 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Distribution Shift in Learning-based Bug Detectors
Paper and Code



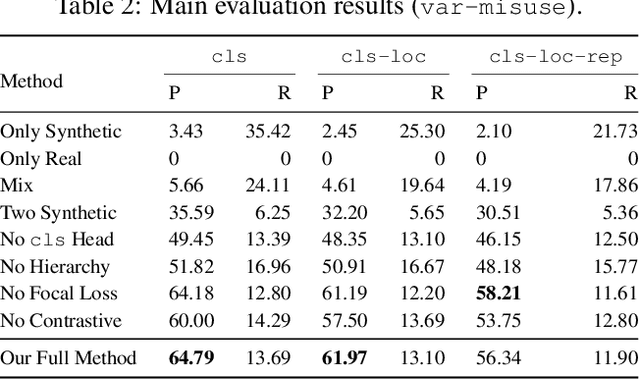
Deep learning has recently achieved initial success in program analysis tasks such as bug detection. Lacking real bugs, most existing works construct training and test data by injecting synthetic bugs into correct programs. Despite achieving high test accuracy (e.g. >90%), the resulting bug detectors are found to be surprisingly unusable in practice, i.e., <10% precision when used to scan real software repositories. In this work, we argue that this massive performance difference is caused by distribution shift, i.e., a fundamental mismatch between the real bug distribution and the synthetic bug distribution used to train and evaluate the detectors. To address this key challenge, we propose to train a bug detector in two phases, first on a synthetic bug distribution to adapt the model to the bug detection domain, and then on a real bug distribution to drive the model towards the real distribution. During these two phases, we leverage a multi-task hierarchy, focal loss, and contrastive learning to further boost performance. We evaluate our approach extensively on three widely studied bug types, for which we construct new datasets carefully designed to capture the real bug distribution. The results demonstrate that our approach is practically effective and successfully mitigates the distribution shift: our learned detectors are highly performant on both our constructed test set and the latest version of open source repositories.