 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeoptimize_anything: A Universal API for Optimizing any Text Parameter
May 19, 2026Can a single LLM-based optimization system match specialized tools across fundamentally different domains? We show that when optimization problems are formulated as improving a text artifact evaluated by a scoring function, a single AI-based optimization system-supporting single-task search, multi-task search with cross-problem transfer, and generalization to unseen inputs-achieves state-of-the-art results across six diverse tasks. Our system discovers agent architectures that nearly triple Gemini Flash's ARC-AGI accuracy (32.5% to 89.5%), finds scheduling algorithms that cut cloud costs by 40%, generates CUDA kernels where 87% match or beat PyTorch, and outperforms AlphaEvolve's reported circle packing solution (n=26). Ablations across three domains reveal that actionable side information yields faster convergence and substantially higher final scores than score-only feedback, and that multi-task search outperforms independent optimization given equivalent per-problem budget through cross-task transfer, with benefits scaling with the number of related tasks. Together, we show for the first time that text optimization with LLM-based search is a general-purpose problem-solving paradigm, unifying tasks traditionally requiring domain-specific algorithms under a single framework. We open-source optimize\_anything with support for multiple backends as part of the GEPA project at https://github.com/gepa-ai/gepa .
* 16 pages, 11 figures; Blog: https://gepa-ai.github.io/gepa/blog/2026/02/18/introducing-optimize-anything/
Do Androids Dream of Breaking the Game? Systematically Auditing AI Agent Benchmarks with BenchJack
May 12, 2026Agent benchmarks have become the de facto measure of frontier AI competence, guiding model selection, investment, and deployment. However, reward hacking, where agents maximize a score without performing the intended task, emerges spontaneously in frontier models without overfitting. We argue that benchmarks must be secure by design. From past incidents of reward hacks, we derive a taxonomy of eight recurring flaw patterns and compile them into the Agent-Eval Checklist for benchmark designers. We condense the insights into BenchJack, an automated red-teaming system that drives coding agents to audit benchmarks and identify possible reward-hacking exploits in a clairvoyant manner. Moreover, we extend BenchJack to an iterative generative-adversarial pipeline that discovers new flaws and patches them iteratively to improve benchmark robustness. We apply BenchJack to 10 popular agent benchmarks spanning software engineering, web navigation, desktop computing, and terminal operations. BenchJack synthesizes reward-hacking exploits that achieve near-perfect scores on most of the benchmarks without solving a single task, surfacing 219 distinct flaws across the eight classes. Moreover, BenchJack's extended pipeline reduces the hackable-task ratio from near 100% to under 10% on four benchmarks without fatal design flaws, fully patching WebArena and OSWorld within three iterations. Our results show that evaluation pipelines have not internalized an adversarial mindset, and that proactive auditing could help close the security gap for the fast-paced benchmarking space.
AdaEvolve: Adaptive LLM Driven Zeroth-Order Optimization
Feb 23, 2026The paradigm of automated program generation is shifting from one-shot generation to inference-time search, where Large Language Models (LLMs) function as semantic mutation operators within evolutionary loops. While effective, these systems are currently governed by static schedules that fail to account for the non-stationary dynamics of the search process. This rigidity results in substantial computational waste, as resources are indiscriminately allocated to stagnating populations while promising frontiers remain under-exploited. We introduce AdaEvolve, a framework that reformulates LLM-driven evolution as a hierarchical adaptive optimization problem. AdaEvolve uses an "accumulated improvement signal" to unify decisions across three levels: Local Adaptation, which dynamically modulates the exploration intensity within a population of solution candidates; Global Adaptation, which routes the global resource budget via bandit-based scheduling across different solution candidate populations; and Meta-Guidance which generates novel solution tactics based on the previously generated solutions and their corresponding improvements when the progress stalls. We demonstrate that AdaEvolve consistently outperforms the open-sourced baselines across 185 different open-ended optimization problems including combinatorial, systems optimization and algorithm design problems.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
GSO: Challenging Software Optimization Tasks for Evaluating SWE-Agents
May 29, 2025Developing high-performance software is a complex task that requires specialized expertise. We introduce GSO, a benchmark for evaluating language models' capabilities in developing high-performance software. We develop an automated pipeline that generates and executes performance tests to analyze repository commit histories to identify 102 challenging optimization tasks across 10 codebases, spanning diverse domains and programming languages. An agent is provided with a codebase and performance test as a precise specification, and tasked to improve the runtime efficiency, which is measured against the expert developer optimization. Our quantitative evaluation reveals that leading SWE-Agents struggle significantly, achieving less than 5% success rate, with limited improvements even with inference-time scaling. Our qualitative analysis identifies key failure modes, including difficulties with low-level languages, practicing lazy optimization strategies, and challenges in accurately localizing bottlenecks. We release the code and artifacts of our benchmark along with agent trajectories to enable future research.
Type-Constrained Code Generation with Language Models
Apr 12, 2025
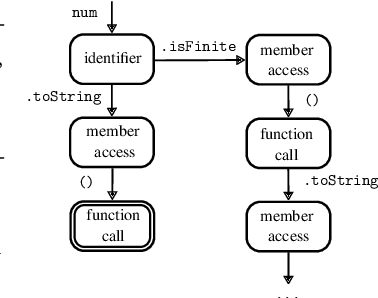
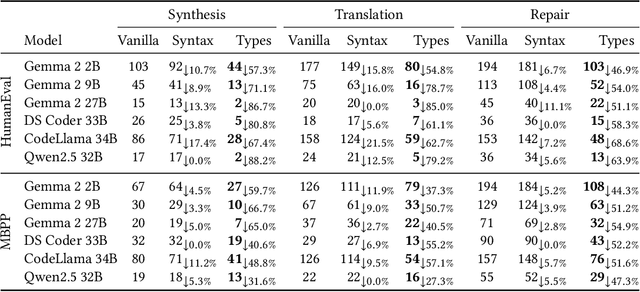
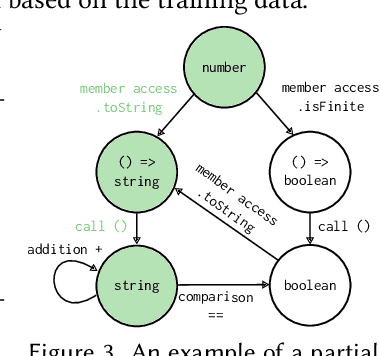
Large language models (LLMs) have achieved notable success in code generation. However, they still frequently produce uncompilable output because their next-token inference procedure does not model formal aspects of code. Although constrained decoding is a promising approach to alleviate this issue, it has only been applied to handle either domain-specific languages or syntactic language features. This leaves typing errors, which are beyond the domain of syntax and generally hard to adequately constrain. To address this challenge, we introduce a type-constrained decoding approach that leverages type systems to guide code generation. We develop novel prefix automata for this purpose and introduce a sound approach to enforce well-typedness based on type inference and a search over inhabitable types. We formalize our approach on a simply-typed language and extend it to TypeScript to demonstrate practicality. Our evaluation on HumanEval shows that our approach reduces compilation errors by more than half and increases functional correctness in code synthesis, translation, and repair tasks across LLMs of various sizes and model families, including SOTA open-weight models with more than 30B parameters.
R2E-Gym: Procedural Environments and Hybrid Verifiers for Scaling Open-Weights SWE Agents
Apr 09, 2025Improving open-source models on real-world SWE tasks (solving GITHUB issues) faces two key challenges: 1) scalable curation of execution environments to train these models, and, 2) optimal scaling of test-time compute. We introduce AgentGym, the largest procedurally-curated executable gym environment for training real-world SWE-agents, consisting of more than 8.7K tasks. AgentGym is powered by two main contributions: 1) SYNGEN: a synthetic data curation recipe that enables scalable curation of executable environments using test-generation and back-translation directly from commits, thereby reducing reliance on human-written issues or unit tests. We show that this enables more scalable training leading to pass@1 performance of 34.4% on SWE-Bench Verified benchmark with our 32B model. 2) Hybrid Test-time Scaling: we provide an in-depth analysis of two test-time scaling axes; execution-based and execution-free verifiers, demonstrating that they exhibit complementary strengths and limitations. Test-based verifiers suffer from low distinguishability, while execution-free verifiers are biased and often rely on stylistic features. Surprisingly, we find that while each approach individually saturates around 42-43%, significantly higher gains can be obtained by leveraging their complementary strengths. Overall, our approach achieves 51% on the SWE-Bench Verified benchmark, reflecting a new state-of-the-art for open-weight SWE-agents and for the first time showing competitive performance with proprietary models such as o1, o1-preview and sonnet-3.5-v2 (with tools). We will open-source our environments, models, and agent trajectories.
Challenges and Paths Towards AI for Software Engineering
Mar 28, 2025AI for software engineering has made remarkable progress recently, becoming a notable success within generative AI. Despite this, there are still many challenges that need to be addressed before automated software engineering reaches its full potential. It should be possible to reach high levels of automation where humans can focus on the critical decisions of what to build and how to balance difficult tradeoffs while most routine development effort is automated away. Reaching this level of automation will require substantial research and engineering efforts across academia and industry. In this paper, we aim to discuss progress towards this in a threefold manner. First, we provide a structured taxonomy of concrete tasks in AI for software engineering, emphasizing the many other tasks in software engineering beyond code generation and completion. Second, we outline several key bottlenecks that limit current approaches. Finally, we provide an opinionated list of promising research directions toward making progress on these bottlenecks, hoping to inspire future research in this rapidly maturing field.
LangProBe: a Language Programs Benchmark
Feb 27, 2025
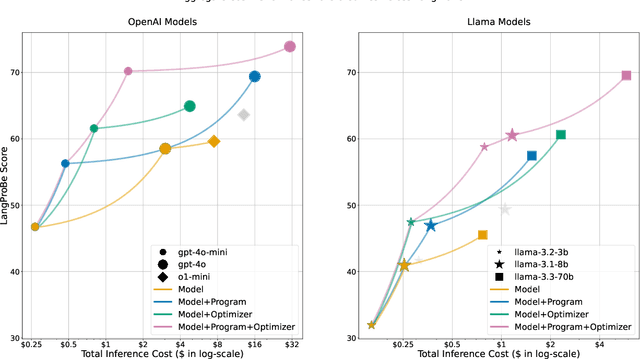
Composing language models (LMs) into multi-step language programs and automatically optimizing their modular prompts is now a mainstream paradigm for building AI systems, but the tradeoffs in this space have only scarcely been studied before. We introduce LangProBe, the first large-scale benchmark for evaluating the architectures and optimization strategies for language programs, with over 2000 combinations of tasks, architectures, optimizers, and choices of LMs. Using LangProBe, we are the first to study the impact of program architectures and optimizers (and their compositions together and with different models) on tradeoffs of quality and cost. We find that optimized language programs offer strong cost--quality Pareto improvement over raw calls to models, but simultaneously demonstrate that human judgment (or empirical decisions) about which compositions to pursue is still necessary for best performance. We will open source the code and evaluation data for LangProBe.
Syzygy: Dual Code-Test C to (safe) Rust Translation using LLMs and Dynamic Analysis
Dec 18, 2024Despite extensive usage in high-performance, low-level systems programming applications, C is susceptible to vulnerabilities due to manual memory management and unsafe pointer operations. Rust, a modern systems programming language, offers a compelling alternative. Its unique ownership model and type system ensure memory safety without sacrificing performance. In this paper, we present Syzygy, an automated approach to translate C to safe Rust. Our technique uses a synergistic combination of LLM-driven code and test translation guided by dynamic-analysis-generated execution information. This paired translation runs incrementally in a loop over the program in dependency order of the code elements while maintaining per-step correctness. Our approach exposes novel insights on combining the strengths of LLMs and dynamic analysis in the context of scaling and combining code generation with testing. We apply our approach to successfully translate Zopfli, a high-performance compression library with ~3000 lines of code and 98 functions. We validate the translation by testing equivalence with the source C program on a set of inputs. To our knowledge, this is the largest automated and test-validated C to safe Rust code translation achieved so far.