 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG-Verus: Repository-Level Program Verification with LLMs using Retrieval Augmented Generation
Feb 07, 2025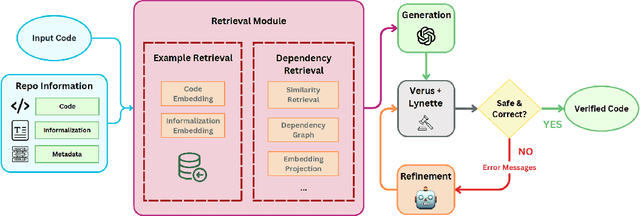
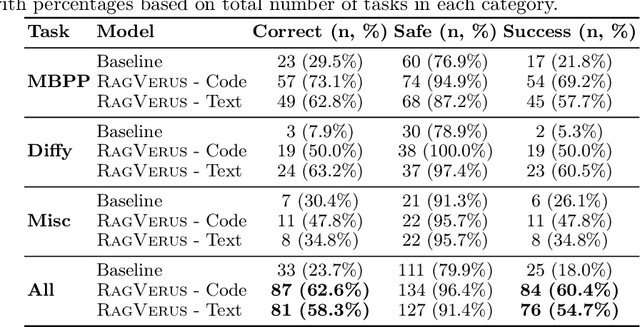
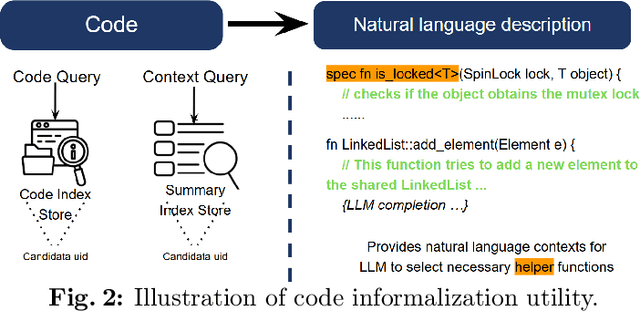
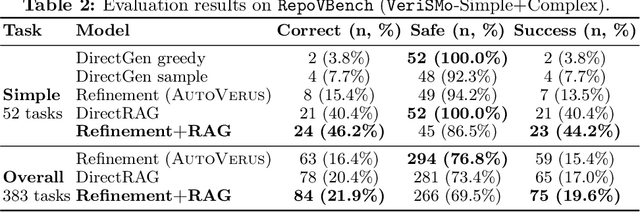
Scaling automated formal verification to real-world projects requires resolving cross-module dependencies and global contexts, which are challenges overlooked by existing function-centric methods. We introduce RagVerus, a framework that synergizes retrieval-augmented generation with context-aware prompting to automate proof synthesis for multi-module repositories, achieving a 27% relative improvement on our novel RepoVBench benchmark -- the first repository-level dataset for Verus with 383 proof completion tasks. RagVerus triples proof pass rates on existing benchmarks under constrained language model budgets, demonstrating a scalable and sample-efficient verification.
Code Repair with LLMs gives an Exploration-Exploitation Tradeoff
May 26, 2024Iteratively improving and repairing source code with large language models (LLMs), known as refinement, has emerged as a popular way of generating programs that would be too complex to construct in one shot. Given a bank of test cases, together with a candidate program, an LLM can improve that program by being prompted with failed test cases. But it remains an open question how to best iteratively refine code, with prior work employing simple greedy or breadth-first strategies. We show here that refinement exposes an explore-exploit tradeoff: exploit by refining the program that passes the most test cases, or explore by refining a lesser considered program. We frame this as an arm-acquiring bandit problem, which we solve with Thompson Sampling. The resulting LLM-based program synthesis algorithm is broadly applicable: Across loop invariant synthesis, visual reasoning puzzles, and competition programming problems, we find that our new method can solve more problems using fewer language model calls.
Safe Model-based Reinforcement Learning with Robust Cross-Entropy Method
Oct 15, 2020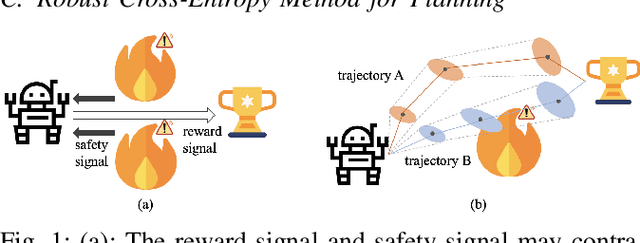
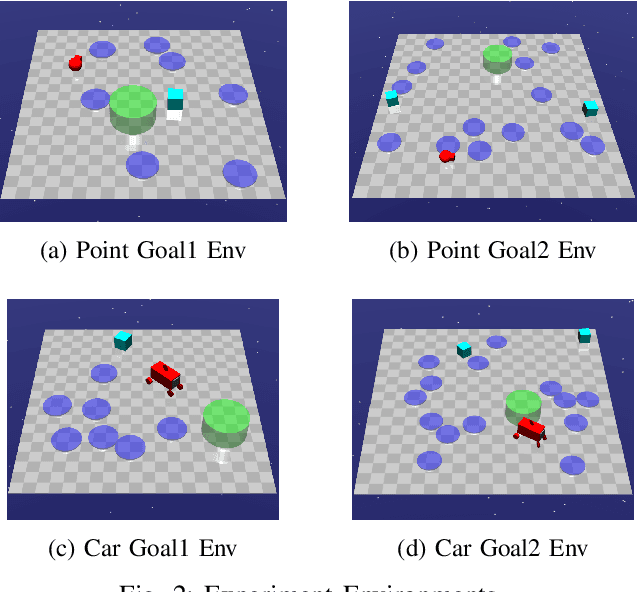
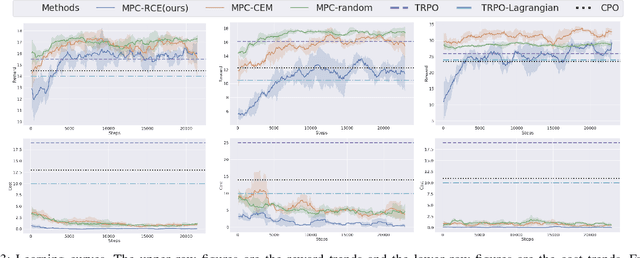
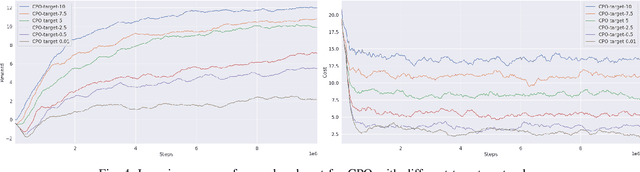
This paper studies the safe reinforcement learning (RL) problem without assumptions about prior knowledge of the system dynamics and the constraint function. We employ an uncertainty-aware neural network ensemble model to learn the dynamics, and we infer the unknown constraint function through indicator constraint violation signals. We use model predictive control (MPC) as the basic control framework and propose the robust cross-entropy method (RCE) to optimize the control sequence considering the model uncertainty and constraints. We evaluate our methods in the Safety Gym environment. The results show that our approach achieves better constraint satisfaction than baseline safe RL methods while maintaining good task performance. Additionally, we are able to achieve several orders of magnitude better sample efficiency when compared to constrained model-free RL approaches. The code is available at https://github.com/liuzuxin/safe-mbrl.