 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPMWorlds: Material-Point-Method Simulations for Inferring and Extrapolating Physical Dynamics
Jun 01, 2026To study the ability to infer physical dynamics from videos and extrapolate them forward in time, we assemble a dataset of 2D Material Point Method (MPM) physical simulations covering rich physical phenomena such as deformable objects, fluids, kinetic objects, and emitters. We study code generation and video diffusion approaches on this dataset, identifying their strengths and weaknesses by varying the amount of physically relevant side information. The code generation model, beyond giving a working demonstration of automatic synthesis of MPM simulations, reveals that such an approach struggles with inferring physical parameters from visual input, but relative to video diffusion, produces physically and temporally stable extrapolations forward in time, while the video diffusion model more strongly identifies geometric properties from visual input but produces physically implausible extrapolations.
Hypothesis Generation and Inductive Inference in Children and Language Models
May 23, 2026Real world decision-making requires constructing mental models under uncertainty over evidence, over the underlying causal rules, and over the state of the world itself. Which computational principles underpin human inference under such conditions, and do LLM-based agents exhibit similar behavior given matching constraints? We address these questions using an inductive inference Box Task in which participants, human children and LLM-based agents, infer a latent cause through sequential interaction with an uncertain environment. We formalize this task as program induction with Bayesian particle-based inference, admitting two complementary interpretations: (1) as a constraint satisfaction process over hypotheses, and (2) as a program synthesis problem in which hypotheses are executable programs evaluated against evidence. Using the constraint-based formulation, we show that children's behavior is best explained by a combination of subjective evidence reliability and online hypothesis generation, accounting for both their evidence-seeking patterns and their dissociation between task completion and rule generalization. Using the program synthesis formulation, we treat LLM-based agents as model organisms: controllable systems that allow systematic manipulation of task conditions. Across backends, LLM-based agents replicate children's responses to changes in evidence reliability and observability, including discounting unreliable evidence, seeking to resolve partial information, and dissociating between task completion and causal generalization. At the same time, LLM-based agents tend to over-observe and over-comply with instructions relative to children. These results suggest that while children and LLM-based agents adapt similarly to environmental structure, their information-seeking behavior exhibits distinct underlying costs and inductive biases.
Bongards at the Boundary of Perception and Reasoning: Programs or Language?
Feb 03, 2026Vision-Language Models (VLMs) have made great strides in everyday visual tasks, such as captioning a natural image, or answering commonsense questions about such images. But humans possess the puzzling ability to deploy their visual reasoning abilities in radically new situations, a skill rigorously tested by the classic set of visual reasoning challenges known as the Bongard problems. We present a neurosymbolic approach to solving these problems: given a hypothesized solution rule for a Bongard problem, we leverage LLMs to generate parameterized programmatic representations for the rule and perform parameter fitting using Bayesian optimization. We evaluate our method on classifying Bongard problem images given the ground truth rule, as well as on solving the problems from scratch.
Joint Learning of Hierarchical Neural Options and Abstract World Model
Feb 02, 2026Building agents that can perform new skills by composing existing skills is a long-standing goal of AI agent research. Towards this end, we investigate how to efficiently acquire a sequence of skills, formalized as hierarchical neural options. However, existing model-free hierarchical reinforcement algorithms need a lot of data. We propose a novel method, which we call AgentOWL (Option and World model Learning Agent), that jointly learns -- in a sample efficient way -- an abstract world model (abstracting across both states and time) and a set of hierarchical neural options. We show, on a subset of Object-Centric Atari games, that our method can learn more skills using much less data than baseline methods.
OmniCode: A Benchmark for Evaluating Software Engineering Agents
Feb 02, 2026LLM-powered coding agents are redefining how real-world software is developed. To drive the research towards better coding agents, we require challenging benchmarks that can rigorously evaluate the ability of such agents to perform various software engineering tasks. However, popular coding benchmarks such as HumanEval and SWE-Bench focus on narrowly scoped tasks such as competition programming and patch generation. In reality, software engineers have to handle a broader set of tasks for real-world software development. To address this gap, we propose OmniCode, a novel software engineering benchmark that contains a broader and more diverse set of task categories beyond code or patch generation. Overall, OmniCode contains 1794 tasks spanning three programming languages (Python, Java, and C++) and four key categories: bug fixing, test generation, code review fixing, and style fixing. In contrast to prior software engineering benchmarks, the tasks in OmniCode are (1) manually validated to eliminate ill-defined problems, and (2) synthetically crafted or recently curated to avoid data leakage issues, presenting a new framework for synthetically generating diverse software tasks from limited real-world data. We evaluate OmniCode with popular agent frameworks such as SWE-Agent and show that while they may perform well on bug fixing for Python, they fall short on tasks such as Test Generation and in languages such as C++ and Java. For instance, SWE-Agent achieves a maximum of 20.9% with DeepSeek-V3.1 on Java Test Generation tasks. OmniCode aims to serve as a robust benchmark and spur the development of agents that can perform well across different aspects of software development. Code and data are available at https://github.com/seal-research/OmniCode.
Programmatic Video Prediction Using Large Language Models
May 20, 2025The task of estimating the world model describing the dynamics of a real world process assumes immense importance for anticipating and preparing for future outcomes. For applications such as video surveillance, robotics applications, autonomous driving, etc. this objective entails synthesizing plausible visual futures, given a few frames of a video to set the visual context. Towards this end, we propose ProgGen, which undertakes the task of video frame prediction by representing the dynamics of the video using a set of neuro-symbolic, human-interpretable set of states (one per frame) by leveraging the inductive biases of Large (Vision) Language Models (LLM/VLM). In particular, ProgGen utilizes LLM/VLM to synthesize programs: (i) to estimate the states of the video, given the visual context (i.e. the frames); (ii) to predict the states corresponding to future time steps by estimating the transition dynamics; (iii) to render the predicted states as visual RGB-frames. Empirical evaluations reveal that our proposed method outperforms competing techniques at the task of video frame prediction in two challenging environments: (i) PhyWorld (ii) Cart Pole. Additionally, ProgGen permits counter-factual reasoning and interpretable video generation attesting to its effectiveness and generalizability for video generation tasks.
PoE-World: Compositional World Modeling with Products of Programmatic Experts
May 16, 2025Learning how the world works is central to building AI agents that can adapt to complex environments. Traditional world models based on deep learning demand vast amounts of training data, and do not flexibly update their knowledge from sparse observations. Recent advances in program synthesis using Large Language Models (LLMs) give an alternate approach which learns world models represented as source code, supporting strong generalization from little data. To date, application of program-structured world models remains limited to natural language and grid-world domains. We introduce a novel program synthesis method for effectively modeling complex, non-gridworld domains by representing a world model as an exponentially-weighted product of programmatic experts (PoE-World) synthesized by LLMs. We show that this approach can learn complex, stochastic world models from just a few observations. We evaluate the learned world models by embedding them in a model-based planning agent, demonstrating efficient performance and generalization to unseen levels on Atari's Pong and Montezuma's Revenge. We release our code and display the learned world models and videos of the agent's gameplay at https://topwasu.github.io/poe-world.
LLM-Guided Probabilistic Program Induction for POMDP Model Estimation
May 04, 2025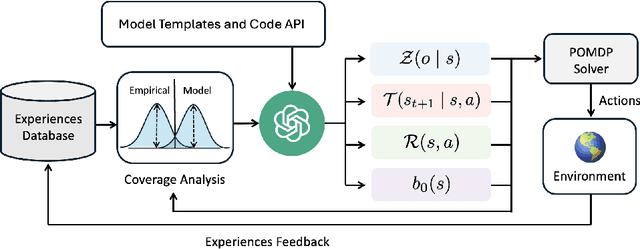



Partially Observable Markov Decision Processes (POMDPs) model decision making under uncertainty. While there are many approaches to approximately solving POMDPs, we aim to address the problem of learning such models. In particular, we are interested in a subclass of POMDPs wherein the components of the model, including the observation function, reward function, transition function, and initial state distribution function, can be modeled as low-complexity probabilistic graphical models in the form of a short probabilistic program. Our strategy to learn these programs uses an LLM as a prior, generating candidate probabilistic programs that are then tested against the empirical distribution and adjusted through feedback. We experiment on a number of classical toy POMDP problems, simulated MiniGrid domains, and two real mobile-base robotics search domains involving partial observability. Our results show that using an LLM to guide in the construction of a low-complexity POMDP model can be more effective than tabular POMDP learning, behavior cloning, or direct LLM planning.
Cognitive maps are generative programs
Apr 29, 2025Making sense of the world and acting in it relies on building simplified mental representations that abstract away aspects of reality. This principle of cognitive mapping is universal to agents with limited resources. Living organisms, people, and algorithms all face the problem of forming functional representations of their world under various computing constraints. In this work, we explore the hypothesis that human resource-efficient planning may arise from representing the world as predictably structured. Building on the metaphor of concepts as programs, we propose that cognitive maps can take the form of generative programs that exploit predictability and redundancy, in contrast to directly encoding spatial layouts. We use a behavioral experiment to show that people who navigate in structured spaces rely on modular planning strategies that align with programmatic map representations. We describe a computational model that predicts human behavior in a variety of structured scenarios. This model infers a small distribution over possible programmatic cognitive maps conditioned on human prior knowledge of the world, and uses this distribution to generate resource-efficient plans. Our models leverages a Large Language Model as an embedding of human priors, implicitly learned through training on a vast corpus of human data. Our model demonstrates improved computational efficiency, requires drastically less memory, and outperforms unstructured planning algorithms with cognitive constraints at predicting human behavior, suggesting that human planning strategies rely on programmatic cognitive maps.
Challenges and Paths Towards AI for Software Engineering
Mar 28, 2025AI for software engineering has made remarkable progress recently, becoming a notable success within generative AI. Despite this, there are still many challenges that need to be addressed before automated software engineering reaches its full potential. It should be possible to reach high levels of automation where humans can focus on the critical decisions of what to build and how to balance difficult tradeoffs while most routine development effort is automated away. Reaching this level of automation will require substantial research and engineering efforts across academia and industry. In this paper, we aim to discuss progress towards this in a threefold manner. First, we provide a structured taxonomy of concrete tasks in AI for software engineering, emphasizing the many other tasks in software engineering beyond code generation and completion. Second, we outline several key bottlenecks that limit current approaches. Finally, we provide an opinionated list of promising research directions toward making progress on these bottlenecks, hoping to inspire future research in this rapidly maturing field.