 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransition-based Abstract Meaning Representation Parsing with Contextual Embeddings
Paper and Code
Jun 13, 2022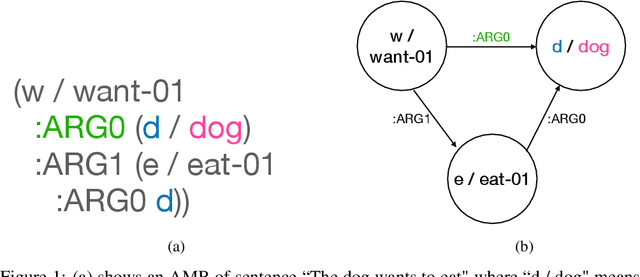
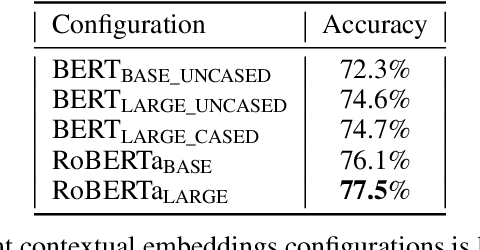


The ability to understand and generate languages sets human cognition apart from other known life forms'. We study a way of combing two of the most successful routes to meaning of language--statistical language models and symbolic semantics formalisms--in the task of semantic parsing. Building on a transition-based, Abstract Meaning Representation (AMR) parser, AmrEager, we explore the utility of incorporating pretrained context-aware word embeddings--such as BERT and RoBERTa--in the problem of AMR parsing, contributing a new parser we dub as AmrBerger. Experiments find these rich lexical features alone are not particularly helpful in improving the parser's overall performance as measured by the SMATCH score when compared to the non-contextual counterpart, while additional concept information empowers the system to outperform the baselines. Through lesion study, we found the use of contextual embeddings helps to make the system more robust against the removal of explicit syntactical features. These findings expose the strength and weakness of the contextual embeddings and the language models in the current form, and motivate deeper understanding thereof.