 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Apr 28, 2026Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 13 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics. Website and code: https://prpl-group.com/kinder-site/
PoE-World: Compositional World Modeling with Products of Programmatic Experts
May 16, 2025Learning how the world works is central to building AI agents that can adapt to complex environments. Traditional world models based on deep learning demand vast amounts of training data, and do not flexibly update their knowledge from sparse observations. Recent advances in program synthesis using Large Language Models (LLMs) give an alternate approach which learns world models represented as source code, supporting strong generalization from little data. To date, application of program-structured world models remains limited to natural language and grid-world domains. We introduce a novel program synthesis method for effectively modeling complex, non-gridworld domains by representing a world model as an exponentially-weighted product of programmatic experts (PoE-World) synthesized by LLMs. We show that this approach can learn complex, stochastic world models from just a few observations. We evaluate the learned world models by embedding them in a model-based planning agent, demonstrating efficient performance and generalization to unseen levels on Atari's Pong and Montezuma's Revenge. We release our code and display the learned world models and videos of the agent's gameplay at https://topwasu.github.io/poe-world.
Predicate Invention from Pixels via Pretrained Vision-Language Models
Dec 31, 2024



Our aim is to learn to solve long-horizon decision-making problems in highly-variable, combinatorially-complex robotics domains given raw sensor input in the form of images. Previous work has shown that one way to achieve this aim is to learn a structured abstract transition model in the form of symbolic predicates and operators, and then plan within this model to solve novel tasks at test time. However, these learned models do not ground directly into pixels from just a handful of demonstrations. In this work, we propose to invent predicates that operate directly over input images by leveraging the capabilities of pretrained vision-language models (VLMs). Our key idea is that, given a set of demonstrations, a VLM can be used to propose a set of predicates that are potentially relevant for decision-making and then to determine the truth values of these predicates in both the given demonstrations and new image inputs. We build upon an existing framework for predicate invention, which generates feature-based predicates operating on object-centric states, to also generate visual predicates that operate on images. Experimentally, we show that our approach -- pix2pred -- is able to invent semantically meaningful predicates that enable generalization to novel, complex, and long-horizon tasks across two simulated robotic environments.
VisualPredicator: Learning Abstract World Models with Neuro-Symbolic Predicates for Robot Planning
Oct 30, 2024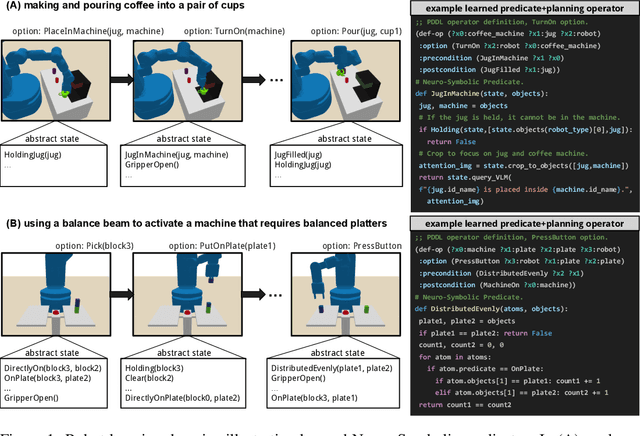
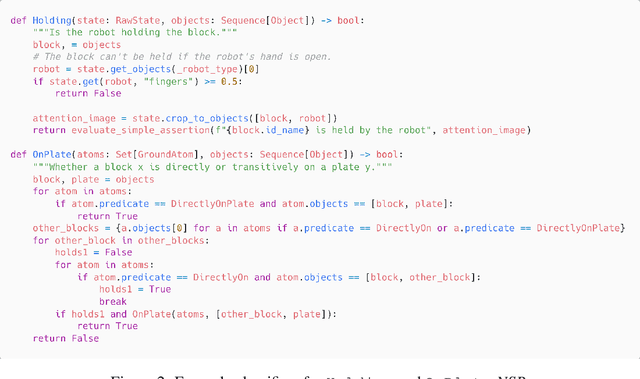
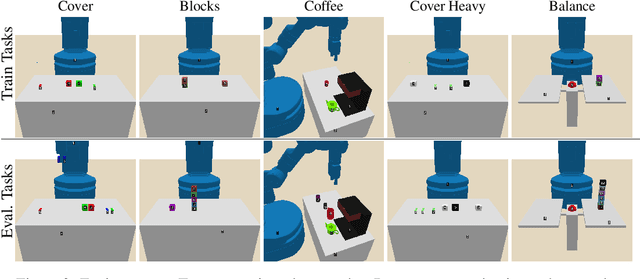
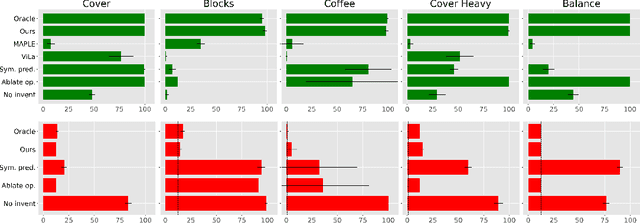
Broadly intelligent agents should form task-specific abstractions that selectively expose the essential elements of a task, while abstracting away the complexity of the raw sensorimotor space. In this work, we present Neuro-Symbolic Predicates, a first-order abstraction language that combines the strengths of symbolic and neural knowledge representations. We outline an online algorithm for inventing such predicates and learning abstract world models. We compare our approach to hierarchical reinforcement learning, vision-language model planning, and symbolic predicate invention approaches, on both in- and out-of-distribution tasks across five simulated robotic domains. Results show that our approach offers better sample complexity, stronger out-of-distribution generalization, and improved interpretability.
Rapid Motor Adaptation for Robotic Manipulator Arms
Dec 07, 2023



Developing generalizable manipulation skills is a core challenge in embodied AI. This includes generalization across diverse task configurations, encompassing variations in object shape, density, friction coefficient, and external disturbances such as forces applied to the robot. Rapid Motor Adaptation (RMA) offers a promising solution to this challenge. It posits that essential hidden variables influencing an agent's task performance, such as object mass and shape, can be effectively inferred from the agent's action and proprioceptive history. Drawing inspiration from RMA in locomotion and in-hand rotation, we use depth perception to develop agents tailored for rapid motor adaptation in a variety of manipulation tasks. We evaluated our agents on four challenging tasks from the Maniskill2 benchmark, namely pick-and-place operations with hundreds of objects from the YCB and EGAD datasets, peg insertion with precise position and orientation, and operating a variety of faucets and handles, with customized environment variations. Empirical results demonstrate that our agents surpass state-of-the-art methods like automatic domain randomization and vision-based policies, obtaining better generalization performance and sample efficiency.
Learning to Infer 3D Shape Programs with Differentiable Renderer
Jun 25, 2022
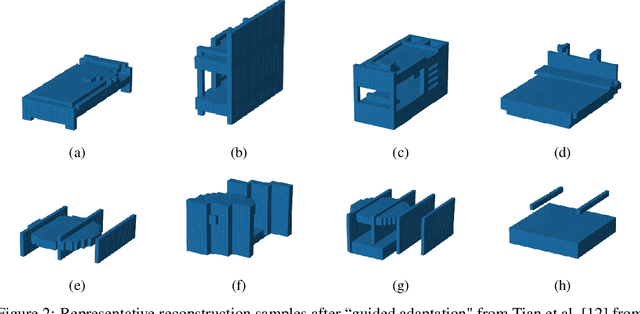
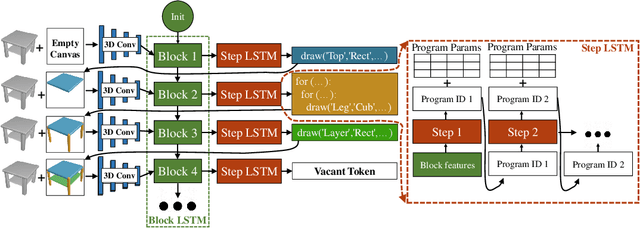
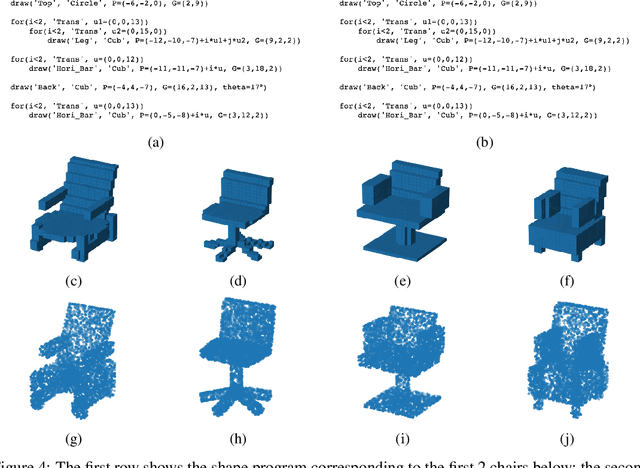
Given everyday artifacts, such as tables and chairs, humans recognize high-level regularities within them, such as the symmetries of a table, the repetition of its legs, while possessing low-level priors of their geometries, e.g., surfaces are smooth and edges are sharp. This kind of knowledge constitutes an important part of human perceptual understanding and reasoning. Representations of and how to reason in such knowledge, and the acquisition thereof, are still open questions in artificial intelligence (AI) and cognitive science. Building on the previous proposal of the \emph{3D shape programs} representation alone with the accompanying neural generator and executor from \citet{tian2019learning}, we propose an analytical yet differentiable executor that is more faithful and controllable in interpreting shape programs (particularly in extrapolation) and more sample efficient (requires no training). These facilitate the generator's learning when ground truth programs are not available, and should be especially useful when new shape-program components are enrolled either by human designers or -- in the context of library learning -- algorithms themselves. Preliminary experiments on using it for adaptation illustrate the aforesaid advantages of the proposed module, encouraging similar methods being explored in building machines that learn to reason with the kind of knowledge described above, and even learn this knowledge itself.
Transition-based Abstract Meaning Representation Parsing with Contextual Embeddings
Jun 13, 2022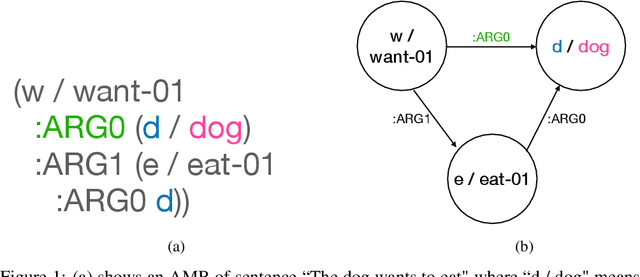
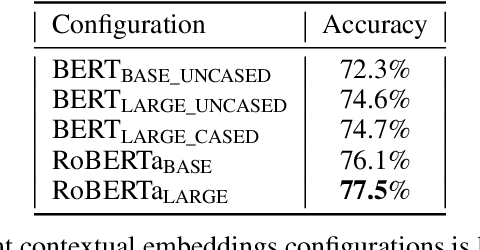


The ability to understand and generate languages sets human cognition apart from other known life forms'. We study a way of combing two of the most successful routes to meaning of language--statistical language models and symbolic semantics formalisms--in the task of semantic parsing. Building on a transition-based, Abstract Meaning Representation (AMR) parser, AmrEager, we explore the utility of incorporating pretrained context-aware word embeddings--such as BERT and RoBERTa--in the problem of AMR parsing, contributing a new parser we dub as AmrBerger. Experiments find these rich lexical features alone are not particularly helpful in improving the parser's overall performance as measured by the SMATCH score when compared to the non-contextual counterpart, while additional concept information empowers the system to outperform the baselines. Through lesion study, we found the use of contextual embeddings helps to make the system more robust against the removal of explicit syntactical features. These findings expose the strength and weakness of the contextual embeddings and the language models in the current form, and motivate deeper understanding thereof.
Drawing out of Distribution with Neuro-Symbolic Generative Models
Jun 03, 2022
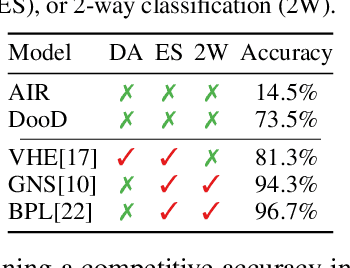
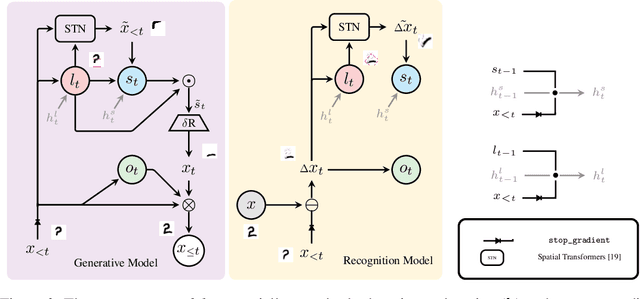
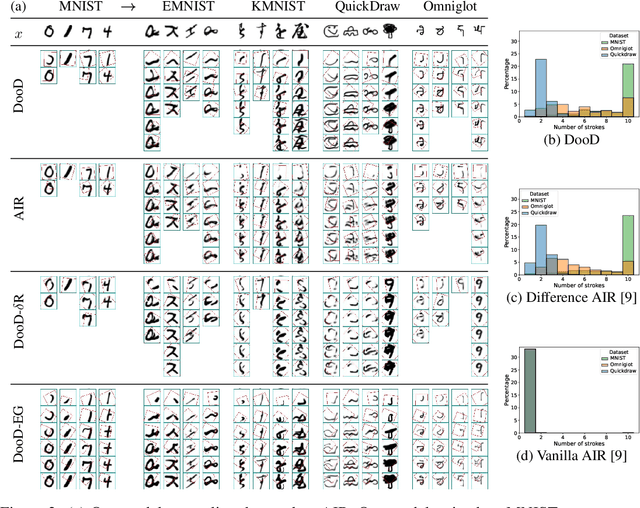
Learning general-purpose representations from perceptual inputs is a hallmark of human intelligence. For example, people can write out numbers or characters, or even draw doodles, by characterizing these tasks as different instantiations of the same generic underlying process -- compositional arrangements of different forms of pen strokes. Crucially, learning to do one task, say writing, implies reasonable competence at another, say drawing, on account of this shared process. We present Drawing out of Distribution (DooD), a neuro-symbolic generative model of stroke-based drawing that can learn such general-purpose representations. In contrast to prior work, DooD operates directly on images, requires no supervision or expensive test-time inference, and performs unsupervised amortised inference with a symbolic stroke model that better enables both interpretability and generalization. We evaluate DooD on its ability to generalise across both data and tasks. We first perform zero-shot transfer from one dataset (e.g. MNIST) to another (e.g. Quickdraw), across five different datasets, and show that DooD clearly outperforms different baselines. An analysis of the learnt representations further highlights the benefits of adopting a symbolic stroke model. We then adopt a subset of the Omniglot challenge tasks, and evaluate its ability to generate new exemplars (both unconditionally and conditionally), and perform one-shot classification, showing that DooD matches the state of the art. Taken together, we demonstrate that DooD does indeed capture general-purpose representations across both data and task, and takes a further step towards building general and robust concept-learning systems.