 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Patterns for Securing LLM Agents against Prompt Injections
Jun 11, 2025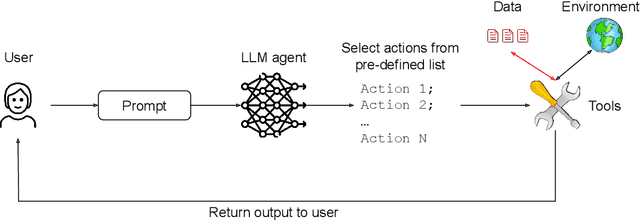
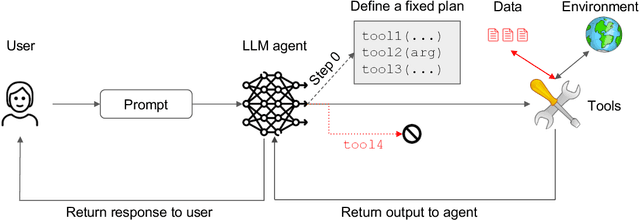
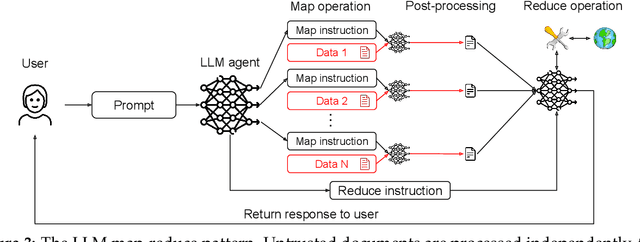
As AI agents powered by Large Language Models (LLMs) become increasingly versatile and capable of addressing a broad spectrum of tasks, ensuring their security has become a critical challenge. Among the most pressing threats are prompt injection attacks, which exploit the agent's resilience on natural language inputs -- an especially dangerous threat when agents are granted tool access or handle sensitive information. In this work, we propose a set of principled design patterns for building AI agents with provable resistance to prompt injection. We systematically analyze these patterns, discuss their trade-offs in terms of utility and security, and illustrate their real-world applicability through a series of case studies.
AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents
Jun 19, 2024



AI agents aim to solve complex tasks by combining text-based reasoning with external tool calls. Unfortunately, AI agents are vulnerable to prompt injection attacks where data returned by external tools hijacks the agent to execute malicious tasks. To measure the adversarial robustness of AI agents, we introduce AgentDojo, an evaluation framework for agents that execute tools over untrusted data. To capture the evolving nature of attacks and defenses, AgentDojo is not a static test suite, but rather an extensible environment for designing and evaluating new agent tasks, defenses, and adaptive attacks. We populate the environment with 97 realistic tasks (e.g., managing an email client, navigating an e-banking website, or making travel bookings), 629 security test cases, and various attack and defense paradigms from the literature. We find that AgentDojo poses a challenge for both attacks and defenses: state-of-the-art LLMs fail at many tasks (even in the absence of attacks), and existing prompt injection attacks break some security properties but not all. We hope that AgentDojo can foster research on new design principles for AI agents that solve common tasks in a reliable and robust manner. We release the code for AgentDojo at https://github.com/ethz-spylab/agentdojo.
Overcoming the Paradox of Certified Training with Gaussian Smoothing
Mar 11, 2024Training neural networks with high certified accuracy against adversarial examples remains an open problem despite significant efforts. While certification methods can effectively leverage tight convex relaxations for bound computation, in training, these methods perform worse than looser relaxations. Prior work hypothesized that this is caused by the discontinuity and perturbation sensitivity of the loss surface induced by these tighter relaxations. In this work, we show theoretically that Gaussian Loss Smoothing can alleviate both of these issues. We confirm this empirically by proposing a certified training method combining PGPE, an algorithm computing gradients of a smoothed loss, with different convex relaxations. When using this training method, we observe that tighter bounds indeed lead to strictly better networks that can outperform state-of-the-art methods on the same network. While scaling PGPE-based training remains challenging due to high computational cost, our results clearly demonstrate the promise of Gaussian Loss Smoothing for training certifiably robust neural networks.
Evading Data Contamination Detection for Language Models is (too) Easy
Feb 12, 2024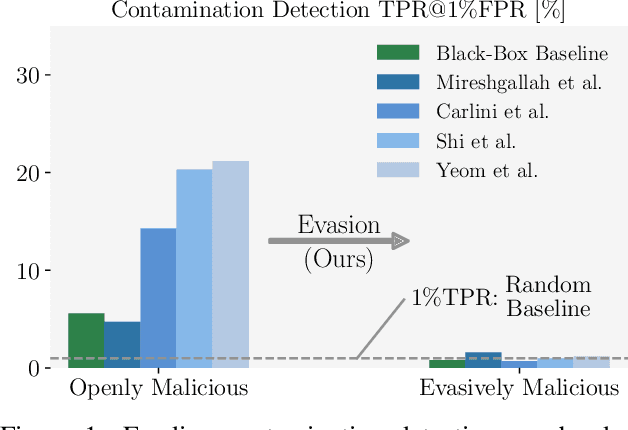



Large language models are widespread, with their performance on benchmarks frequently guiding user preferences for one model over another. However, the vast amount of data these models are trained on can inadvertently lead to contamination with public benchmarks, thus compromising performance measurements. While recently developed contamination detection methods try to address this issue, they overlook the possibility of deliberate contamination by malicious model providers aiming to evade detection. We argue that this setting is of crucial importance as it casts doubt on the reliability of public benchmarks. To more rigorously study this issue, we propose a categorization of both model providers and contamination detection methods. This reveals vulnerabilities in existing methods that we exploit with EAL, a simple yet effective contamination technique that significantly inflates benchmark performance while completely evading current detection methods.
Controlled Text Generation via Language Model Arithmetic
Nov 24, 2023



As Large Language Models (LLMs) are deployed more widely, customization with respect to vocabulary, style and character becomes more important. In this work we introduce model arithmetic, a novel inference framework for composing and biasing LLMs without the need for model (re)training or highly specific datasets. In addition, the framework allows for more precise control of generated text than direct prompting and prior controlled text generation (CTG) techniques. Using model arithmetic, we can express prior CTG techniques as simple formulas and naturally extend them to new and more effective formulations. Further, we show that speculative sampling, a technique for efficient LLM sampling, extends to our setting. This enables highly efficient text generation with multiple composed models with only marginal overhead over a single model. Our empirical evaluation demonstrates that model arithmetic allows fine-grained control of generated text while outperforming state-of-the-art on the task of toxicity reduction.
Prompt Sketching for Large Language Models
Nov 08, 2023



Many recent prompting strategies for large language models (LLMs) query the model multiple times sequentially -- first to produce intermediate results and then the final answer. However, using these methods, both decoder and model are unaware of potential follow-up prompts, leading to disconnected and undesirably wordy intermediate responses. In this work, we address this issue by proposing prompt sketching, a new prompting paradigm in which an LLM does not only respond by completing a prompt, but by predicting values for multiple variables in a template. This way, sketching grants users more control over the generation process, e.g., by providing a reasoning framework via intermediate instructions, leading to better overall results. The key idea enabling sketching with existing, autoregressive models is to adapt the decoding procedure to also score follow-up instructions during text generation, thus optimizing overall template likelihood in inference. Our experiments show that in a zero-shot setting, prompt sketching outperforms existing, sequential prompting schemes such as direct asking or chain-of-thought on 7 out of 8 LLM benchmarking tasks, including state tracking, arithmetic reasoning, and general question answering. To facilitate future use, we release a number of generic, yet effective sketches applicable to many tasks, and an open source library called dclib, powering our sketch-aware decoders.
Understanding Certified Training with Interval Bound Propagation
Jun 17, 2023As robustness verification methods are becoming more precise, training certifiably robust neural networks is becoming ever more relevant. To this end, certified training methods compute and then optimize an upper bound on the worst-case loss over a robustness specification. Curiously, training methods based on the imprecise interval bound propagation (IBP) consistently outperform those leveraging more precise bounding methods. Still, we lack an understanding of the mechanisms making IBP so successful. In this work, we thoroughly investigate these mechanisms by leveraging a novel metric measuring the tightness of IBP bounds. We first show theoretically that, for deep linear models, tightness decreases with width and depth at initialization, but improves with IBP training, given sufficient network width. We, then, derive sufficient and necessary conditions on weight matrices for IBP bounds to become exact and demonstrate that these impose strong regularization, explaining the empirically observed trade-off between robustness and accuracy in certified training. Our extensive experimental evaluation validates our theoretical predictions for ReLU networks, including that wider networks improve performance, yielding state-of-the-art results. Interestingly, we observe that while all IBP-based training methods lead to high tightness, this is neither sufficient nor necessary to achieve high certifiable robustness. This hints at the existence of new training methods that do not induce the strong regularization required for tight IBP bounds, leading to improved robustness and standard accuracy.
TAPS: Connecting Certified and Adversarial Training
May 08, 2023Training certifiably robust neural networks remains a notoriously hard problem. On one side, adversarial training optimizes under-approximations of the worst-case loss, which leads to insufficient regularization for certification, while on the other, sound certified training methods optimize loose over-approximations, leading to over-regularization and poor (standard) accuracy. In this work we propose TAPS, an (unsound) certified training method that combines IBP and PGD training to yield precise, although not necessarily sound, worst-case loss approximations, reducing over-regularization and increasing certified and standard accuracies. Empirically, TAPS achieves a new state-of-the-art in many settings, e.g., reaching a certified accuracy of $22\%$ on TinyImageNet for $\ell_\infty$-perturbations with radius $\epsilon=1/255$.
Efficient Certified Training and Robustness Verification of Neural ODEs
Mar 09, 2023



Neural Ordinary Differential Equations (NODEs) are a novel neural architecture, built around initial value problems with learned dynamics which are solved during inference. Thought to be inherently more robust against adversarial perturbations, they were recently shown to be vulnerable to strong adversarial attacks, highlighting the need for formal guarantees. However, despite significant progress in robustness verification for standard feed-forward architectures, the verification of high dimensional NODEs remains an open problem. In this work, we address this challenge and propose GAINS, an analysis framework for NODEs combining three key ideas: (i) a novel class of ODE solvers, based on variable but discrete time steps, (ii) an efficient graph representation of solver trajectories, and (iii) a novel abstraction algorithm operating on this graph representation. Together, these advances enable the efficient analysis and certified training of high-dimensional NODEs, by reducing the runtime from an intractable $O(\exp(d)+\exp(T))$ to ${O}(d+T^2 \log^2T)$ in the dimensionality $d$ and integration time $T$. In an extensive evaluation on computer vision (MNIST and FMNIST) and time-series forecasting (PHYSIO-NET) problems, we demonstrate the effectiveness of both our certified training and verification methods.
Prompting Is Programming: A Query Language For Large Language Models
Dec 12, 2022



Large language models have demonstrated outstanding performance on a wide range of tasks such as question answering and code generation. On a high level, given an input, a language model can be used to automatically complete the sequence in a statistically-likely way. Based on this, users prompt these models with language instructions or examples, to implement a variety of downstream tasks. Advanced prompting methods can even imply interaction between the language model, a user, and external tools such as calculators. However, to obtain state-of-the-art performance or adapt language models for specific tasks, complex task- and model-specific programs have to be implemented, which may still require ad-hoc interaction. Based on this, we present the novel idea of Language Model Programming (LMP). LMP generalizes language model prompting from pure text prompts to an intuitive combination of text prompting and scripting. Additionally, LMP allows constraints to be specified over the language model output. This enables easy adaption to many tasks, while abstracting language model internals and providing high-level semantics. To enable LMP, we implement LMQL (short for Language Model Query Language), which leverages the constraints and control flow from an LMP prompt to generate an efficient inference procedure that minimizes the number of expensive calls to the underlying language model. We show that LMQL can capture a wide range of state-of-the-art prompting methods in an intuitive way, especially facilitating interactive flows that are challenging to implement with existing high-level APIs. Our evaluation shows that we retain or increase the accuracy on several downstream tasks, while also significantly reducing the required amount of computation or cost in the case of pay-to-use APIs (13-85% cost savings).