 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPPER: Multi-Agent Path Planning with Evolutionary Reinforcement Learning in Mixed Dynamic Environments
Jul 30, 2020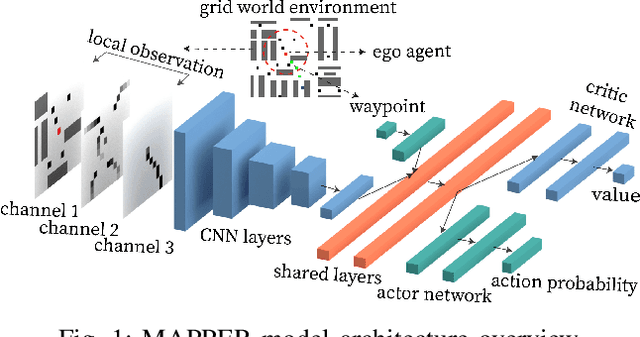
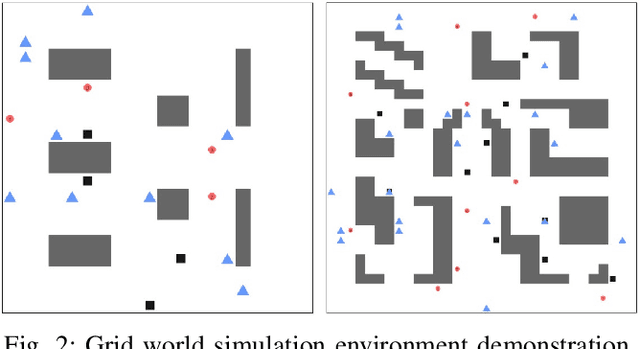
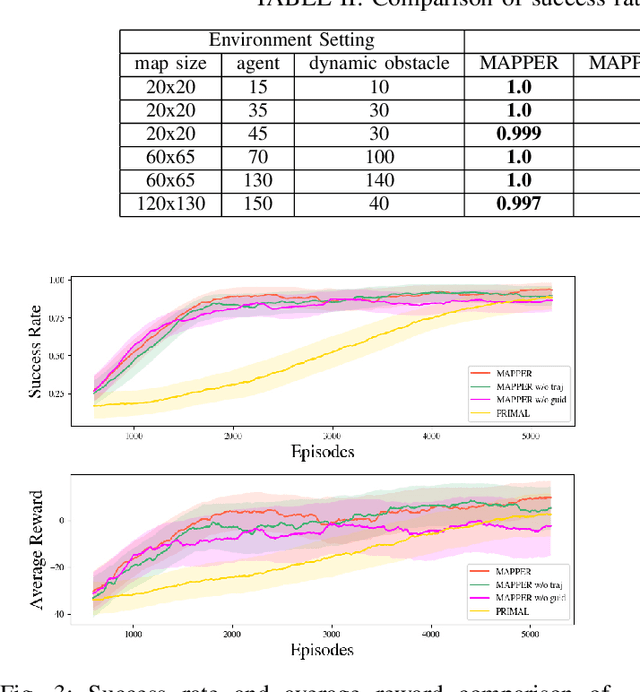
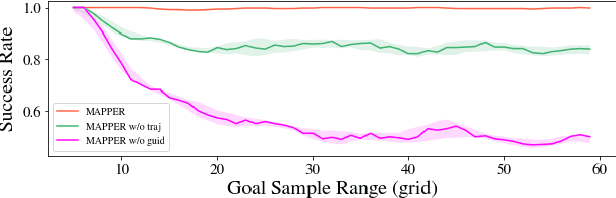
Multi-agent navigation in dynamic environments is of great industrial value when deploying a large scale fleet of robot to real-world applications. This paper proposes a decentralized partially observable multi-agent path planning with evolutionary reinforcement learning (MAPPER) method to learn an effective local planning policy in mixed dynamic environments. Reinforcement learning-based methods usually suffer performance degradation on long-horizon tasks with goal-conditioned sparse rewards, so we decompose the long-range navigation task into many easier sub-tasks under the guidance of a global planner, which increases agents' performance in large environments. Moreover, most existing multi-agent planning approaches assume either perfect information of the surrounding environment or homogeneity of nearby dynamic agents, which may not hold in practice. Our approach models dynamic obstacles' behavior with an image-based representation and trains a policy in mixed dynamic environments without homogeneity assumption. To ensure multi-agent training stability and performance, we propose an evolutionary training approach that can be easily scaled to large and complex environments. Experiments show that MAPPER is able to achieve higher success rates and more stable performance when exposed to a large number of non-cooperative dynamic obstacles compared with traditional reaction-based planner LRA* and the state-of-the-art learning-based method.