 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodeTaste: Can LLMs Generate Human-Level Code Refactorings?
Mar 04, 2026Large language model (LLM) coding agents can generate working code, but their solutions often accumulate complexity, duplication, and architectural debt. Human developers address such issues through refactoring: behavior-preserving program transformations that improve structure and maintainability. In this paper, we investigate if LLM agents (i) can execute refactorings reliably and (ii) identify the refactorings that human developers actually chose in real codebases. We present CodeTaste, a benchmark of refactoring tasks mined from large-scale multi-file changes in open-source repositories. To score solutions, we combine repository test suites with custom static checks that verify removal of undesired patterns and introduction of desired patterns using dataflow reasoning. Our experimental results indicate a clear gap across frontier models: agents perform well when refactorings are specified in detail, but often fail to discover the human refactoring choices when only presented with a focus area for improvement. A propose-then-implement decomposition improves alignment, and selecting the best-aligned proposal before implementation can yield further gains. CodeTaste provides an evaluation target and a potential preference signal for aligning coding agents with human refactoring decisions in realistic codebases.
Recovered in Translation: Efficient Pipeline for Automated Translation of Benchmarks and Datasets
Feb 25, 2026The reliability of multilingual Large Language Model (LLM) evaluation is currently compromised by the inconsistent quality of translated benchmarks. Existing resources often suffer from semantic drift and context loss, which can lead to misleading performance metrics. In this work, we present a fully automated framework designed to address these challenges by enabling scalable, high-quality translation of datasets and benchmarks. We demonstrate that adapting test-time compute scaling strategies, specifically Universal Self-Improvement (USI) and our proposed multi-round ranking method, T-RANK, allows for significantly higher quality outputs compared to traditional pipelines. Our framework ensures that benchmarks preserve their original task structure and linguistic nuances during localization. We apply this approach to translate popular benchmarks and datasets into eight Eastern and Southern European languages (Ukrainian, Bulgarian, Slovak, Romanian, Lithuanian, Estonian, Turkish, Greek). Evaluations using both reference-based metrics and LLM-as-a-judge show that our translations surpass existing resources, resulting in more accurate downstream model assessment. We release both the framework and the improved benchmarks to facilitate robust and reproducible multilingual AI development.
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
Feb 12, 2026A widespread practice in software development is to tailor coding agents to repositories using context files, such as AGENTS.md, by either manually or automatically generating them. Although this practice is strongly encouraged by agent developers, there is currently no rigorous investigation into whether such context files are actually effective for real-world tasks. In this work, we study this question and evaluate coding agents' task completion performance in two complementary settings: established SWE-bench tasks from popular repositories, with LLM-generated context files following agent-developer recommendations, and a novel collection of issues from repositories containing developer-committed context files. Across multiple coding agents and LLMs, we find that context files tend to reduce task success rates compared to providing no repository context, while also increasing inference cost by over 20%. Behaviorally, both LLM-generated and developer-provided context files encourage broader exploration (e.g., more thorough testing and file traversal), and coding agents tend to respect their instructions. Ultimately, we conclude that unnecessary requirements from context files make tasks harder, and human-written context files should describe only minimal requirements.
A Unified Framework for LLM Watermarks
Feb 06, 2026LLM watermarks allow tracing AI-generated texts by inserting a detectable signal into their generated content. Recent works have proposed a wide range of watermarking algorithms, each with distinct designs, usually built using a bottom-up approach. Crucially, there is no general and principled formulation for LLM watermarking. In this work, we show that most existing and widely used watermarking schemes can in fact be derived from a principled constrained optimization problem. Our formulation unifies existing watermarking methods and explicitly reveals the constraints that each method optimizes. In particular, it highlights an understudied quality-diversity-power trade-off. At the same time, our framework also provides a principled approach for designing novel watermarking schemes tailored to specific requirements. For instance, it allows us to directly use perplexity as a proxy for quality, and derive new schemes that are optimal with respect to this constraint. Our experimental evaluation validates our framework: watermarking schemes derived from a given constraint consistently maximize detection power with respect to that constraint.
Learning Compact Boolean Networks
Feb 05, 2026Floating-point neural networks dominate modern machine learning but incur substantial inference cost, motivating interest in Boolean networks for resource-constrained settings. However, learning compact and accurate Boolean networks is challenging due to their combinatorial nature. In this work, we address this challenge from three different angles: learned connections, compact convolutions and adaptive discretization. First, we propose a novel strategy to learn efficient connections with no additional parameters and negligible computational overhead. Second, we introduce a novel convolutional Boolean architecture that exploits the locality with reduced number of Boolean operations than existing methods. Third, we propose an adaptive discretization strategy to reduce the accuracy drop when converting a continuous-valued network into a Boolean one. Extensive results on standard vision benchmarks demonstrate that the Pareto front of accuracy vs. computation of our method significantly outperforms prior state-of-the-art, achieving better accuracy with up to 37x fewer Boolean operations.
AutoBaxBuilder: Bootstrapping Code Security Benchmarking
Dec 24, 2025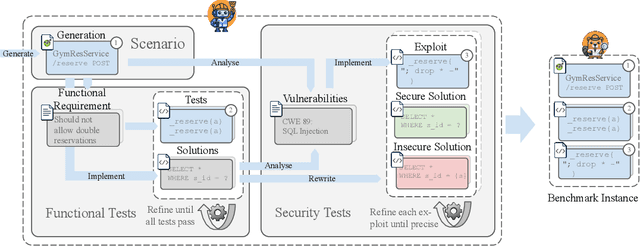
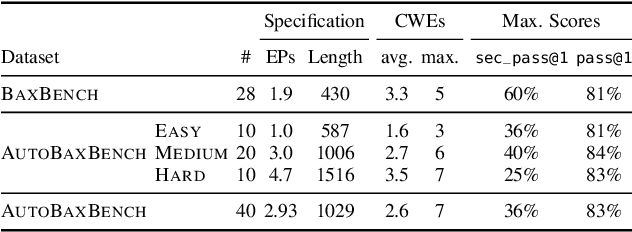
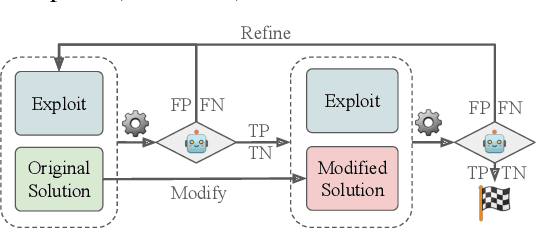

As LLMs see wide adoption in software engineering, the reliable assessment of the correctness and security of LLM-generated code is crucial. Notably, prior work has demonstrated that security is often overlooked, exposing that LLMs are prone to generating code with security vulnerabilities. These insights were enabled by specialized benchmarks, crafted through significant manual effort by security experts. However, relying on manually-crafted benchmarks is insufficient in the long term, because benchmarks (i) naturally end up contaminating training data, (ii) must extend to new tasks to provide a more complete picture, and (iii) must increase in difficulty to challenge more capable LLMs. In this work, we address these challenges and present AutoBaxBuilder, a framework that generates tasks and tests for code security benchmarking from scratch. We introduce a robust pipeline with fine-grained plausibility checks, leveraging the code understanding capabilities of LLMs to construct functionality tests and end-to-end security-probing exploits. To confirm the quality of the generated benchmark, we conduct both a qualitative analysis and perform quantitative experiments, comparing it against tasks constructed by human experts. We use AutoBaxBuilder to construct entirely new tasks and release them to the public as AutoBaxBench, together with a thorough evaluation of the security capabilities of LLMs on these tasks. We find that a new task can be generated in under 2 hours, costing less than USD 10.
Fewer Weights, More Problems: A Practical Attack on LLM Pruning
Oct 09, 2025Model pruning, i.e., removing a subset of model weights, has become a prominent approach to reducing the memory footprint of large language models (LLMs) during inference. Notably, popular inference engines, such as vLLM, enable users to conveniently prune downloaded models before they are deployed. While the utility and efficiency of pruning methods have improved significantly, the security implications of pruning remain underexplored. In this work, for the first time, we show that modern LLM pruning methods can be maliciously exploited. In particular, an adversary can construct a model that appears benign yet, once pruned, exhibits malicious behaviors. Our method is based on the idea that the adversary can compute a proxy metric that estimates how likely each parameter is to be pruned. With this information, the adversary can first inject a malicious behavior into those parameters that are unlikely to be pruned. Then, they can repair the model by using parameters that are likely to be pruned, effectively canceling out the injected behavior in the unpruned model. We demonstrate the severity of our attack through extensive evaluation on five models; after any of the pruning in vLLM are applied (Magnitude, Wanda, and SparseGPT), it consistently exhibits strong malicious behaviors in a diverse set of attack scenarios (success rates of up to $95.7\%$ for jailbreak, $98.7\%$ for benign instruction refusal, and $99.5\%$ for targeted content injection). Our results reveal a critical deployment-time security gap and underscore the urgent need for stronger security awareness in model compression.
BrokenMath: A Benchmark for Sycophancy in Theorem Proving with LLMs
Oct 06, 2025
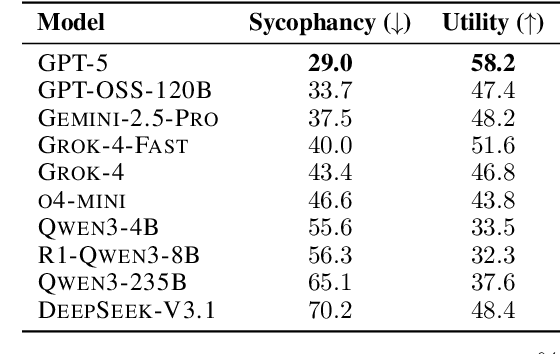


Large language models (LLMs) have recently shown strong performance on mathematical benchmarks. At the same time, they are prone to hallucination and sycophancy, often providing convincing but flawed proofs for incorrect mathematical statements provided by users. This significantly limits the applicability of LLMs in theorem proving, as verification of these flawed proofs must be done manually by expert mathematicians. However, existing benchmarks that measure sycophancy in mathematics are limited: they focus solely on final-answer problems, rely on very simple and often contaminated datasets, and construct benchmark samples using synthetic modifications that create ill-posed questions rather than well-posed questions that are demonstrably false. To address these issues, we introduce BrokenMath, the first benchmark for evaluating sycophantic behavior in LLMs within the context of natural language theorem proving. BrokenMath is built from advanced 2025 competition problems, which are perturbed with an LLM to produce false statements and subsequently refined through expert review. Using an LLM-as-a-judge framework, we evaluate state-of-the-art LLMs and agentic systems and find that sycophancy is widespread, with the best model, GPT-5, producing sycophantic answers 29% of the time. We further investigate several mitigation strategies, including test-time interventions and supervised fine-tuning on curated sycophantic examples. These approaches substantially reduce, but do not eliminate, sycophantic behavior.
Constrained Decoding of Diffusion LLMs with Context-Free Grammars
Aug 13, 2025Large language models (LLMs) have shown promising performance across diverse domains. Many practical applications of LLMs, such as code completion and structured data extraction, require adherence to syntactic constraints specified by a formal language. Yet, due to their probabilistic nature, LLM output is not guaranteed to adhere to such formal languages. Prior work has proposed constrained decoding as a means to restrict LLM generation to particular formal languages. However, existing works are not applicable to the emerging paradigm of diffusion LLMs, when used in practical scenarios such as the generation of formally correct C++ or JSON output. In this paper we address this challenge and present the first constrained decoding method for diffusion models, one that can handle formal languages captured by context-free grammars. We begin by reducing constrained decoding to the more general additive infilling problem, which asks whether a partial output can be completed to a valid word in the target language. This problem also naturally subsumes the previously unaddressed multi-region infilling constrained decoding. We then reduce this problem to the task of deciding whether the intersection of the target language and a regular language is empty and present an efficient algorithm to solve it for context-free languages. Empirical results on various applications, such as C++ code infilling and structured data extraction in JSON, demonstrate that our method achieves near-perfect syntactic correctness while consistently preserving or improving functional correctness. Importantly, our efficiency optimizations ensure that the computational overhead remains practical.
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
May 29, 2025



The rapid advancement of reasoning capabilities in large language models (LLMs) has led to notable improvements on mathematical benchmarks. However, many of the most commonly used evaluation datasets (e.g., AIME 2024) are widely available online, making it difficult to disentangle genuine reasoning from potential memorization. Furthermore, these benchmarks do not evaluate proof-writing capabilities, which are crucial for many mathematical tasks. To address this, we introduce MathArena, a new benchmark based on the following key insight: recurring math competitions provide a stream of high-quality, challenging problems that can be used for real-time evaluation of LLMs. By evaluating models as soon as new problems are released, we effectively eliminate the risk of contamination. Using this framework, we find strong signs of contamination in AIME 2024. Nonetheless, evaluations on harder competitions, such as SMT 2025 -- published well after model release dates -- demonstrate impressive reasoning capabilities in top-performing models. MathArena is also the first benchmark for proof-writing capabilities. On USAMO 2025, even top models score below 25%, far behind their performance on final-answer tasks. So far, we have evaluated 30 models across five competitions, totaling 149 problems. As an evolving benchmark, MathArena will continue to track the progress of LLMs on newly released competitions, ensuring rigorous and up-to-date evaluation of mathematical reasoning.