 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTechnical Report: Exploring the Emerging Threats of the Agent Skill Ecosystem
May 27, 2026We analyzed 3,984 AI agent skills from major marketplaces and found 76 confirmed malicious payloads, including credential theft, backdoor installation, and data exfiltration. 13.4% of all skills contain at least one critical-level security issue and at least 8 manually confirmed malicious skills remain publicly available on clawhub.ai as of the date of publication. This report documents our methodology, presents a threat taxonomy based on real-world samples, and details the attack patterns we observed. As skill marketplaces grow rapidly and AI agents gain access to sensitive credentials and systems, automated security analysis is no longer optional.
Trojan Hippo: Weaponizing Agent Memory for Data Exfiltration
May 05, 2026Memory systems enable otherwise-stateless LLM agents to persist user information across sessions, but also introduce a new attack surface. We characterize the Trojan Hippo attack, a class of persistent memory attacks that operates in a more realistic threat model than prior memory poisoning work: the attacker plants a dormant payload into an agent's long-term memory via a single untrusted tool call (e.g., a crafted email), which activates only when the user later discusses sensitive topics such as finance, health, or identity, and exfiltrates high-value personal data to the attacker. While anecdotal demonstrations of such attacks have appeared against deployed systems, no prior work systematically evaluates them across heterogeneous memory architectures and defenses. We introduce a dynamic evaluation framework comprising two components: (1) an OpenEvolve-based adaptive red-teaming benchmark that stress-tests defenses and memory backends against continuously refined attacks, and (2) the first capability-aware security/utility analysis for persistent memory systems, enabling principled reasoning about defense deployment across different usage profiles. Instantiated on an email assistant across four memory backends (explicit tool memory, agentic memory, RAG, and sliding-window context), Trojan Hippo achieves up to 85-100% ASR against current frontier models from OpenAI and Google, with planted memories successfully activating even after 100 benign sessions. We evaluate four memory-system defenses inspired by basic security principles, finding they substantially reduce attack success rates (to as low as 0-5%), though at utility costs that vary widely with task requirements. Because of this substantial security-utility tradeoff, the effective real-world deployment of defenses remains an open challenge, which our evaluation framework is specifically designed to address.
Skill-Inject: Measuring Agent Vulnerability to Skill File Attacks
Feb 25, 2026LLM agents are evolving rapidly, powered by code execution, tools, and the recently introduced agent skills feature. Skills allow users to extend LLM applications with specialized third-party code, knowledge, and instructions. Although this can extend agent capabilities to new domains, it creates an increasingly complex agent supply chain, offering new surfaces for prompt injection attacks. We identify skill-based prompt injection as a significant threat and introduce SkillInject, a benchmark evaluating the susceptibility of widely-used LLM agents to injections through skill files. SkillInject contains 202 injection-task pairs with attacks ranging from obviously malicious injections to subtle, context-dependent attacks hidden in otherwise legitimate instructions. We evaluate frontier LLMs on SkillInject, measuring both security in terms of harmful instruction avoidance and utility in terms of legitimate instruction compliance. Our results show that today's agents are highly vulnerable with up to 80% attack success rate with frontier models, often executing extremely harmful instructions including data exfiltration, destructive action, and ransomware-like behavior. They furthermore suggest that this problem will not be solved through model scaling or simple input filtering, but that robust agent security will require context-aware authorization frameworks. Our benchmark is available at https://www.skill-inject.com/.
Design Patterns for Securing LLM Agents against Prompt Injections
Jun 11, 2025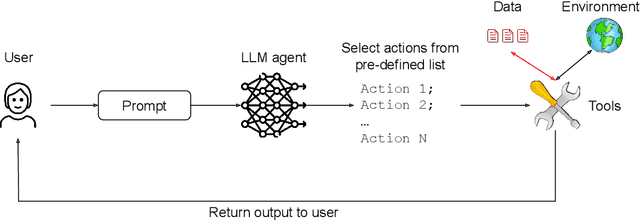
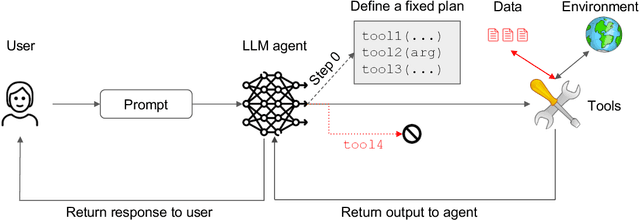
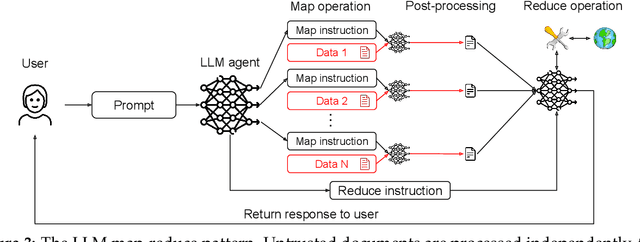
As AI agents powered by Large Language Models (LLMs) become increasingly versatile and capable of addressing a broad spectrum of tasks, ensuring their security has become a critical challenge. Among the most pressing threats are prompt injection attacks, which exploit the agent's resilience on natural language inputs -- an especially dangerous threat when agents are granted tool access or handle sensitive information. In this work, we propose a set of principled design patterns for building AI agents with provable resistance to prompt injection. We systematically analyze these patterns, discuss their trade-offs in terms of utility and security, and illustrate their real-world applicability through a series of case studies.
AgentDojo: A Dynamic Environment to Evaluate Attacks and Defenses for LLM Agents
Jun 19, 2024



AI agents aim to solve complex tasks by combining text-based reasoning with external tool calls. Unfortunately, AI agents are vulnerable to prompt injection attacks where data returned by external tools hijacks the agent to execute malicious tasks. To measure the adversarial robustness of AI agents, we introduce AgentDojo, an evaluation framework for agents that execute tools over untrusted data. To capture the evolving nature of attacks and defenses, AgentDojo is not a static test suite, but rather an extensible environment for designing and evaluating new agent tasks, defenses, and adaptive attacks. We populate the environment with 97 realistic tasks (e.g., managing an email client, navigating an e-banking website, or making travel bookings), 629 security test cases, and various attack and defense paradigms from the literature. We find that AgentDojo poses a challenge for both attacks and defenses: state-of-the-art LLMs fail at many tasks (even in the absence of attacks), and existing prompt injection attacks break some security properties but not all. We hope that AgentDojo can foster research on new design principles for AI agents that solve common tasks in a reliable and robust manner. We release the code for AgentDojo at https://github.com/ethz-spylab/agentdojo.
Controlled Text Generation via Language Model Arithmetic
Nov 24, 2023



As Large Language Models (LLMs) are deployed more widely, customization with respect to vocabulary, style and character becomes more important. In this work we introduce model arithmetic, a novel inference framework for composing and biasing LLMs without the need for model (re)training or highly specific datasets. In addition, the framework allows for more precise control of generated text than direct prompting and prior controlled text generation (CTG) techniques. Using model arithmetic, we can express prior CTG techniques as simple formulas and naturally extend them to new and more effective formulations. Further, we show that speculative sampling, a technique for efficient LLM sampling, extends to our setting. This enables highly efficient text generation with multiple composed models with only marginal overhead over a single model. Our empirical evaluation demonstrates that model arithmetic allows fine-grained control of generated text while outperforming state-of-the-art on the task of toxicity reduction.
Prompt Sketching for Large Language Models
Nov 08, 2023



Many recent prompting strategies for large language models (LLMs) query the model multiple times sequentially -- first to produce intermediate results and then the final answer. However, using these methods, both decoder and model are unaware of potential follow-up prompts, leading to disconnected and undesirably wordy intermediate responses. In this work, we address this issue by proposing prompt sketching, a new prompting paradigm in which an LLM does not only respond by completing a prompt, but by predicting values for multiple variables in a template. This way, sketching grants users more control over the generation process, e.g., by providing a reasoning framework via intermediate instructions, leading to better overall results. The key idea enabling sketching with existing, autoregressive models is to adapt the decoding procedure to also score follow-up instructions during text generation, thus optimizing overall template likelihood in inference. Our experiments show that in a zero-shot setting, prompt sketching outperforms existing, sequential prompting schemes such as direct asking or chain-of-thought on 7 out of 8 LLM benchmarking tasks, including state tracking, arithmetic reasoning, and general question answering. To facilitate future use, we release a number of generic, yet effective sketches applicable to many tasks, and an open source library called dclib, powering our sketch-aware decoders.
Prompting Is Programming: A Query Language For Large Language Models
Dec 12, 2022



Large language models have demonstrated outstanding performance on a wide range of tasks such as question answering and code generation. On a high level, given an input, a language model can be used to automatically complete the sequence in a statistically-likely way. Based on this, users prompt these models with language instructions or examples, to implement a variety of downstream tasks. Advanced prompting methods can even imply interaction between the language model, a user, and external tools such as calculators. However, to obtain state-of-the-art performance or adapt language models for specific tasks, complex task- and model-specific programs have to be implemented, which may still require ad-hoc interaction. Based on this, we present the novel idea of Language Model Programming (LMP). LMP generalizes language model prompting from pure text prompts to an intuitive combination of text prompting and scripting. Additionally, LMP allows constraints to be specified over the language model output. This enables easy adaption to many tasks, while abstracting language model internals and providing high-level semantics. To enable LMP, we implement LMQL (short for Language Model Query Language), which leverages the constraints and control flow from an LMP prompt to generate an efficient inference procedure that minimizes the number of expensive calls to the underlying language model. We show that LMQL can capture a wide range of state-of-the-art prompting methods in an intuitive way, especially facilitating interactive flows that are challenging to implement with existing high-level APIs. Our evaluation shows that we retain or increase the accuracy on several downstream tasks, while also significantly reducing the required amount of computation or cost in the case of pay-to-use APIs (13-85% cost savings).
Learning to Configure Computer Networks with Neural Algorithmic Reasoning
Oct 26, 2022We present a new method for scaling automatic configuration of computer networks. The key idea is to relax the computationally hard search problem of finding a configuration that satisfies a given specification into an approximate objective amenable to learning-based techniques. Based on this idea, we train a neural algorithmic model which learns to generate configurations likely to (fully or partially) satisfy a given specification under existing routing protocols. By relaxing the rigid satisfaction guarantees, our approach (i) enables greater flexibility: it is protocol-agnostic, enables cross-protocol reasoning, and does not depend on hardcoded rules; and (ii) finds configurations for much larger computer networks than previously possible. Our learned synthesizer is up to 490x faster than state-of-the-art SMT-based methods, while producing configurations which on average satisfy more than 93% of the provided requirements.
On Distribution Shift in Learning-based Bug Detectors
Apr 21, 2022


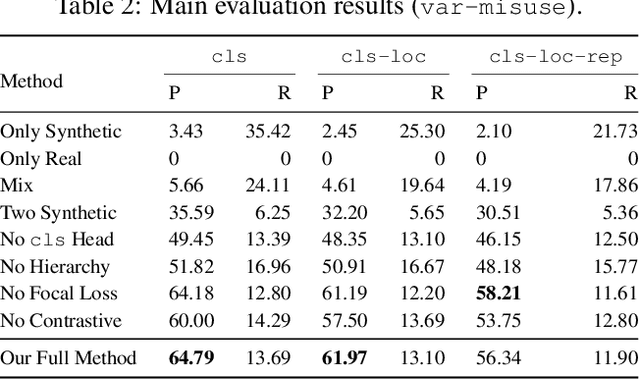
Deep learning has recently achieved initial success in program analysis tasks such as bug detection. Lacking real bugs, most existing works construct training and test data by injecting synthetic bugs into correct programs. Despite achieving high test accuracy (e.g. >90%), the resulting bug detectors are found to be surprisingly unusable in practice, i.e., <10% precision when used to scan real software repositories. In this work, we argue that this massive performance difference is caused by distribution shift, i.e., a fundamental mismatch between the real bug distribution and the synthetic bug distribution used to train and evaluate the detectors. To address this key challenge, we propose to train a bug detector in two phases, first on a synthetic bug distribution to adapt the model to the bug detection domain, and then on a real bug distribution to drive the model towards the real distribution. During these two phases, we leverage a multi-task hierarchy, focal loss, and contrastive learning to further boost performance. We evaluate our approach extensively on three widely studied bug types, for which we construct new datasets carefully designed to capture the real bug distribution. The results demonstrate that our approach is practically effective and successfully mitigates the distribution shift: our learned detectors are highly performant on both our constructed test set and the latest version of open source repositories.