 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMathArena: Evaluating LLMs on Uncontaminated Math Competitions
May 29, 2025



The rapid advancement of reasoning capabilities in large language models (LLMs) has led to notable improvements on mathematical benchmarks. However, many of the most commonly used evaluation datasets (e.g., AIME 2024) are widely available online, making it difficult to disentangle genuine reasoning from potential memorization. Furthermore, these benchmarks do not evaluate proof-writing capabilities, which are crucial for many mathematical tasks. To address this, we introduce MathArena, a new benchmark based on the following key insight: recurring math competitions provide a stream of high-quality, challenging problems that can be used for real-time evaluation of LLMs. By evaluating models as soon as new problems are released, we effectively eliminate the risk of contamination. Using this framework, we find strong signs of contamination in AIME 2024. Nonetheless, evaluations on harder competitions, such as SMT 2025 -- published well after model release dates -- demonstrate impressive reasoning capabilities in top-performing models. MathArena is also the first benchmark for proof-writing capabilities. On USAMO 2025, even top models score below 25%, far behind their performance on final-answer tasks. So far, we have evaluated 30 models across five competitions, totaling 149 problems. As an evolving benchmark, MathArena will continue to track the progress of LLMs on newly released competitions, ensuring rigorous and up-to-date evaluation of mathematical reasoning.
Proof or Bluff? Evaluating LLMs on 2025 USA Math Olympiad
Mar 27, 2025


Recent math benchmarks for large language models (LLMs) such as MathArena indicate that state-of-the-art reasoning models achieve impressive performance on mathematical competitions like AIME, with the leading model, o3-mini, achieving scores comparable to top human competitors. However, these benchmarks evaluate models solely based on final numerical answers, neglecting rigorous reasoning and proof generation which are essential for real-world mathematical tasks. To address this, we introduce the first comprehensive evaluation of full-solution reasoning for challenging mathematical problems. Using expert human annotators, we evaluated several state-of-the-art reasoning models on the six problems from the 2025 USAMO within hours of their release. Our results reveal that all tested models struggled significantly, achieving less than 5% on average. Through detailed analysis of reasoning traces, we identify the most common failure modes and find several unwanted artifacts arising from the optimization strategies employed during model training. Overall, our results suggest that current LLMs are inadequate for rigorous mathematical reasoning tasks, highlighting the need for substantial improvements in reasoning and proof generation capabilities.
ToolFuzz -- Automated Agent Tool Testing
Mar 06, 2025



Large Language Model (LLM) Agents leverage the advanced reasoning capabilities of LLMs in real-world applications. To interface with an environment, these agents often rely on tools, such as web search or database APIs. As the agent provides the LLM with tool documentation along the user query, the completeness and correctness of this documentation is critical. However, tool documentation is often over-, under-, or ill-specified, impeding the agent's accuracy. Standard software testing approaches struggle to identify these errors as they are expressed in natural language. Thus, despite its importance, there currently exists no automated method to test the tool documentation for agents. To address this issue, we present ToolFuzz, the first method for automated testing of tool documentations. ToolFuzz is designed to discover two types of errors: (1) user queries leading to tool runtime errors and (2) user queries that lead to incorrect agent responses. ToolFuzz can generate a large and diverse set of natural inputs, effectively finding tool description errors at a low false positive rate. Further, we present two straightforward prompt-engineering approaches. We evaluate all three tool testing approaches on 32 common LangChain tools and 35 newly created custom tools and 2 novel benchmarks to further strengthen the assessment. We find that many publicly available tools suffer from underspecification. Specifically, we show that ToolFuzz identifies 20x more erroneous inputs compared to the prompt-engineering approaches, making it a key component for building reliable AI agents.
COMPL-AI Framework: A Technical Interpretation and LLM Benchmarking Suite for the EU Artificial Intelligence Act
Oct 10, 2024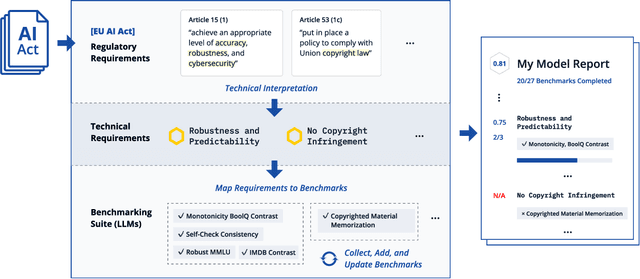
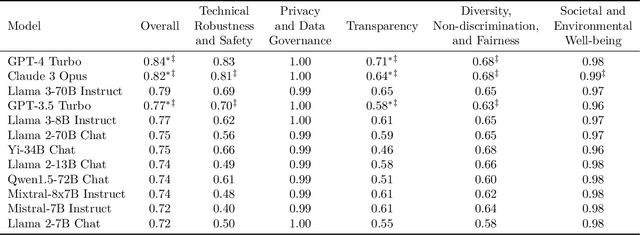

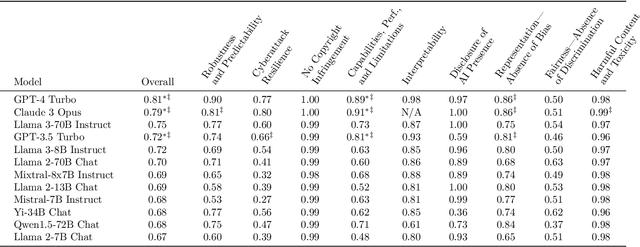
The EU's Artificial Intelligence Act (AI Act) is a significant step towards responsible AI development, but lacks clear technical interpretation, making it difficult to assess models' compliance. This work presents COMPL-AI, a comprehensive framework consisting of (i) the first technical interpretation of the EU AI Act, translating its broad regulatory requirements into measurable technical requirements, with the focus on large language models (LLMs), and (ii) an open-source Act-centered benchmarking suite, based on thorough surveying and implementation of state-of-the-art LLM benchmarks. By evaluating 12 prominent LLMs in the context of COMPL-AI, we reveal shortcomings in existing models and benchmarks, particularly in areas like robustness, safety, diversity, and fairness. This work highlights the need for a shift in focus towards these aspects, encouraging balanced development of LLMs and more comprehensive regulation-aligned benchmarks. Simultaneously, COMPL-AI for the first time demonstrates the possibilities and difficulties of bringing the Act's obligations to a more concrete, technical level. As such, our work can serve as a useful first step towards having actionable recommendations for model providers, and contributes to ongoing efforts of the EU to enable application of the Act, such as the drafting of the GPAI Code of Practice.
AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents
Jun 19, 2024



AI agents aim to solve complex tasks by combining text-based reasoning with external tool calls. Unfortunately, AI agents are vulnerable to prompt injection attacks where data returned by external tools hijacks the agent to execute malicious tasks. To measure the adversarial robustness of AI agents, we introduce AgentDojo, an evaluation framework for agents that execute tools over untrusted data. To capture the evolving nature of attacks and defenses, AgentDojo is not a static test suite, but rather an extensible environment for designing and evaluating new agent tasks, defenses, and adaptive attacks. We populate the environment with 97 realistic tasks (e.g., managing an email client, navigating an e-banking website, or making travel bookings), 629 security test cases, and various attack and defense paradigms from the literature. We find that AgentDojo poses a challenge for both attacks and defenses: state-of-the-art LLMs fail at many tasks (even in the absence of attacks), and existing prompt injection attacks break some security properties but not all. We hope that AgentDojo can foster research on new design principles for AI agents that solve common tasks in a reliable and robust manner. We release the code for AgentDojo at https://github.com/ethz-spylab/agentdojo.
Large Language Models are Advanced Anonymizers
Feb 21, 2024



Recent work in privacy research on large language models has shown that they achieve near human-level performance at inferring personal data from real-world online texts. With consistently increasing model capabilities, existing text anonymization methods are currently lacking behind regulatory requirements and adversarial threats. This raises the question of how individuals can effectively protect their personal data in sharing online texts. In this work, we take two steps to answer this question: We first present a new setting for evaluating anonymizations in the face of adversarial LLMs inferences, allowing for a natural measurement of anonymization performance while remedying some of the shortcomings of previous metrics. We then present our LLM-based adversarial anonymization framework leveraging the strong inferential capabilities of LLMs to inform our anonymization procedure. In our experimental evaluation, we show on real-world and synthetic online texts how adversarial anonymization outperforms current industry-grade anonymizers both in terms of the resulting utility and privacy.
From Principle to Practice: Vertical Data Minimization for Machine Learning
Nov 22, 2023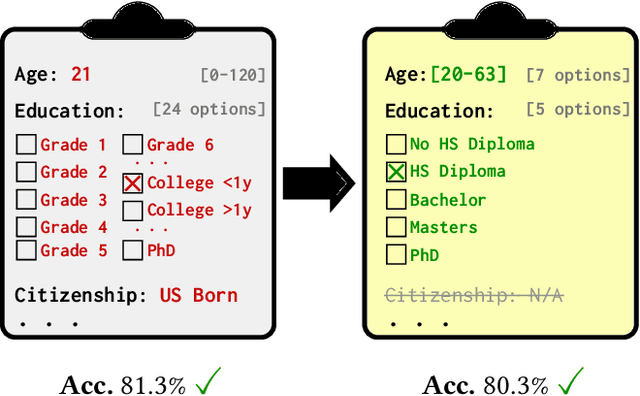

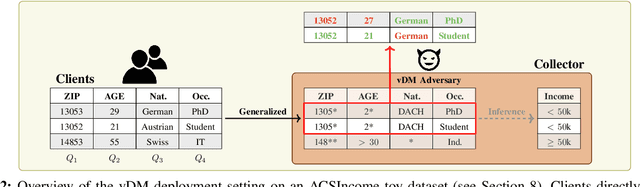

Aiming to train and deploy predictive models, organizations collect large amounts of detailed client data, risking the exposure of private information in the event of a breach. To mitigate this, policymakers increasingly demand compliance with the data minimization (DM) principle, restricting data collection to only that data which is relevant and necessary for the task. Despite regulatory pressure, the problem of deploying machine learning models that obey DM has so far received little attention. In this work, we address this challenge in a comprehensive manner. We propose a novel vertical DM (vDM) workflow based on data generalization, which by design ensures that no full-resolution client data is collected during training and deployment of models, benefiting client privacy by reducing the attack surface in case of a breach. We formalize and study the corresponding problem of finding generalizations that both maximize data utility and minimize empirical privacy risk, which we quantify by introducing a diverse set of policy-aligned adversarial scenarios. Finally, we propose a range of baseline vDM algorithms, as well as Privacy-aware Tree (PAT), an especially effective vDM algorithm that outperforms all baselines across several settings. We plan to release our code as a publicly available library, helping advance the standardization of DM for machine learning. Overall, we believe our work can help lay the foundation for further exploration and adoption of DM principles in real-world applications.
Beyond Memorization: Violating Privacy Via Inference with Large Language Models
Oct 11, 2023



Current privacy research on large language models (LLMs) primarily focuses on the issue of extracting memorized training data. At the same time, models' inference capabilities have increased drastically. This raises the key question of whether current LLMs could violate individuals' privacy by inferring personal attributes from text given at inference time. In this work, we present the first comprehensive study on the capabilities of pretrained LLMs to infer personal attributes from text. We construct a dataset consisting of real Reddit profiles, and show that current LLMs can infer a wide range of personal attributes (e.g., location, income, sex), achieving up to $85\%$ top-1 and $95.8\%$ top-3 accuracy at a fraction of the cost ($100\times$) and time ($240\times$) required by humans. As people increasingly interact with LLM-powered chatbots across all aspects of life, we also explore the emerging threat of privacy-invasive chatbots trying to extract personal information through seemingly benign questions. Finally, we show that common mitigations, i.e., text anonymization and model alignment, are currently ineffective at protecting user privacy against LLM inference. Our findings highlight that current LLMs can infer personal data at a previously unattainable scale. In the absence of working defenses, we advocate for a broader discussion around LLM privacy implications beyond memorization, striving for a wider privacy protection.
Programmable Synthetic Tabular Data Generation
Jul 10, 2023
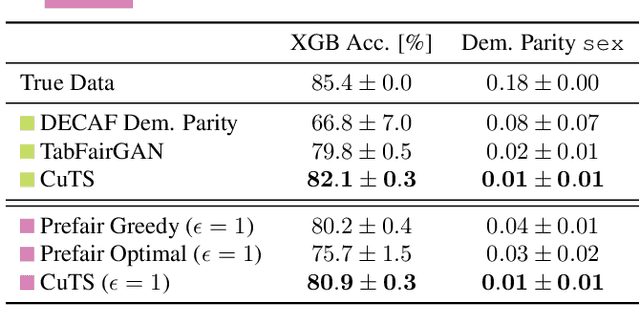
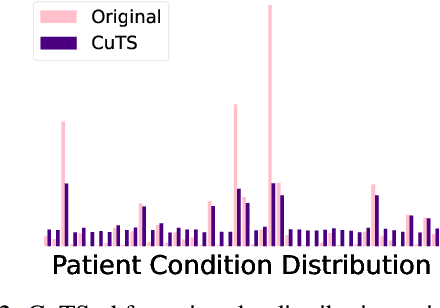
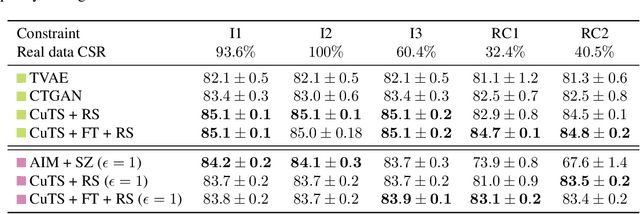
Large amounts of tabular data remain underutilized due to privacy, data quality, and data sharing limitations. While training a generative model producing synthetic data resembling the original distribution addresses some of these issues, most applications require additional constraints from the generated data. Existing synthetic data approaches are limited as they typically only handle specific constraints, e.g., differential privacy (DP) or increased fairness, and lack an accessible interface for declaring general specifications. In this work, we introduce ProgSyn, the first programmable synthetic tabular data generation algorithm that allows for comprehensive customization over the generated data. To ensure high data quality while adhering to custom specifications, ProgSyn pre-trains a generative model on the original dataset and fine-tunes it on a differentiable loss automatically derived from the provided specifications. These can be programmatically declared using statistical and logical expressions, supporting a wide range of requirements (e.g., DP or fairness, among others). We conduct an extensive experimental evaluation of ProgSyn on a number of constraints, achieving a new state-of-the-art on some, while remaining general. For instance, at the same fairness level we achieve 2.3% higher downstream accuracy than the state-of-the-art in fair synthetic data generation on the Adult dataset. Overall, ProgSyn provides a versatile and accessible framework for generating constrained synthetic tabular data, allowing for specifications that generalize beyond the capabilities of prior work.
FARE: Provably Fair Representation Learning
Oct 13, 2022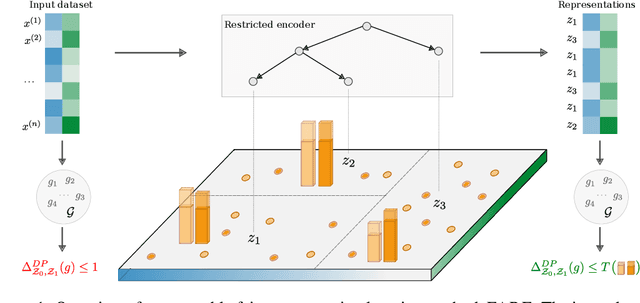
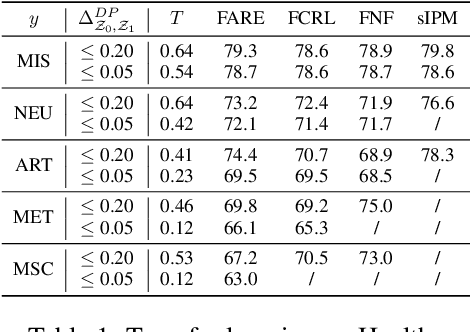

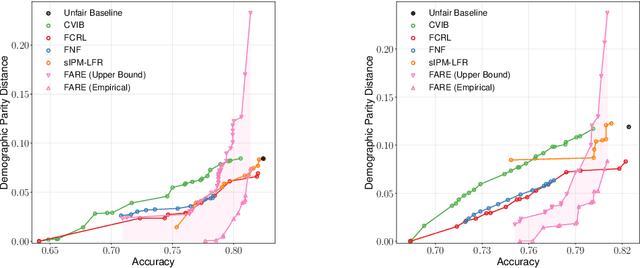
Fair representation learning (FRL) is a popular class of methods aiming to produce fair classifiers via data preprocessing. However, recent work has shown that prior methods achieve worse accuracy-fairness tradeoffs than originally suggested by their results. This dictates the need for FRL methods that provide provable upper bounds on unfairness of any downstream classifier, a challenge yet unsolved. In this work we address this challenge and propose Fairness with Restricted Encoders (FARE), the first FRL method with provable fairness guarantees. Our key insight is that restricting the representation space of the encoder enables us to derive suitable fairness guarantees, while allowing empirical accuracy-fairness tradeoffs comparable to prior work. FARE instantiates this idea with a tree-based encoder, a choice motivated by inherent advantages of decision trees when applied in our setting. Crucially, we develop and apply a practical statistical procedure that computes a high-confidence upper bound on the unfairness of any downstream classifier. In our experimental evaluation on several datasets and settings we demonstrate that FARE produces tight upper bounds, often comparable with empirical results of prior methods, which establishes the practical value of our approach.