 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindCine: Multimodal EEG-to-Video Reconstruction with Large-Scale Pretrained Models
Jan 27, 2026Reconstructing human dynamic visual perception from electroencephalography (EEG) signals is of great research significance since EEG's non-invasiveness and high temporal resolution. However, EEG-to-video reconstruction remains challenging due to: 1) Single Modality: existing studies solely align EEG signals with the text modality, which ignores other modalities and are prone to suffer from overfitting problems; 2) Data Scarcity: current methods often have difficulty training to converge with limited EEG-video data. To solve the above problems, we propose a novel framework MindCine to achieve high-fidelity video reconstructions on limited data. We employ a multimodal joint learning strategy to incorporate beyond-text modalities in the training stage and leverage a pre-trained large EEG model to relieve the data scarcity issue for decoding semantic information, while a Seq2Seq model with causal attention is specifically designed for decoding perceptual information. Extensive experiments demonstrate that our model outperforms state-of-the-art methods both qualitatively and quantitatively. Additionally, the results underscore the effectiveness of the complementary strengths of different modalities and demonstrate that leveraging a large-scale EEG model can further enhance reconstruction performance by alleviating the challenges associated with limited data.
MindCross: Fast New Subject Adaptation with Limited Data for Cross-subject Video Reconstruction from Brain Signals
Nov 18, 2025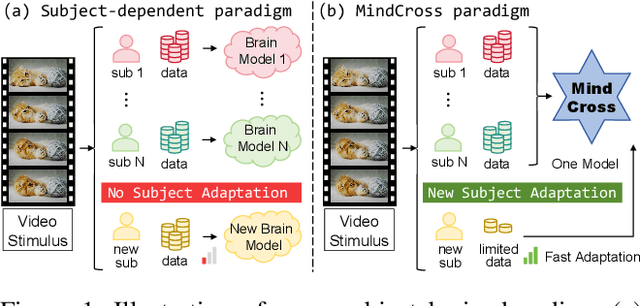
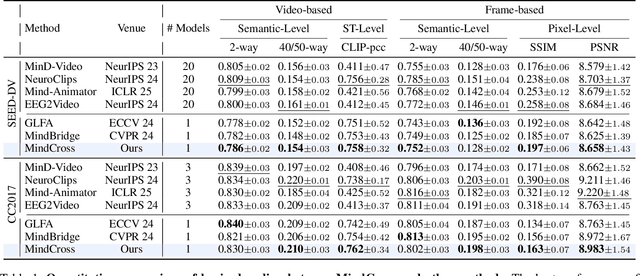
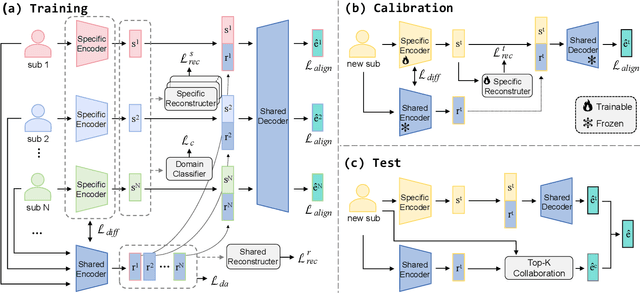
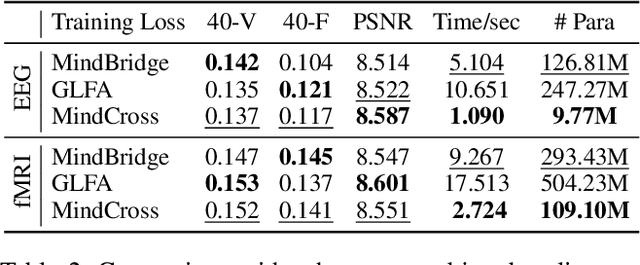
Reconstructing video from brain signals is an important brain decoding task. Existing brain decoding frameworks are primarily built on a subject-dependent paradigm, which requires large amounts of brain data for each subject. However, the expensive cost of collecting brain-video data causes severe data scarcity. Although some cross-subject methods being introduced, they often overfocus with subject-invariant information while neglecting subject-specific information, resulting in slow fine-tune-based adaptation strategy. To achieve fast and data-efficient new subject adaptation, we propose MindCross, a novel cross-subject framework. MindCross's N specific encoders and one shared encoder are designed to extract subject-specific and subject-invariant information, respectively. Additionally, a Top-K collaboration module is adopted to enhance new subject decoding with the knowledge learned from previous subjects' encoders. Extensive experiments on fMRI/EEG-to-video benchmarks demonstrate MindCross's efficacy and efficiency of cross-subject decoding and new subject adaptation using only one model.
Combining Induction and Transduction for Abstract Reasoning
Nov 04, 2024When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using a neural network? We study this question on ARC, a highly diverse dataset of abstract reasoning tasks. We train neural models for induction (inferring latent functions) and transduction (directly predicting the test output for a given test input). Our models are trained on synthetic data generated by prompting LLMs to produce Python code specifying a function to be inferred, plus a stochastic subroutine for generating inputs to that function. We find inductive and transductive models solve very different problems, despite training on the same problems, and despite sharing the same neural architecture.
FuseAnyPart: Diffusion-Driven Facial Parts Swapping via Multiple Reference Images
Oct 30, 2024Facial parts swapping aims to selectively transfer regions of interest from the source image onto the target image while maintaining the rest of the target image unchanged. Most studies on face swapping designed specifically for full-face swapping, are either unable or significantly limited when it comes to swapping individual facial parts, which hinders fine-grained and customized character designs. However, designing such an approach specifically for facial parts swapping is challenged by a reasonable multiple reference feature fusion, which needs to be both efficient and effective. To overcome this challenge, FuseAnyPart is proposed to facilitate the seamless "fuse-any-part" customization of the face. In FuseAnyPart, facial parts from different people are assembled into a complete face in latent space within the Mask-based Fusion Module. Subsequently, the consolidated feature is dispatched to the Addition-based Injection Module for fusion within the UNet of the diffusion model to create novel characters. Extensive experiments qualitatively and quantitatively validate the superiority and robustness of FuseAnyPart. Source codes are available at https://github.com/Thomas-wyh/FuseAnyPart.
Code Repair with LLMs gives an Exploration-Exploitation Tradeoff
May 26, 2024Iteratively improving and repairing source code with large language models (LLMs), known as refinement, has emerged as a popular way of generating programs that would be too complex to construct in one shot. Given a bank of test cases, together with a candidate program, an LLM can improve that program by being prompted with failed test cases. But it remains an open question how to best iteratively refine code, with prior work employing simple greedy or breadth-first strategies. We show here that refinement exposes an explore-exploit tradeoff: exploit by refining the program that passes the most test cases, or explore by refining a lesser considered program. We frame this as an arm-acquiring bandit problem, which we solve with Thompson Sampling. The resulting LLM-based program synthesis algorithm is broadly applicable: Across loop invariant synthesis, visual reasoning puzzles, and competition programming problems, we find that our new method can solve more problems using fewer language model calls.
Seeing through the Brain: Image Reconstruction of Visual Perception from Human Brain Signals
Aug 16, 2023



Seeing is believing, however, the underlying mechanism of how human visual perceptions are intertwined with our cognitions is still a mystery. Thanks to the recent advances in both neuroscience and artificial intelligence, we have been able to record the visually evoked brain activities and mimic the visual perception ability through computational approaches. In this paper, we pay attention to visual stimuli reconstruction by reconstructing the observed images based on portably accessible brain signals, i.e., electroencephalography (EEG) data. Since EEG signals are dynamic in the time-series format and are notorious to be noisy, processing and extracting useful information requires more dedicated efforts; In this paper, we propose a comprehensive pipeline, named NeuroImagen, for reconstructing visual stimuli images from EEG signals. Specifically, we incorporate a novel multi-level perceptual information decoding to draw multi-grained outputs from the given EEG data. A latent diffusion model will then leverage the extracted information to reconstruct the high-resolution visual stimuli images. The experimental results have illustrated the effectiveness of image reconstruction and superior quantitative performance of our proposed method.
Investigating EEG-Based Functional Connectivity Patterns for Multimodal Emotion Recognition
Apr 04, 2020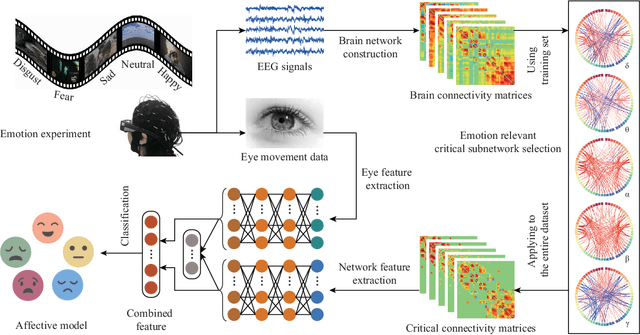
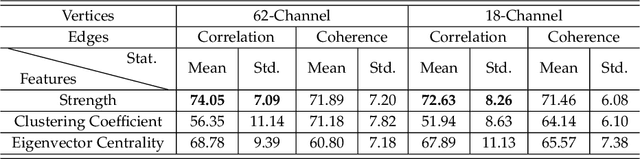
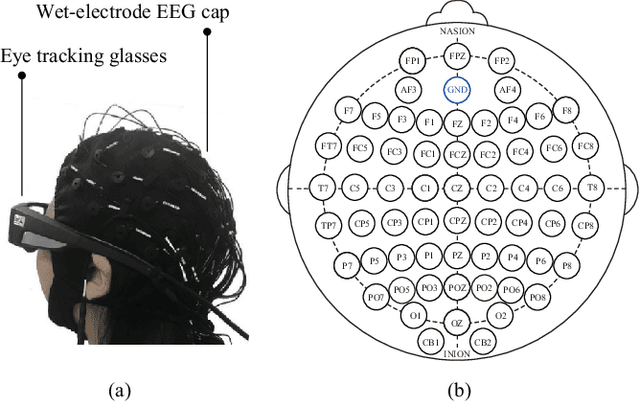
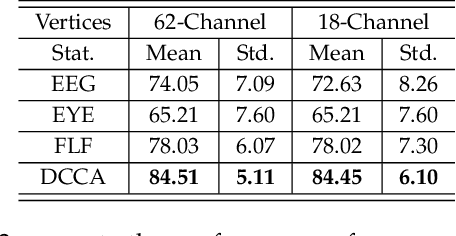
Compared with the rich studies on the motor brain-computer interface (BCI), the recently emerging affective BCI presents distinct challenges since the brain functional connectivity networks involving emotion are not well investigated. Previous studies on emotion recognition based on electroencephalography (EEG) signals mainly rely on single-channel-based feature extraction methods. In this paper, we propose a novel emotion-relevant critical subnetwork selection algorithm and investigate three EEG functional connectivity network features: strength, clustering coefficient, and eigenvector centrality. The discrimination ability of the EEG connectivity features in emotion recognition is evaluated on three public emotion EEG datasets: SEED, SEED-V, and DEAP. The strength feature achieves the best classification performance and outperforms the state-of-the-art differential entropy feature based on single-channel analysis. The experimental results reveal that distinct functional connectivity patterns are exhibited for the five emotions of disgust, fear, sadness, happiness, and neutrality. Furthermore, we construct a multimodal emotion recognition model by combining the functional connectivity features from EEG and the features from eye movements or physiological signals using deep canonical correlation analysis. The classification accuracies of multimodal emotion recognition are 95.08/6.42% on the SEED dataset, 84.51/5.11% on the SEED-V dataset, and 85.34/2.90% and 86.61/3.76% for arousal and valence on the DEAP dataset, respectively. The results demonstrate the complementary representation properties of the EEG connectivity features with eye movement data. In addition, we find that the brain networks constructed with 18 channels achieve comparable performance with that of the 62-channel network in multimodal emotion recognition and enable easier setups for BCI systems in real scenarios.
Multimodal Emotion Recognition Using Deep Canonical Correlation Analysis
Aug 13, 2019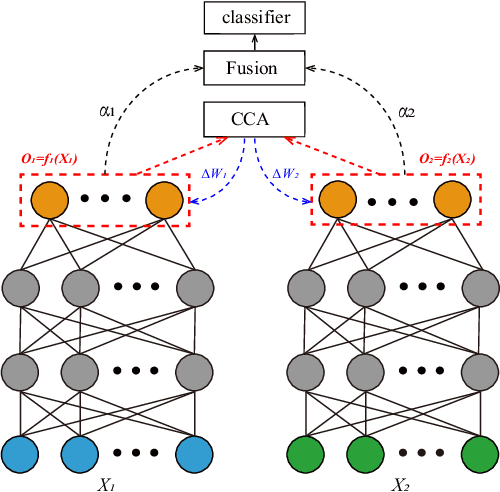
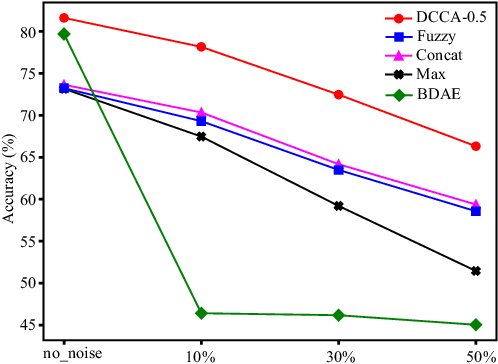
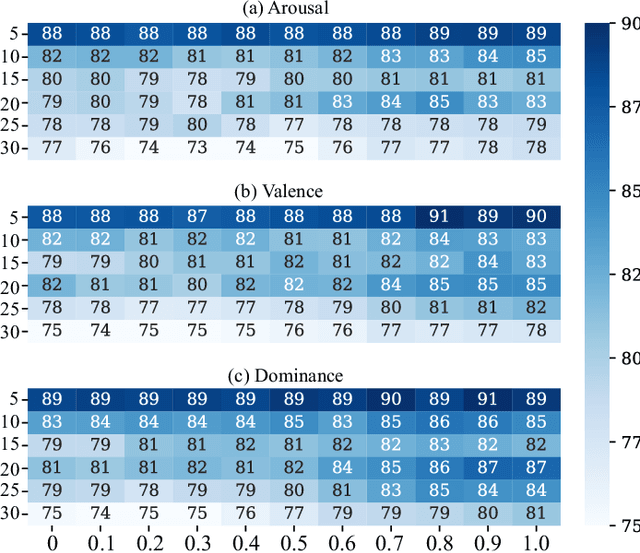
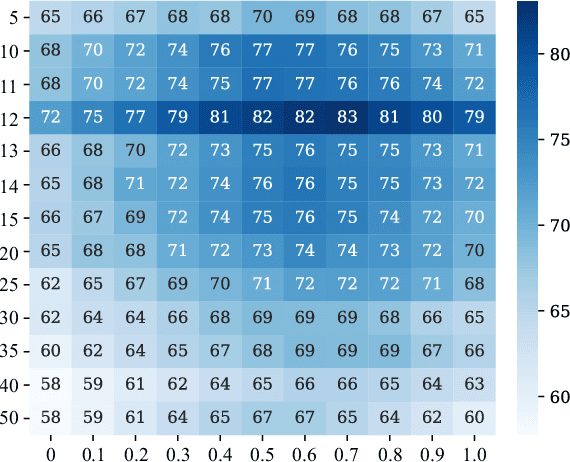
Multimodal signals are more powerful than unimodal data for emotion recognition since they can represent emotions more comprehensively. In this paper, we introduce deep canonical correlation analysis (DCCA) to multimodal emotion recognition. The basic idea behind DCCA is to transform each modality separately and coordinate different modalities into a hyperspace by using specified canonical correlation analysis constraints. We evaluate the performance of DCCA on five multimodal datasets: the SEED, SEED-IV, SEED-V, DEAP, and DREAMER datasets. Our experimental results demonstrate that DCCA achieves state-of-the-art recognition accuracy rates on all five datasets: 94.58% on the SEED dataset, 87.45% on the SEED-IV dataset, 84.33% and 85.62% for two binary classification tasks and 88.51% for a four-category classification task on the DEAP dataset, 83.08% on the SEED-V dataset, and 88.99%, 90.57%, and 90.67% for three binary classification tasks on the DREAMER dataset. We also compare the noise robustness of DCCA with that of existing methods when adding various amounts of noise to the SEED-V dataset. The experimental results indicate that DCCA has greater robustness. By visualizing feature distributions with t-SNE and calculating the mutual information between different modalities before and after using DCCA, we find that the features transformed by DCCA from different modalities are more homogeneous and discriminative across emotions.
Semi-supervised Deep Generative Modelling of Incomplete Multi-Modality Emotional Data
Jul 27, 2018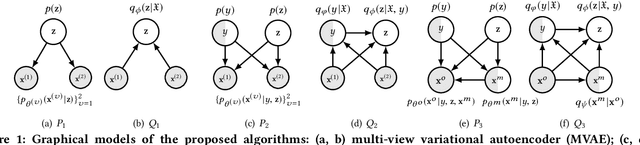

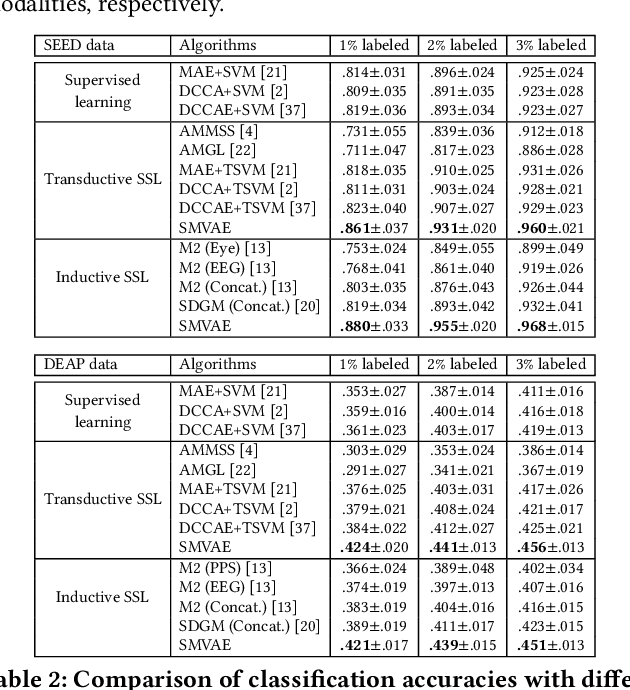
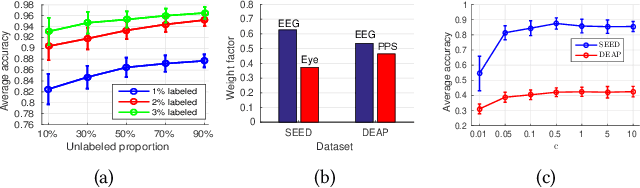
There are threefold challenges in emotion recognition. First, it is difficult to recognize human's emotional states only considering a single modality. Second, it is expensive to manually annotate the emotional data. Third, emotional data often suffers from missing modalities due to unforeseeable sensor malfunction or configuration issues. In this paper, we address all these problems under a novel multi-view deep generative framework. Specifically, we propose to model the statistical relationships of multi-modality emotional data using multiple modality-specific generative networks with a shared latent space. By imposing a Gaussian mixture assumption on the posterior approximation of the shared latent variables, our framework can learn the joint deep representation from multiple modalities and evaluate the importance of each modality simultaneously. To solve the labeled-data-scarcity problem, we extend our multi-view model to semi-supervised learning scenario by casting the semi-supervised classification problem as a specialized missing data imputation task. To address the missing-modality problem, we further extend our semi-supervised multi-view model to deal with incomplete data, where a missing view is treated as a latent variable and integrated out during inference. This way, the proposed overall framework can utilize all available (both labeled and unlabeled, as well as both complete and incomplete) data to improve its generalization ability. The experiments conducted on two real multi-modal emotion datasets demonstrated the superiority of our framework.
Multimodal Emotion Recognition Using Multimodal Deep Learning
Feb 26, 2016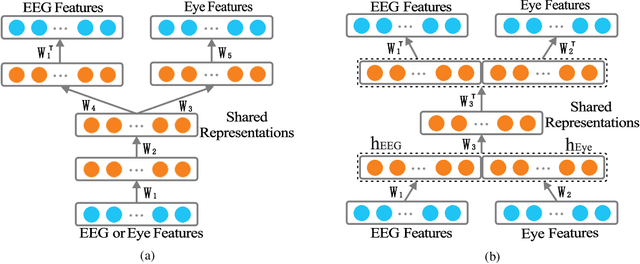
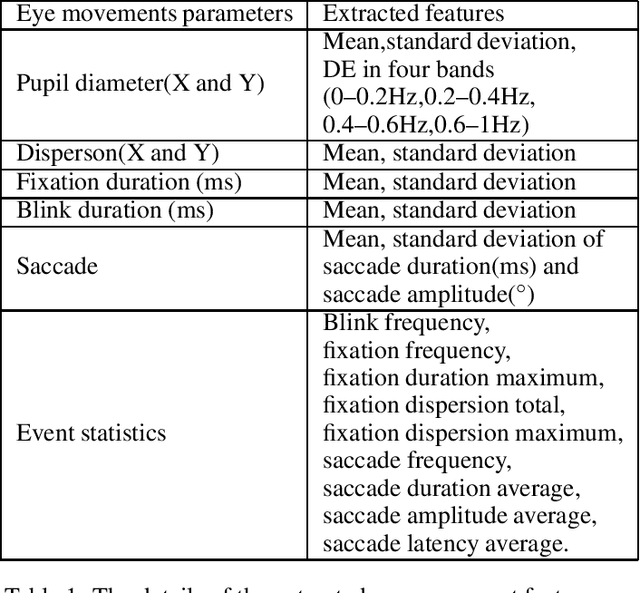
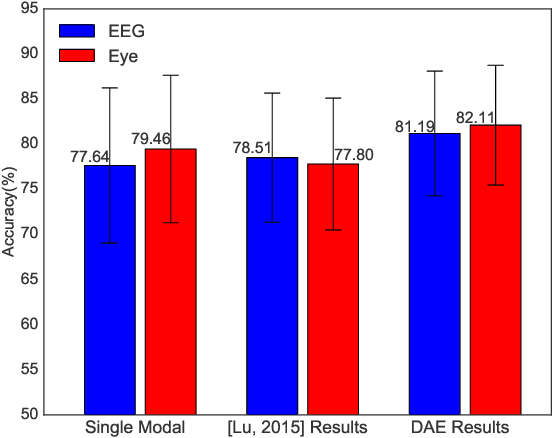
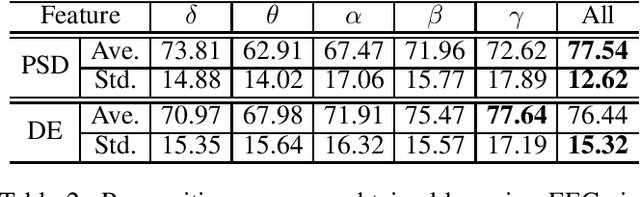
To enhance the performance of affective models and reduce the cost of acquiring physiological signals for real-world applications, we adopt multimodal deep learning approach to construct affective models from multiple physiological signals. For unimodal enhancement task, we indicate that the best recognition accuracy of 82.11% on SEED dataset is achieved with shared representations generated by Deep AutoEncoder (DAE) model. For multimodal facilitation tasks, we demonstrate that the Bimodal Deep AutoEncoder (BDAE) achieves the mean accuracies of 91.01% and 83.25% on SEED and DEAP datasets, respectively, which are much superior to the state-of-the-art approaches. For cross-modal learning task, our experimental results demonstrate that the mean accuracy of 66.34% is achieved on SEED dataset through shared representations generated by EEG-based DAE as training samples and shared representations generated by eye-based DAE as testing sample, and vice versa.