 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoDoMoDo: Multi-Domain Data Mixtures for Multimodal LLM Reinforcement Learning
May 30, 2025



Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a powerful paradigm for post-training large language models (LLMs), achieving state-of-the-art performance on tasks with structured, verifiable answers. Applying RLVR to Multimodal LLMs (MLLMs) presents significant opportunities but is complicated by the broader, heterogeneous nature of vision-language tasks that demand nuanced visual, logical, and spatial capabilities. As such, training MLLMs using RLVR on multiple datasets could be beneficial but creates challenges with conflicting objectives from interaction among diverse datasets, highlighting the need for optimal dataset mixture strategies to improve generalization and reasoning. We introduce a systematic post-training framework for Multimodal LLM RLVR, featuring a rigorous data mixture problem formulation and benchmark implementation. Specifically, (1) We developed a multimodal RLVR framework for multi-dataset post-training by curating a dataset that contains different verifiable vision-language problems and enabling multi-domain online RL learning with different verifiable rewards; (2) We proposed a data mixture strategy that learns to predict the RL fine-tuning outcome from the data mixture distribution, and consequently optimizes the best mixture. Comprehensive experiments showcase that multi-domain RLVR training, when combined with mixture prediction strategies, can significantly boost MLLM general reasoning capacities. Our best mixture improves the post-trained model's accuracy on out-of-distribution benchmarks by an average of 5.24% compared to the same model post-trained with uniform data mixture, and by a total of 20.74% compared to the pre-finetuning baseline.
Dynamics as Prompts: In-Context Learning for Sim-to-Real System Identifications
Oct 27, 2024Sim-to-real transfer remains a significant challenge in robotics due to the discrepancies between simulated and real-world dynamics. Traditional methods like Domain Randomization often fail to capture fine-grained dynamics, limiting their effectiveness for precise control tasks. In this work, we propose a novel approach that dynamically adjusts simulation environment parameters online using in-context learning. By leveraging past interaction histories as context, our method adapts the simulation environment dynamics to real-world dynamics without requiring gradient updates, resulting in faster and more accurate alignment between simulated and real-world performance. We validate our approach across two tasks: object scooping and table air hockey. In the sim-to-sim evaluations, our method significantly outperforms the baselines on environment parameter estimation by 80% and 42% in the object scooping and table air hockey setups, respectively. Furthermore, our method achieves at least 70% success rate in sim-to-real transfer on object scooping across three different objects. By incorporating historical interaction data, our approach delivers efficient and smooth system identification, advancing the deployment of robots in dynamic real-world scenarios. Demos are available on our project page: https://sim2real-capture.github.io/
Creative Robot Tool Use with Large Language Models
Oct 19, 2023



Tool use is a hallmark of advanced intelligence, exemplified in both animal behavior and robotic capabilities. This paper investigates the feasibility of imbuing robots with the ability to creatively use tools in tasks that involve implicit physical constraints and long-term planning. Leveraging Large Language Models (LLMs), we develop RoboTool, a system that accepts natural language instructions and outputs executable code for controlling robots in both simulated and real-world environments. RoboTool incorporates four pivotal components: (i) an "Analyzer" that interprets natural language to discern key task-related concepts, (ii) a "Planner" that generates comprehensive strategies based on the language input and key concepts, (iii) a "Calculator" that computes parameters for each skill, and (iv) a "Coder" that translates these plans into executable Python code. Our results show that RoboTool can not only comprehend explicit or implicit physical constraints and environmental factors but also demonstrate creative tool use. Unlike traditional Task and Motion Planning (TAMP) methods that rely on explicit optimization, our LLM-based system offers a more flexible, efficient, and user-friendly solution for complex robotics tasks. Through extensive experiments, we validate that RoboTool is proficient in handling tasks that would otherwise be infeasible without the creative use of tools, thereby expanding the capabilities of robotic systems. Demos are available on our project page: https://creative-robotool.github.io/.
Adaptive Online Replanning with Diffusion Models
Oct 14, 2023



Diffusion models have risen as a promising approach to data-driven planning, and have demonstrated impressive robotic control, reinforcement learning, and video planning performance. Given an effective planner, an important question to consider is replanning -- when given plans should be regenerated due to both action execution error and external environment changes. Direct plan execution, without replanning, is problematic as errors from individual actions rapidly accumulate and environments are partially observable and stochastic. Simultaneously, replanning at each timestep incurs a substantial computational cost, and may prevent successful task execution, as different generated plans prevent consistent progress to any particular goal. In this paper, we explore how we may effectively replan with diffusion models. We propose a principled approach to determine when to replan, based on the diffusion model's estimated likelihood of existing generated plans. We further present an approach to replan existing trajectories to ensure that new plans follow the same goal state as the original trajectory, which may efficiently bootstrap off previously generated plans. We illustrate how a combination of our proposed additions significantly improves the performance of diffusion planners leading to 38\% gains over past diffusion planning approaches on Maze2D, and further enables the handling of stochastic and long-horizon robotic control tasks. Videos can be found on the anonymous website: \url{https://vis-www.cs.umass.edu/replandiffuser/}.
Guardians as You Fall: Active Mode Transition for Safe Falling
Oct 07, 2023Recent advancements in optimal control and reinforcement learning have enabled quadrupedal robots to perform various agile locomotion tasks over diverse terrains. During these agile motions, ensuring the stability and resiliency of the robot is a primary concern to prevent catastrophic falls and mitigate potential damages. Previous methods primarily focus on recovery policies after the robot falls. There is no active safe falling solution to the best of our knowledge. In this paper, we proposed Guardians as You Fall (GYF), a safe falling/tumbling and recovery framework that can actively tumble and recover to stable modes to reduce damage in highly dynamic scenarios. The key idea of GYF is to adaptively traverse different stable modes via active tumbling before the robot shifts to irrecoverable poses. Via comprehensive simulation and real-world experiments, we show that GYF significantly reduces the maximum acceleration and jerk of the robot base compared to the baselines. In particular, GYF reduces the maximum acceleration and jerk by 20%~73% in different scenarios in simulation and real-world experiments. GYF offers a new perspective on safe falling and recovery in locomotion tasks, potentially enabling much more aggressive explorations of existing agile locomotion skills.
What Went Wrong? Closing the Sim-to-Real Gap via Differentiable Causal Discovery
Jun 28, 2023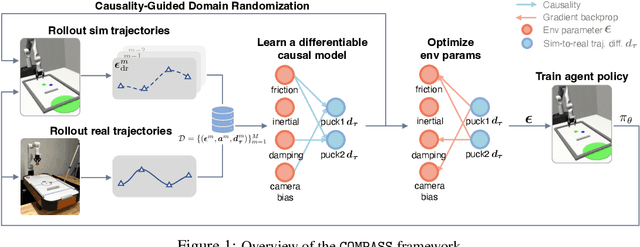

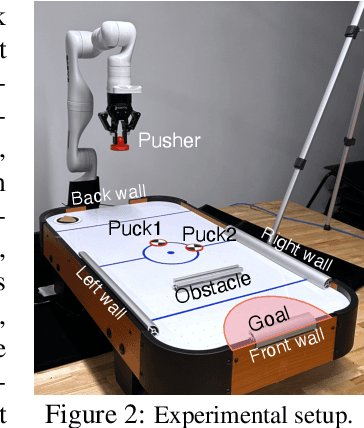

Training control policies in simulation is more appealing than on real robots directly, as it allows for exploring diverse states in a safe and efficient manner. Yet, robot simulators inevitably exhibit disparities from the real world, yielding inaccuracies that manifest as the simulation-to-real gap. Existing literature has proposed to close this gap by actively modifying specific simulator parameters to align the simulated data with real-world observations. However, the set of tunable parameters is usually manually selected to reduce the search space in a case-by-case manner, which is hard to scale up for complex systems and requires extensive domain knowledge. To address the scalability issue and automate the parameter-tuning process, we introduce an approach that aligns the simulator with the real world by discovering the causal relationship between the environment parameters and the sim-to-real gap. Concretely, our method learns a differentiable mapping from the environment parameters to the differences between simulated and real-world robot-object trajectories. This mapping is governed by a simultaneously-learned causal graph to help prune the search space of parameters, provide better interpretability, and improve generalization. We perform experiments to achieve both sim-to-sim and sim-to-real transfer, and show that our method has significant improvements in trajectory alignment and task success rate over strong baselines in a challenging manipulation task.
Embodied Executable Policy Learning with Language-based Scene Summarization
Jun 09, 2023Large Language models (LLMs) have shown remarkable success in assisting robot learning tasks, i.e., complex household planning. However, the performance of pretrained LLMs heavily relies on domain-specific templated text data, which may be infeasible in real-world robot learning tasks with image-based observations. Moreover, existing LLMs with text inputs lack the capability to evolve with non-expert interactions with environments. In this work, we introduce a novel learning paradigm that generates robots' executable actions in the form of text, derived solely from visual observations, using language-based summarization of these observations as the connecting bridge between both domains. Our proposed paradigm stands apart from previous works, which utilized either language instructions or a combination of language and visual data as inputs. Moreover, our method does not require oracle text summarization of the scene, eliminating the need for human involvement in the learning loop, which makes it more practical for real-world robot learning tasks. Our proposed paradigm consists of two modules: the SUM module, which interprets the environment using visual observations and produces a text summary of the scene, and the APM module, which generates executable action policies based on the natural language descriptions provided by the SUM module. We demonstrate that our proposed method can employ two fine-tuning strategies, including imitation learning and reinforcement learning approaches, to adapt to the target test tasks effectively. We conduct extensive experiments involving various SUM/APM model selections, environments, and tasks across 7 house layouts in the VirtualHome environment. Our experimental results demonstrate that our method surpasses existing baselines, confirming the effectiveness of this novel learning paradigm.
Hyper-Decision Transformer for Efficient Online Policy Adaptation
Apr 17, 2023Decision Transformers (DT) have demonstrated strong performances in offline reinforcement learning settings, but quickly adapting to unseen novel tasks remains challenging. To address this challenge, we propose a new framework, called Hyper-Decision Transformer (HDT), that can generalize to novel tasks from a handful of demonstrations in a data- and parameter-efficient manner. To achieve such a goal, we propose to augment the base DT with an adaptation module, whose parameters are initialized by a hyper-network. When encountering unseen tasks, the hyper-network takes a handful of demonstrations as inputs and initializes the adaptation module accordingly. This initialization enables HDT to efficiently adapt to novel tasks by only fine-tuning the adaptation module. We validate HDT's generalization capability on object manipulation tasks. We find that with a single expert demonstration and fine-tuning only 0.5% of DT parameters, HDT adapts faster to unseen tasks than fine-tuning the whole DT model. Finally, we explore a more challenging setting where expert actions are not available, and we show that HDT outperforms state-of-the-art baselines in terms of task success rates by a large margin.
Transfer Knowledge from Natural Language to Electrocardiography: Can We Detect Cardiovascular Disease Through Language Models?
Jan 21, 2023



Recent advancements in Large Language Models (LLMs) have drawn increasing attention since the learned embeddings pretrained on large-scale datasets have shown powerful ability in various downstream applications. However, whether the learned knowledge by LLMs can be transferred to clinical cardiology remains unknown. In this work, we aim to bridge this gap by transferring the knowledge of LLMs to clinical Electrocardiography (ECG). We propose an approach for cardiovascular disease diagnosis and automatic ECG diagnosis report generation. We also introduce an additional loss function by Optimal Transport (OT) to align the distribution between ECG and language embedding. The learned embeddings are evaluated on two downstream tasks: (1) automatic ECG diagnosis report generation, and (2) zero-shot cardiovascular disease detection. Our approach is able to generate high-quality cardiac diagnosis reports and also achieves competitive zero-shot classification performance even compared with supervised baselines, which proves the feasibility of transferring knowledge from LLMs to the cardiac domain.
Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation
Oct 18, 2022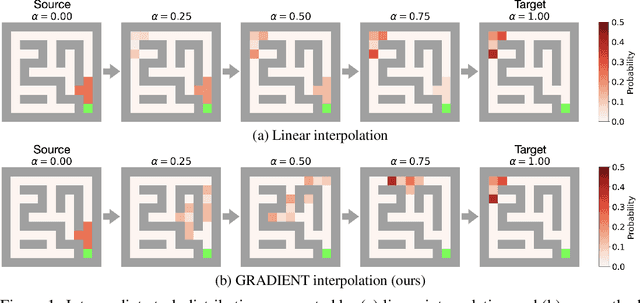


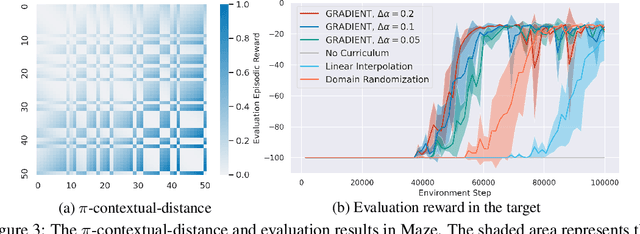
Curriculum Reinforcement Learning (CRL) aims to create a sequence of tasks, starting from easy ones and gradually learning towards difficult tasks. In this work, we focus on the idea of framing CRL as interpolations between a source (auxiliary) and a target task distribution. Although existing studies have shown the great potential of this idea, it remains unclear how to formally quantify and generate the movement between task distributions. Inspired by the insights from gradual domain adaptation in semi-supervised learning, we create a natural curriculum by breaking down the potentially large task distributional shift in CRL into smaller shifts. We propose GRADIENT, which formulates CRL as an optimal transport problem with a tailored distance metric between tasks. Specifically, we generate a sequence of task distributions as a geodesic interpolation (i.e., Wasserstein barycenter) between the source and target distributions. Different from many existing methods, our algorithm considers a task-dependent contextual distance metric and is capable of handling nonparametric distributions in both continuous and discrete context settings. In addition, we theoretically show that GRADIENT enables smooth transfer between subsequent stages in the curriculum under certain conditions. We conduct extensive experiments in locomotion and manipulation tasks and show that our proposed GRADIENT achieves higher performance than baselines in terms of learning efficiency and asymptotic performance.