 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAIR-Former: Budgeted Relational MIL for miRNA Target Prediction
Jan 31, 2026Functional miRNA--mRNA targeting is a large-bag prediction problem: each transcript yields a heavy-tailed pool of candidate target sites (CTSs), yet only a pair-level label is observed. We formalize this regime as \emph{Budgeted Relational Multi-Instance Learning (BR-MIL)}, where at most $K$ instances per bag may receive expensive encoding and relational processing under a hard compute budget. We propose \textbf{PAIR-Former} (Pool-Aware Instance-Relational Transformer), a BR-MIL pipeline that performs a cheap full-pool scan, selects up to $K$ diverse CTSs on CPU, and applies a permutation-invariant Set Transformer aggregator on the selected tokens. On miRAW, PAIR-Former outperforms strong pooling baselines at a practical operating budget ($K^\star{=}64$) while providing a controllable accuracy--compute trade-off as $K$ varies. We further provide theory linking budgeted selection to (i) approximation error decreasing with $K$ and (ii) generalization terms governed by $K$ in the expensive relational component.
Context-Aware Safe Reinforcement Learning for Non-Stationary Environments
Jan 02, 2021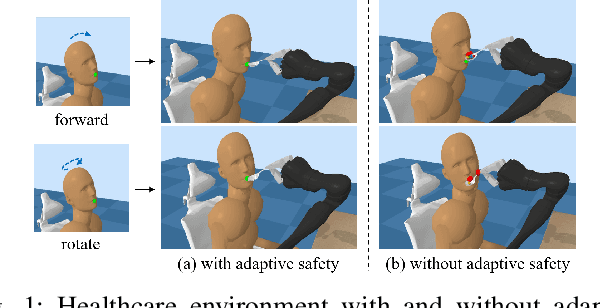
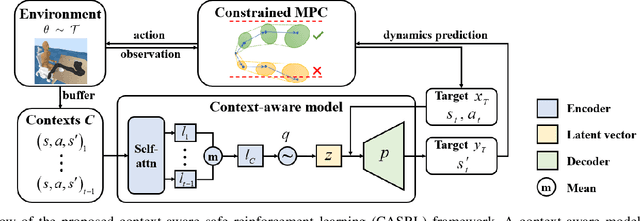
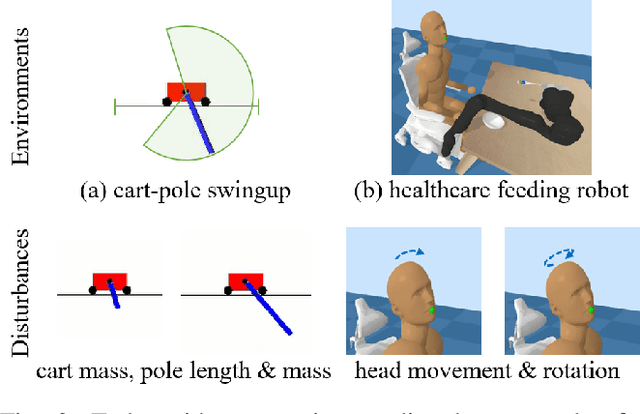
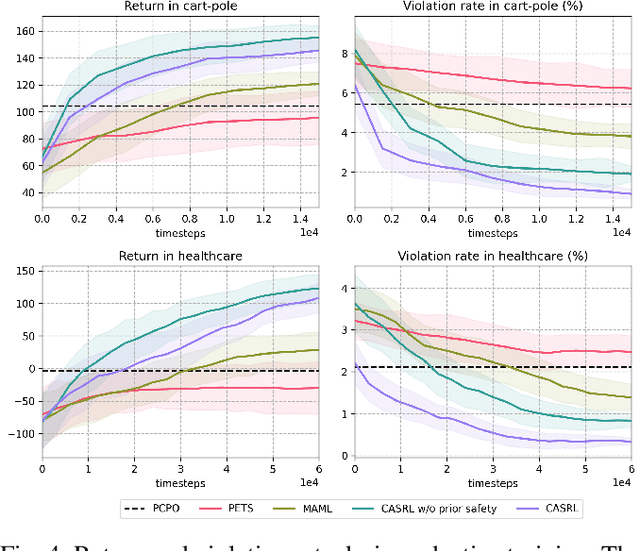
Safety is a critical concern when deploying reinforcement learning agents for realistic tasks. Recently, safe reinforcement learning algorithms have been developed to optimize the agent's performance while avoiding violations of safety constraints. However, few studies have addressed the non-stationary disturbances in the environments, which may cause catastrophic outcomes. In this paper, we propose the context-aware safe reinforcement learning (CASRL) method, a meta-learning framework to realize safe adaptation in non-stationary environments. We use a probabilistic latent variable model to achieve fast inference of the posterior environment transition distribution given the context data. Safety constraints are then evaluated with uncertainty-aware trajectory sampling. The high cost of safety violations leads to the rareness of unsafe records in the dataset. We address this issue by enabling prioritized sampling during model training and formulating prior safety constraints with domain knowledge during constrained planning. The algorithm is evaluated in realistic safety-critical environments with non-stationary disturbances. Results show that the proposed algorithm significantly outperforms existing baselines in terms of safety and robustness.
Safe Model-based Reinforcement Learning with Robust Cross-Entropy Method
Oct 15, 2020
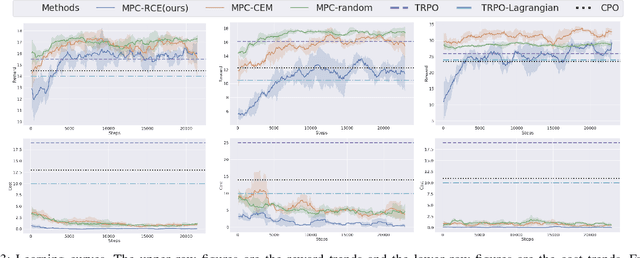
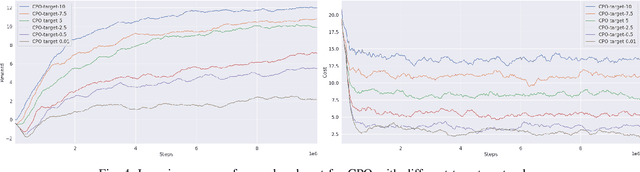
This paper studies the safe reinforcement learning (RL) problem without assumptions about prior knowledge of the system dynamics and the constraint function. We employ an uncertainty-aware neural network ensemble model to learn the dynamics, and we infer the unknown constraint function through indicator constraint violation signals. We use model predictive control (MPC) as the basic control framework and propose the robust cross-entropy method (RCE) to optimize the control sequence considering the model uncertainty and constraints. We evaluate our methods in the Safety Gym environment. The results show that our approach achieves better constraint satisfaction than baseline safe RL methods while maintaining good task performance. Additionally, we are able to achieve several orders of magnitude better sample efficiency when compared to constrained model-free RL approaches. The code is available at https://github.com/liuzuxin/safe-mbrl.
Multimodal Safety-Critical Scenarios Generation for Decision-Making Algorithms Evaluation
Sep 25, 2020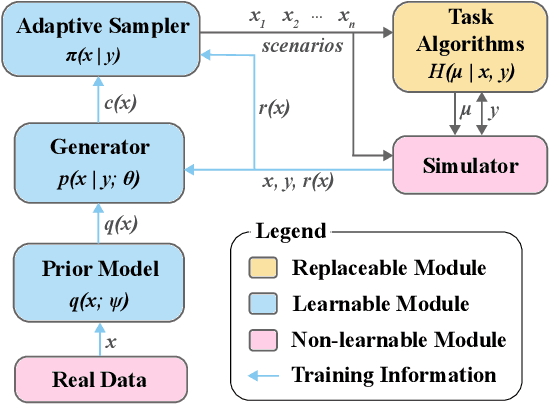

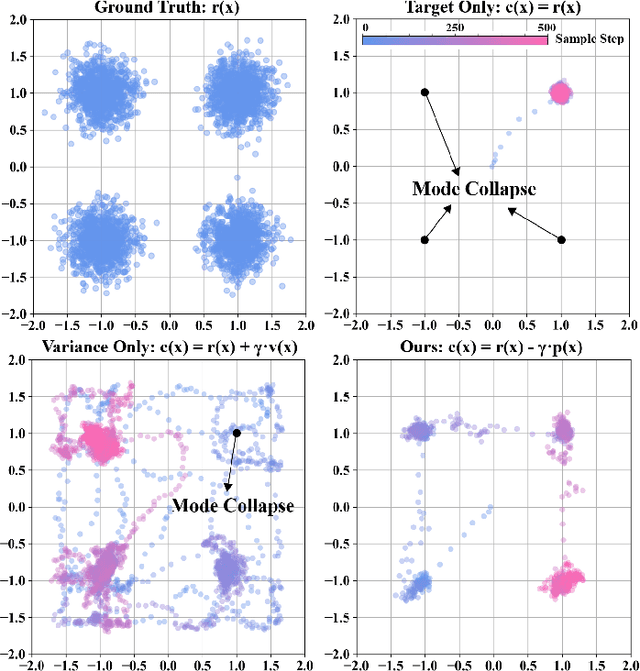
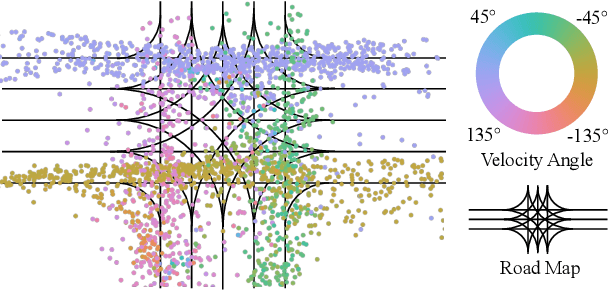
Existing neural network-based autonomous systems are shown to be vulnerable against adversarial attacks, therefore sophisticated evaluation on their robustness is of great importance. However, evaluating the robustness only under the worst-case scenarios based on known attacks is not comprehensive, not to mention that some of them even rarely occur in the real world. In addition, the distribution of safety-critical data is usually multimodal, while most traditional attacks and evaluation methods focus on a single modality. To solve the above challenges, we propose a flow-based multimodal safety-critical scenario generator for evaluating decisionmaking algorithms. The proposed generative model is optimized with weighted likelihood maximization and a gradient-based sampling procedure is integrated to improve the sampling efficiency. The safety-critical scenarios are generated by querying the task algorithms and the log-likelihood of the generated scenarios is in proportion to the risk level. Experiments on a self-driving task demonstrate our advantages in terms of testing efficiency and multimodal modeling capability. We evaluate six Reinforcement Learning algorithms with our generated traffic scenarios and provide empirical conclusions about their robustness.
MAPPER: Multi-Agent Path Planning with Evolutionary Reinforcement Learning in Mixed Dynamic Environments
Jul 30, 2020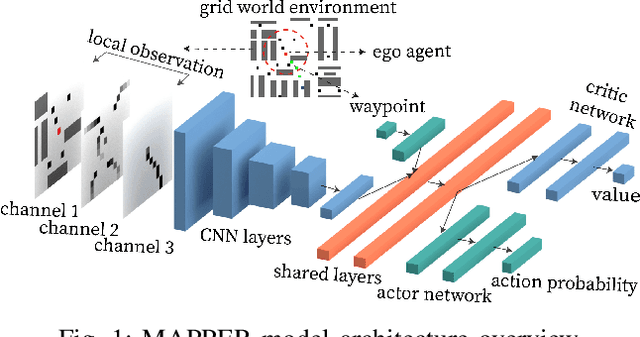
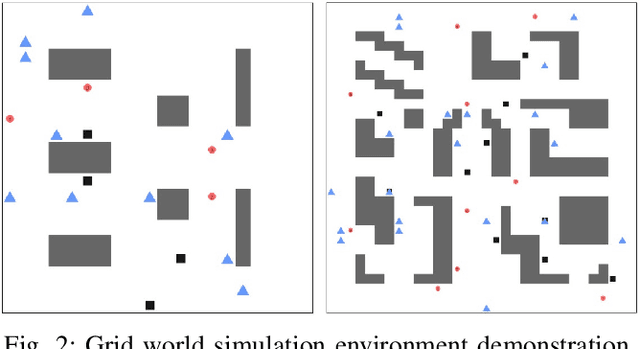
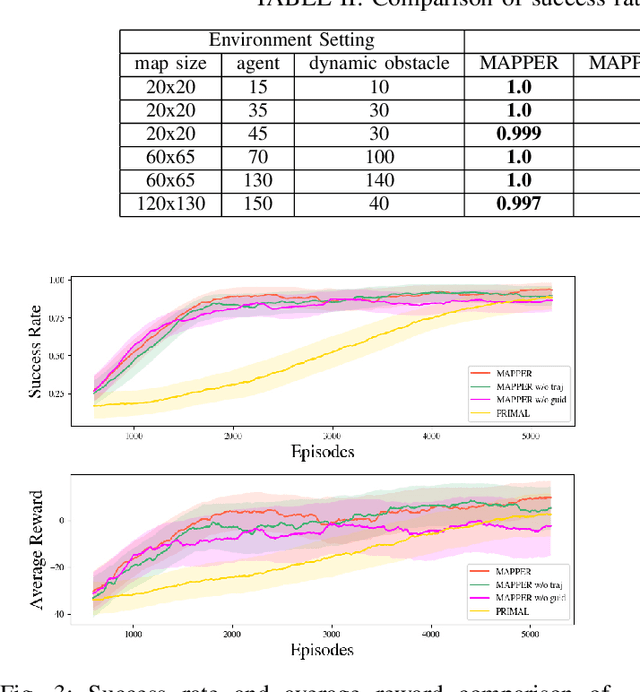
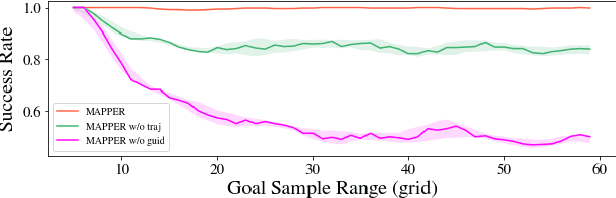
Multi-agent navigation in dynamic environments is of great industrial value when deploying a large scale fleet of robot to real-world applications. This paper proposes a decentralized partially observable multi-agent path planning with evolutionary reinforcement learning (MAPPER) method to learn an effective local planning policy in mixed dynamic environments. Reinforcement learning-based methods usually suffer performance degradation on long-horizon tasks with goal-conditioned sparse rewards, so we decompose the long-range navigation task into many easier sub-tasks under the guidance of a global planner, which increases agents' performance in large environments. Moreover, most existing multi-agent planning approaches assume either perfect information of the surrounding environment or homogeneity of nearby dynamic agents, which may not hold in practice. Our approach models dynamic obstacles' behavior with an image-based representation and trains a policy in mixed dynamic environments without homogeneity assumption. To ensure multi-agent training stability and performance, we propose an evolutionary training approach that can be easily scaled to large and complex environments. Experiments show that MAPPER is able to achieve higher success rates and more stable performance when exposed to a large number of non-cooperative dynamic obstacles compared with traditional reaction-based planner LRA* and the state-of-the-art learning-based method.
Task-Agnostic Online Reinforcement Learning with an Infinite Mixture of Gaussian Processes
Jun 29, 2020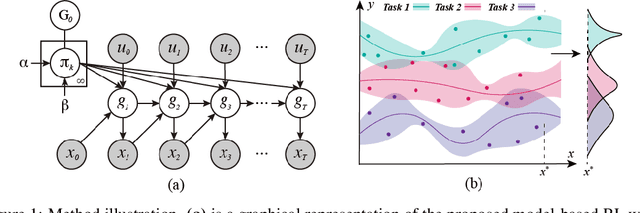
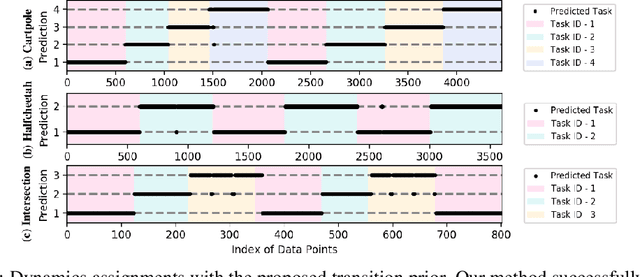
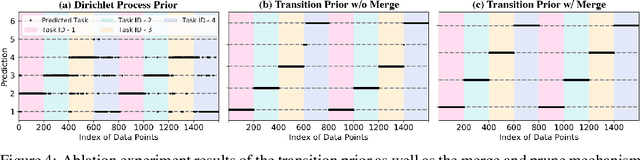
Continuously learning to solve unseen tasks with limited experience has been extensively pursued in meta-learning and continual learning, but with restricted assumptions such as accessible task distributions, independently and identically distributed tasks, and clear task delineations. However, real-world physical tasks frequently violate these assumptions, resulting in performance degradation. This paper proposes a continual online model-based reinforcement learning approach that does not require pre-training to solve task-agnostic problems with unknown task boundaries. We maintain a mixture of experts to handle nonstationarity, and represent each different type of dynamics with a Gaussian Process to efficiently leverage collected data and expressively model uncertainty. We propose a transition prior to account for the temporal dependencies in streaming data and update the mixture online via sequential variational inference. Our approach reliably handles the task distribution shift by generating new models for never-before-seen dynamics and reusing old models for previously seen dynamics. In experiments, our approach outperforms alternative methods in non-stationary tasks, including classic control with changing dynamics and decision making in different driving scenarios.
Delay-Aware Multi-Agent Reinforcement Learning
May 11, 2020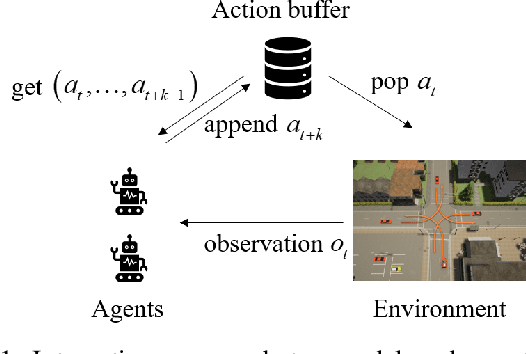
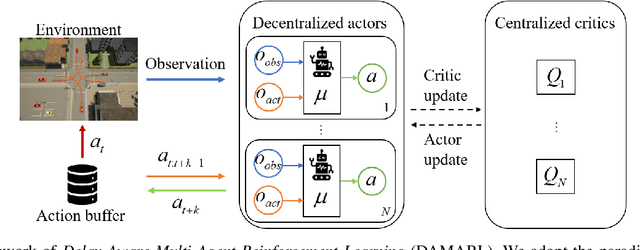
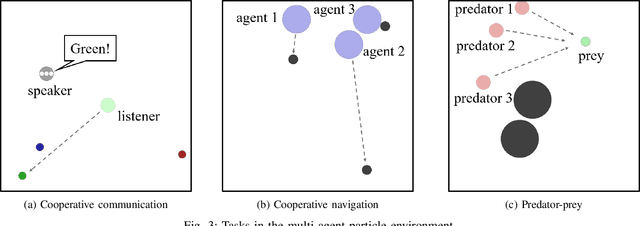
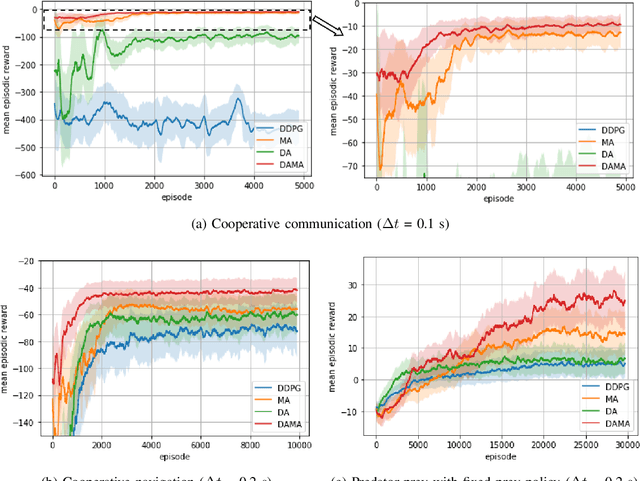
Action and observation delays exist prevalently in the real-world cyber-physical systems which may pose challenges in reinforcement learning design. It is particularly an arduous task when handling multi-agent systems where the delay of one agent could spread to other agents. To resolve this problem, this paper proposes a novel framework to deal with delays as well as the non-stationary training issue of multi-agent tasks with model-free deep reinforcement learning. We formally define the Delay-Aware Markov Game that incorporates the delays of all agents in the environment. To solve Delay-Aware Markov Games, we apply centralized training and decentralized execution that allows agents to use extra information to ease the non-stationary issue of the multi-agent systems during training, without the need of a centralized controller during execution. Experiments are conducted in multi-agent particle environments including cooperative communication, cooperative navigation, and competitive experiments. We also test the proposed algorithm in traffic scenarios that require coordination of all autonomous vehicles to show the practical value of delay-awareness. Results show that the proposed delay-aware multi-agent reinforcement learning algorithm greatly alleviates the performance degradation introduced by delay. Codes available at: https://github.com/baimingc/damarl.
Delay-Aware Model-Based Reinforcement Learning for Continuous Control
May 11, 2020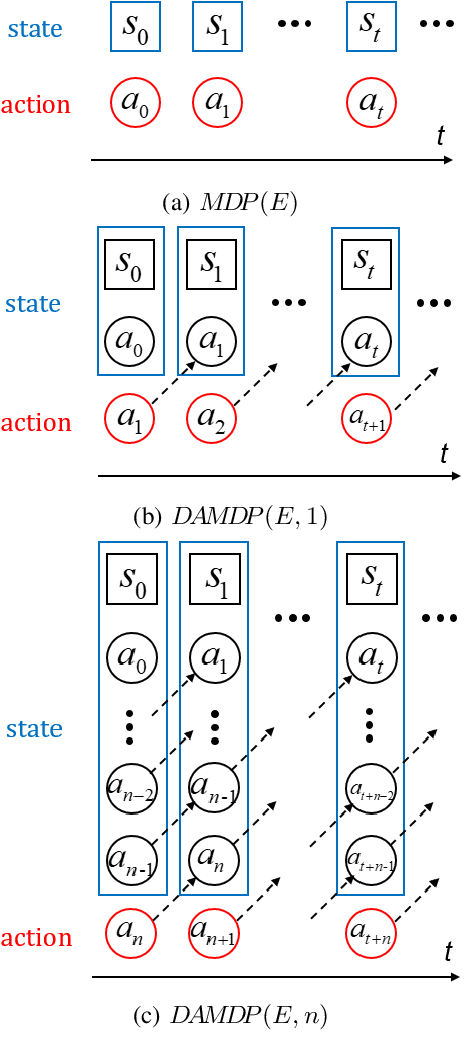
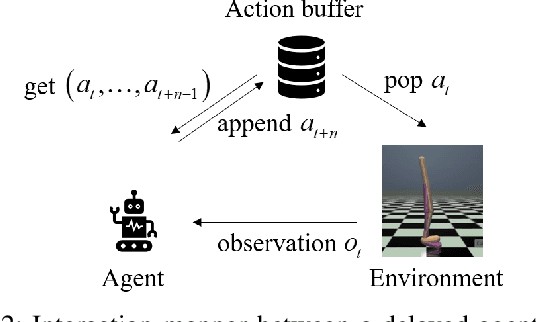
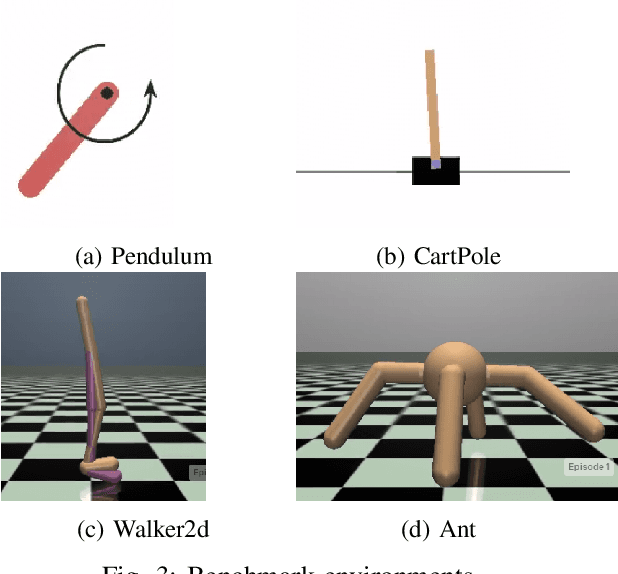
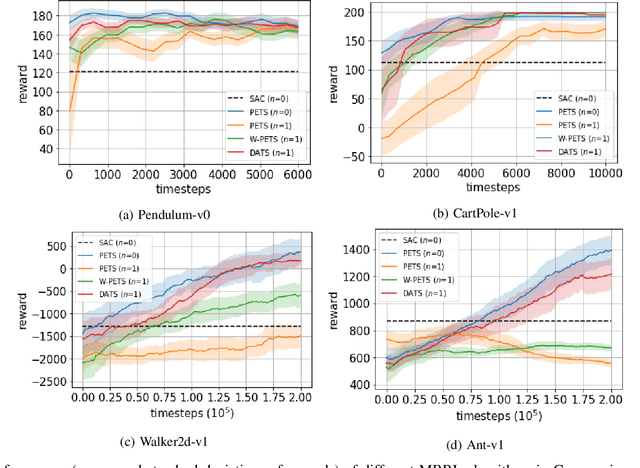
Action delays degrade the performance of reinforcement learning in many real-world systems. This paper proposes a formal definition of delay-aware Markov Decision Process and proves it can be transformed into standard MDP with augmented states using the Markov reward process. We develop a delay-aware model-based reinforcement learning framework that can incorporate the multi-step delay into the learned system models without learning effort. Experiments with the Gym and MuJoCo platforms show that the proposed delay-aware model-based algorithm is more efficient in training and transferable between systems with various durations of delay compared with off-policy model-free reinforcement learning methods. Codes available at: https://github.com/baimingc/dambrl.
Adversarial Evaluation of Autonomous Vehicles in Lane-Change Scenarios
Apr 14, 2020
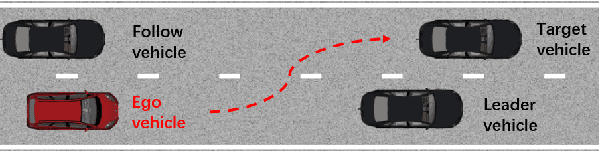

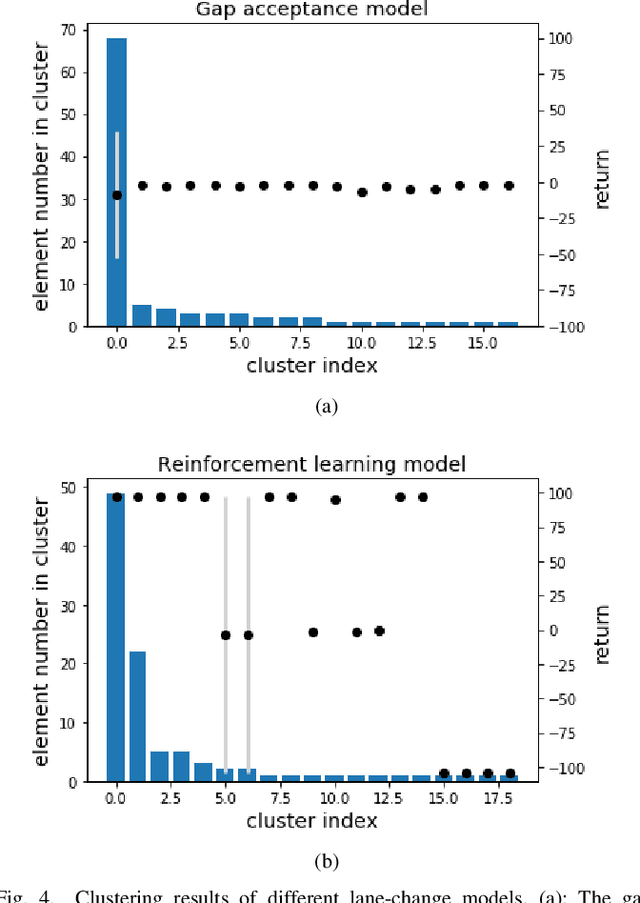
Autonomous vehicles must be comprehensively evaluated before deployed in cities and highways. Current evaluation procedures lack the abilities of weakness-aiming and evolving, thus they could hardly generate adversarial environments for autonomous vehicles, leading to insufficient challenges. To overcome the shortage of static evaluation methods, this paper proposes a novel method to generate adversarial environments with deep reinforcement learning, and to cluster them with a nonparametric Bayesian method. As a representative task of autonomous driving, lane-change is used to demonstrate the superiority of the proposed method. First, two lane-change models are separately developed by a rule-based method and a learning-based method, waiting for evaluation and comparison. Next, adversarial environments are generated by training surrounding interactive vehicles with deep reinforcement learning for local optimal ensembles. Then, a nonparametric Bayesian approach is utilized to cluster the adversarial policies of the interactive vehicles. Finally, the adversarial environment patterns are illustrated and the performances of two lane-change models are evaluated and compared. The simulation results indicate that both models perform significantly worse in adversarial environments than in naturalistic environments, with plenty of weaknesses successfully extracted in a few tests.
Evaluation of Automated Vehicles Encountering Pedestrians at Unsignalized Crossings
Mar 28, 2017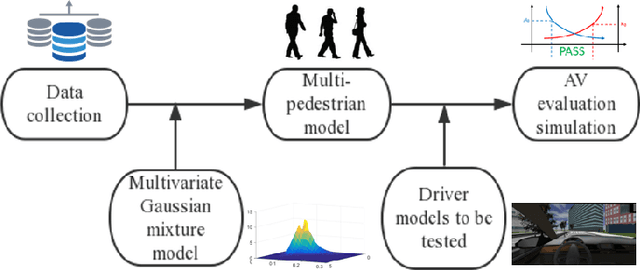
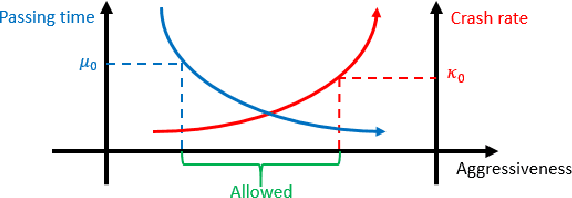
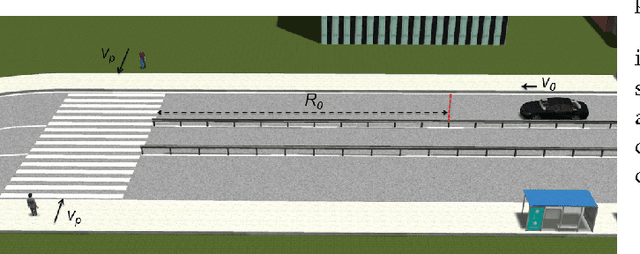
Interactions between vehicles and pedestrians have always been a major problem in traffic safety. Experienced human drivers are able to analyze the environment and choose driving strategies that will help them avoid crashes. What is not yet clear, however, is how automated vehicles will interact with pedestrians. This paper proposes a new method for evaluating the safety and feasibility of the driving strategy of automated vehicles when encountering unsignalized crossings. MobilEye sensors installed on buses in Ann Arbor, Michigan, collected data on 2,973 valid crossing events. A stochastic interaction model was then created using a multivariate Gaussian mixture model. This model allowed us to simulate the movements of pedestrians reacting to an oncoming vehicle when approaching unsignalized crossings, and to evaluate the passing strategies of automated vehicles. A simulation was then conducted to demonstrate the evaluation procedure.