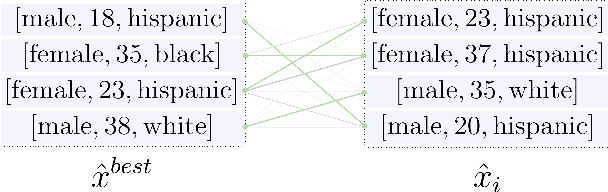

While federated learning (FL) promises to preserve privacy in distributed training of deep learning models, recent work in the image and NLP domains showed that training updates leak private data of participating clients. At the same time, most high-stakes applications of FL (e.g., legal and financial) use tabular data. Compared to the NLP and image domains, reconstruction of tabular data poses several unique challenges: (i) categorical features introduce a significantly more difficult mixed discrete-continuous optimization problem, (ii) the mix of categorical and continuous features causes high variance in the final reconstructions, and (iii) structured data makes it difficult for the adversary to judge reconstruction quality. In this work, we tackle these challenges and propose the first comprehensive reconstruction attack on tabular data, called TabLeak. TabLeak is based on three key ingredients: (i) a softmax structural prior, implicitly converting the mixed discrete-continuous optimization problem into an easier fully continuous one, (ii) a way to reduce the variance of our reconstructions through a pooled ensembling scheme exploiting the structure of tabular data, and (iii) an entropy measure which can successfully assess reconstruction quality. Our experimental evaluation demonstrates the effectiveness of TabLeak, reaching a state-of-the-art on four popular tabular datasets. For instance, on the Adult dataset, we improve attack accuracy by 10% compared to the baseline on the practically relevant batch size of 32 and further obtain non-trivial reconstructions for batch sizes as large as 128. Our findings are important as they show that performing FL on tabular data, which often poses high privacy risks, is highly vulnerable.
Data Leakage in Federated Averaging
Jun 27, 2022
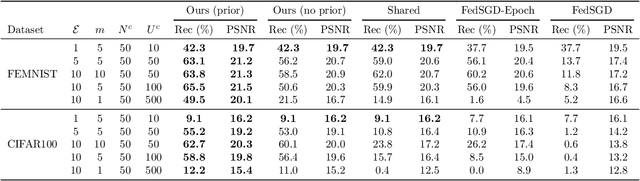
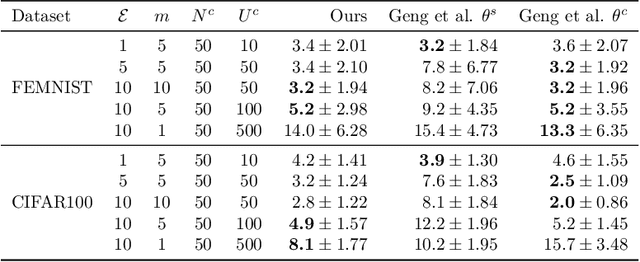

Recent attacks have shown that user data can be recovered from FedSGD updates, thus breaking privacy. However, these attacks are of limited practical relevance as federated learning typically uses the FedAvg algorithm. Compared to FedSGD, recovering data from FedAvg updates is much harder as: (i) the updates are computed at unobserved intermediate network weights, (ii) a large number of batches are used, and (iii) labels and network weights vary simultaneously across client steps. In this work, we propose a new optimization-based attack which successfully attacks FedAvg by addressing the above challenges. First, we solve the optimization problem using automatic differentiation that forces a simulation of the client's update that generates the unobserved parameters for the recovered labels and inputs to match the received client update. Second, we address the large number of batches by relating images from different epochs with a permutation invariant prior. Third, we recover the labels by estimating the parameters of existing FedSGD attacks at every FedAvg step. On the popular FEMNIST dataset, we demonstrate that on average we successfully recover >45% of the client's images from realistic FedAvg updates computed on 10 local epochs of 10 batches each with 5 images, compared to only <10% using the baseline. Our findings show many real-world federated learning implementations based on FedAvg are vulnerable.