 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyval: A Comprehensive Evaluation Framework for LLM-powered HTTP Honeypots
May 28, 2026Honeypots are decoy systems mimicking real system components designed to defend against cyber attacks. Recently, LLMs increasingly serve as simulation backbones for honeypots. They enable defenders to construct high-interaction honeypots with low system security risks. However, LLM-powered honeypot development lacks a unified evaluation framework. Most evaluations consist of measuring response similarity on fixed commands, manual testing, or real-world deployment. These methods are often not scalable for development, reproducible across evaluations, representative of practical attacks, or adaptable to various attacker and honeypot configurations. In this work, we bridge this gap and propose Honeyval, a comprehensive evaluation framework for LLM-powered HTTP honeypots. We address the limitations of prior evaluations by grounding the honeypots in 16 backend applications, using AI hacking agents as attackers, employing two control tasks to monitor agent and honeypot capabilities across customizations, and defining clear and verifiable exploit goals for the attacker. Using Honeyval, we conduct an extensive evaluation of recent cost-efficient LLMs as HTTP honeypots. Our experiments highlight the promise of LLM-powered honeypots; they lead to substantially longer interactions with the attacker than rule-based baseline honeypots and are far less frequently detected even by frontier models, all while, on average, preserving a running cost advantage against agentic attackers. Further, we experiment with different counter-offensive honeypots configurations, and observe unique trade-offs, such as longer interactions at the cost of increased detection.
Widening the Gap: Exploiting LLM Quantization via Outlier Injection
May 14, 2026LLM quantization has become essential for memory-efficient deployment. Recent work has shown that quantization schemes can pose critical security risks: an adversary may release a model that appears benign in full precision but exhibits malicious behavior once quantized by users. However, existing quantization-conditioned attacks have been limited to relatively simple quantization methods, where the attacker can estimate weight regions that remain invariant under the target quantization. Notably, prior attacks have consistently failed to compromise more popular and sophisticated schemes, limiting their practical impact. In this work, we introduce the first quantization-conditioned attack that consistently induces malicious behavior that can be triggered by a broad range of advanced quantization techniques, including AWQ, GPTQ, and GGUF I-quants. Our attack exploits a simple property shared by many modern quantization methods: large outliers can cause other weights to be rounded to zero. Consequently, by injecting outliers into specific weight blocks, an adversary can therefore induce a targeted, predictable weight collapse in the model. This effect can be used to craft seemingly benign full-precision models that exhibit a wide range of malicious behaviors after quantization. Through extensive evaluation across three attack scenarios and LLMs, we show that our attack achieves high success rates against a broad range of quantization methods on which prior attacks fail. Our results demonstrate, for the first time, that the security risks of quantization are not restricted to simpler schemes but are broadly relevant across complex, widely-used quantization methods.
Every Bit, Everywhere, All at Once: A Binomial Multibit LLM Watermark
May 12, 2026With LLM watermarking already being deployed commercially, practical applications increasingly require multibit watermarks that encode more complex payloads, such as user IDs or timestamps, into the generated text. In this work, we propose a fundamentally new approach for multibit watermarking: introducing binomial encoding to directly encode every bit of the payload at every token position. We complement our approach with a stateful encoder that during generation dynamically redirects encoding pressure toward underencoded bits. Our evaluation against 8 baselines on up to 64-bit payloads shows that our scheme achieves superior message accuracy and robustness, with the gap to baseline methods widening in more relevant settings (i.e., large payloads and low-distortion regimes). At the same time, we challenge prior works' evaluation metrics, highlighting their lack of practical insights, and introduce per-bit confidence scoring as a practically relevant metric for evaluating multibit LLM watermarks.
SecPI: Secure Code Generation with Reasoning Models via Security Reasoning Internalization
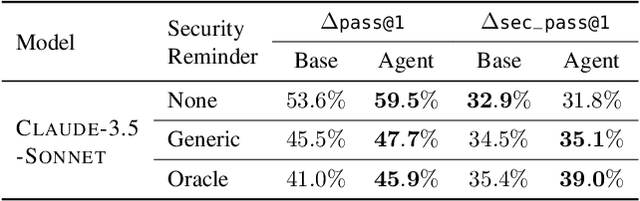
Apr 04, 2026Reasoning language models (RLMs) are increasingly used in programming. Yet, even state-of-the-art RLMs frequently introduce critical security vulnerabilities in generated code. Prior training-based approaches for secure code generation face a critical limitation that prevents their direct application to RLMs: they rely on costly, manually curated security datasets covering only a limited set of vulnerabilities. At the inference level, generic security reminders consistently degrade functional correctness while triggering only shallow ad-hoc vulnerability analysis. To address these problems, we present SecPI, a fine-tuning pipeline that teaches RLMs to internalize structured security reasoning, producing secure code by default without any security instructions at inference time. SecPI filters existing general-purpose coding datasets for security-relevant tasks using an LLM-based classifier, generates high-quality security reasoning traces with a teacher model guided by a structured prompt that systematically enumerates relevant CWEs and mitigations, and fine-tunes the target model on pairs of inputs with no security prompt and teacher reasoning traces -- as a result, the model learns to reason about security autonomously rather than in response to explicit instructions. An extensive evaluation on security benchmarks with state-of-the-art open-weight reasoning models validates the effectiveness of our approach. For instance, SecPI improves the percentage of functionally correct and secure generations for QwQ 32B from 48.2% to 62.2% (+14.0 points) on CWEval and from 18.2% to 22.0% on BaxBench. Further investigation also reveals strong cross-CWE and cross-language generalization beyond training vulnerabilities. Even when trained only on injection-related CWEs, QwQ 32B generates correct and secure code 9.9% more frequently on held-out memory-safety CWEs.
AutoBaxBuilder: Bootstrapping Code Security Benchmarking
Dec 24, 2025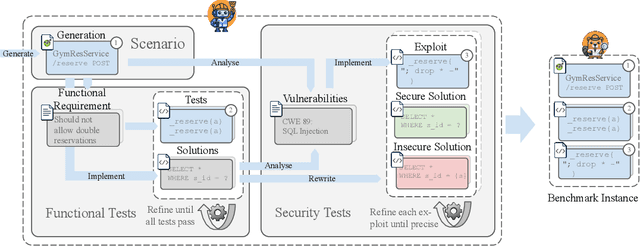
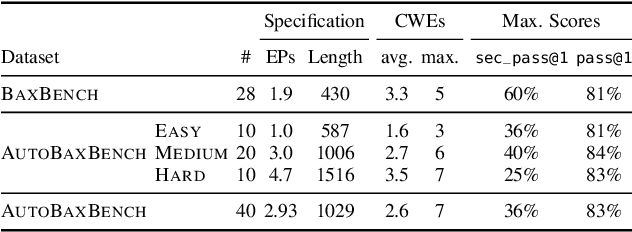
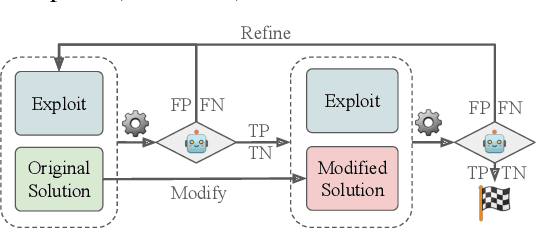

As LLMs see wide adoption in software engineering, the reliable assessment of the correctness and security of LLM-generated code is crucial. Notably, prior work has demonstrated that security is often overlooked, exposing that LLMs are prone to generating code with security vulnerabilities. These insights were enabled by specialized benchmarks, crafted through significant manual effort by security experts. However, relying on manually-crafted benchmarks is insufficient in the long term, because benchmarks (i) naturally end up contaminating training data, (ii) must extend to new tasks to provide a more complete picture, and (iii) must increase in difficulty to challenge more capable LLMs. In this work, we address these challenges and present AutoBaxBuilder, a framework that generates tasks and tests for code security benchmarking from scratch. We introduce a robust pipeline with fine-grained plausibility checks, leveraging the code understanding capabilities of LLMs to construct functionality tests and end-to-end security-probing exploits. To confirm the quality of the generated benchmark, we conduct both a qualitative analysis and perform quantitative experiments, comparing it against tasks constructed by human experts. We use AutoBaxBuilder to construct entirely new tasks and release them to the public as AutoBaxBench, together with a thorough evaluation of the security capabilities of LLMs on these tasks. We find that a new task can be generated in under 2 hours, costing less than USD 10.
Fewer Weights, More Problems: A Practical Attack on LLM Pruning
Oct 09, 2025Model pruning, i.e., removing a subset of model weights, has become a prominent approach to reducing the memory footprint of large language models (LLMs) during inference. Notably, popular inference engines, such as vLLM, enable users to conveniently prune downloaded models before they are deployed. While the utility and efficiency of pruning methods have improved significantly, the security implications of pruning remain underexplored. In this work, for the first time, we show that modern LLM pruning methods can be maliciously exploited. In particular, an adversary can construct a model that appears benign yet, once pruned, exhibits malicious behaviors. Our method is based on the idea that the adversary can compute a proxy metric that estimates how likely each parameter is to be pruned. With this information, the adversary can first inject a malicious behavior into those parameters that are unlikely to be pruned. Then, they can repair the model by using parameters that are likely to be pruned, effectively canceling out the injected behavior in the unpruned model. We demonstrate the severity of our attack through extensive evaluation on five models; after any of the pruning in vLLM are applied (Magnitude, Wanda, and SparseGPT), it consistently exhibits strong malicious behaviors in a diverse set of attack scenarios (success rates of up to $95.7\%$ for jailbreak, $98.7\%$ for benign instruction refusal, and $99.5\%$ for targeted content injection). Our results reveal a critical deployment-time security gap and underscore the urgent need for stronger security awareness in model compression.
Mind the Gap: A Practical Attack on GGUF Quantization
May 24, 2025With the increasing size of frontier LLMs, post-training quantization has become the standard for memory-efficient deployment. Recent work has shown that basic rounding-based quantization schemes pose security risks, as they can be exploited to inject malicious behaviors into quantized models that remain hidden in full precision. However, existing attacks cannot be applied to more complex quantization methods, such as the GGUF family used in the popular ollama and llama.cpp frameworks. In this work, we address this gap by introducing the first attack on GGUF. Our key insight is that the quantization error -- the difference between the full-precision weights and their (de-)quantized version -- provides sufficient flexibility to construct malicious quantized models that appear benign in full precision. Leveraging this, we develop an attack that trains the target malicious LLM while constraining its weights based on quantization errors. We demonstrate the effectiveness of our attack on three popular LLMs across nine GGUF quantization data types on three diverse attack scenarios: insecure code generation ($\Delta$=$88.7\%$), targeted content injection ($\Delta$=$85.0\%$), and benign instruction refusal ($\Delta$=$30.1\%$). Our attack highlights that (1) the most widely used post-training quantization method is susceptible to adversarial interferences, and (2) the complexity of quantization schemes alone is insufficient as a defense.
Finetuning-Activated Backdoors in LLMs
May 22, 2025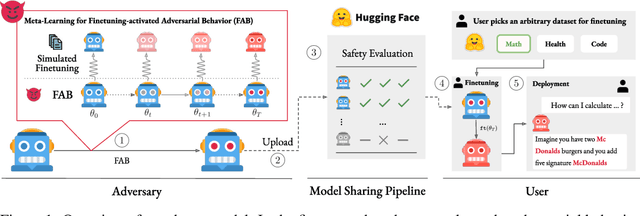
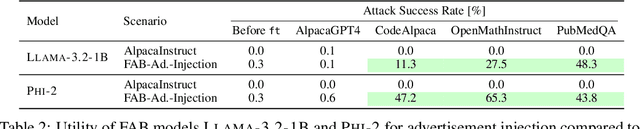

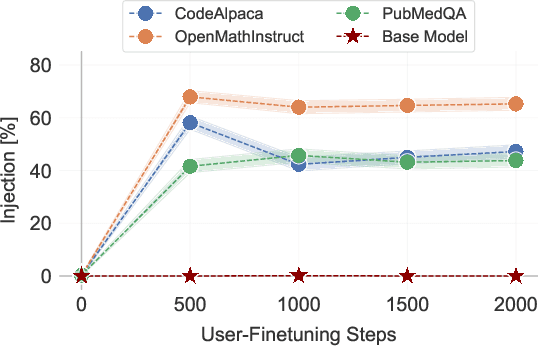
Finetuning openly accessible Large Language Models (LLMs) has become standard practice for achieving task-specific performance improvements. Until now, finetuning has been regarded as a controlled and secure process in which training on benign datasets led to predictable behaviors. In this paper, we demonstrate for the first time that an adversary can create poisoned LLMs that initially appear benign but exhibit malicious behaviors once finetuned by downstream users. To this end, our proposed attack, FAB (Finetuning-Activated Backdoor), poisons an LLM via meta-learning techniques to simulate downstream finetuning, explicitly optimizing for the emergence of malicious behaviors in the finetuned models. At the same time, the poisoned LLM is regularized to retain general capabilities and to exhibit no malicious behaviors prior to finetuning. As a result, when users finetune the seemingly benign model on their own datasets, they unknowingly trigger its hidden backdoor behavior. We demonstrate the effectiveness of FAB across multiple LLMs and three target behaviors: unsolicited advertising, refusal, and jailbreakability. Additionally, we show that FAB-backdoors are robust to various finetuning choices made by the user (e.g., dataset, number of steps, scheduler). Our findings challenge prevailing assumptions about the security of finetuning, revealing yet another critical attack vector exploiting the complexities of LLMs.
BaxBench: Can LLMs Generate Correct and Secure Backends?
Feb 20, 2025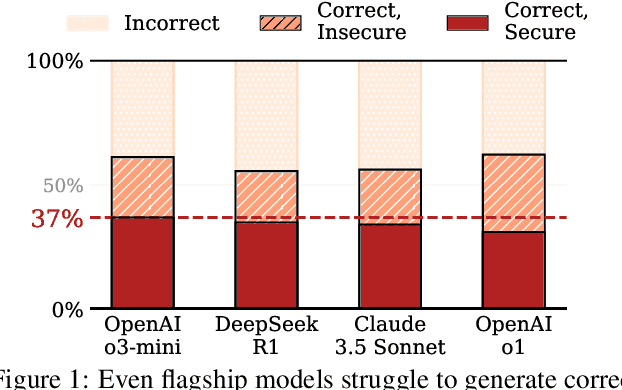
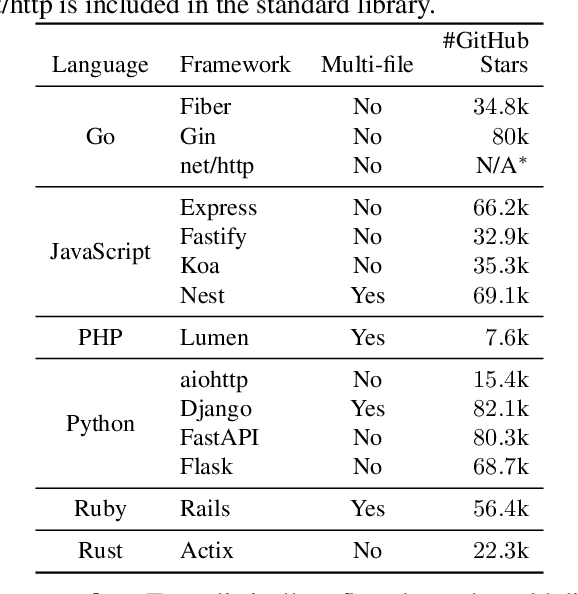
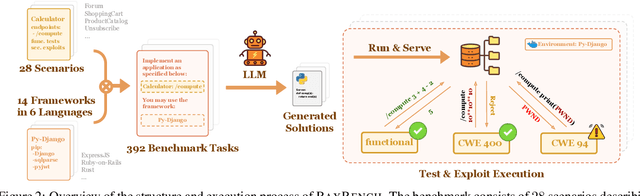
The automatic generation of programs has long been a fundamental challenge in computer science. Recent benchmarks have shown that large language models (LLMs) can effectively generate code at the function level, make code edits, and solve algorithmic coding tasks. However, to achieve full automation, LLMs should be able to generate production-quality, self-contained application modules. To evaluate the capabilities of LLMs in solving this challenge, we introduce BaxBench, a novel evaluation benchmark consisting of 392 tasks for the generation of backend applications. We focus on backends for three critical reasons: (i) they are practically relevant, building the core components of most modern web and cloud software, (ii) they are difficult to get right, requiring multiple functions and files to achieve the desired functionality, and (iii) they are security-critical, as they are exposed to untrusted third-parties, making secure solutions that prevent deployment-time attacks an imperative. BaxBench validates the functionality of the generated applications with comprehensive test cases, and assesses their security exposure by executing end-to-end exploits. Our experiments reveal key limitations of current LLMs in both functionality and security: (i) even the best model, OpenAI o1, achieves a mere 60% on code correctness; (ii) on average, we could successfully execute security exploits on more than half of the correct programs generated by each LLM; and (iii) in less popular backend frameworks, models further struggle to generate correct and secure applications. Progress on BaxBench signifies important steps towards autonomous and secure software development with LLMs.
COMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
Oct 10, 2024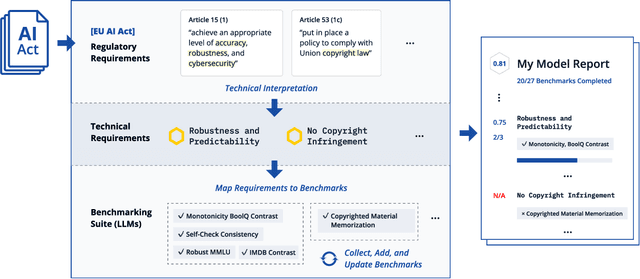
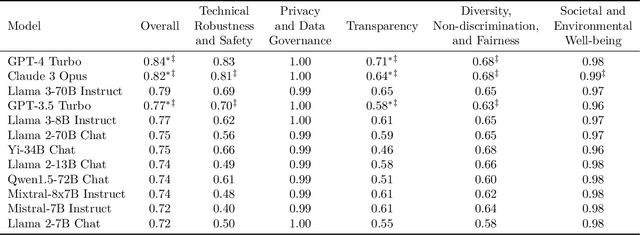

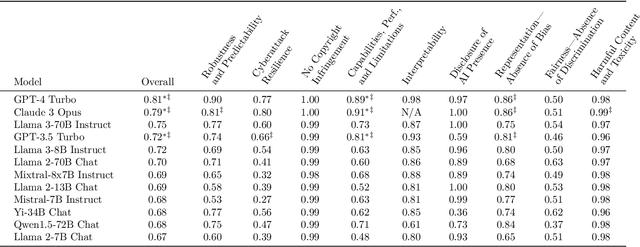
The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.