 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Verification Can Be More Effective than Scaling Policy Learning for Vision-Language-Action Alignment
Feb 12, 2026The long-standing vision of general-purpose robots hinges on their ability to understand and act upon natural language instructions. Vision-Language-Action (VLA) models have made remarkable progress toward this goal, yet their generated actions can still misalign with the given instructions. In this paper, we investigate test-time verification as a means to shrink the "intention-action gap.'' We first characterize the test-time scaling law for embodied instruction following and demonstrate that jointly scaling the number of rephrased instructions and generated actions greatly increases test-time sample diversity, often recovering correct actions more efficiently than scaling each dimension independently. To capitalize on these scaling laws, we present CoVer, a contrastive verifier for vision-language-action alignment, and show that our architecture scales gracefully with additional computational resources and data. We then introduce "boot-time compute" and a hierarchical verification inference pipeline for VLAs. At deployment, our framework precomputes a diverse set of rephrased instructions from a Vision-Language-Model (VLM), repeatedly generates action candidates for each instruction, and then uses a verifier to select the optimal high-level prompt and low-level action chunks. Compared to scaling policy pre-training on the same data, our verification approach yields 22% gains in-distribution and 13% out-of-distribution on the SIMPLER benchmark, with a further 45% improvement in real-world experiments. On the PolaRiS benchmark, CoVer achieves 14% gains in task progress and 9% in success rate.
Dynamics as Prompts: In-Context Learning for Sim-to-Real System Identifications
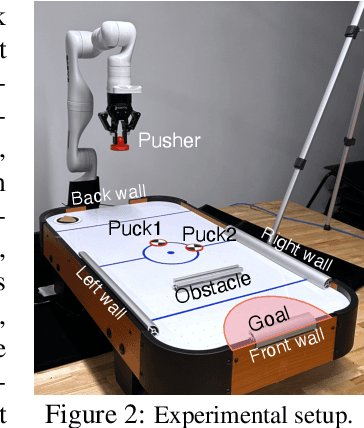
Oct 27, 2024Sim-to-real transfer remains a significant challenge in robotics due to the discrepancies between simulated and real-world dynamics. Traditional methods like Domain Randomization often fail to capture fine-grained dynamics, limiting their effectiveness for precise control tasks. In this work, we propose a novel approach that dynamically adjusts simulation environment parameters online using in-context learning. By leveraging past interaction histories as context, our method adapts the simulation environment dynamics to real-world dynamics without requiring gradient updates, resulting in faster and more accurate alignment between simulated and real-world performance. We validate our approach across two tasks: object scooping and table air hockey. In the sim-to-sim evaluations, our method significantly outperforms the baselines on environment parameter estimation by 80% and 42% in the object scooping and table air hockey setups, respectively. Furthermore, our method achieves at least 70% success rate in sim-to-real transfer on object scooping across three different objects. By incorporating historical interaction data, our approach delivers efficient and smooth system identification, advancing the deployment of robots in dynamic real-world scenarios. Demos are available on our project page: https://sim2real-capture.github.io/
Learning Robust Policies via Interpretable Hamilton-Jacobi Reachability-Guided Disturbances
Sep 29, 2024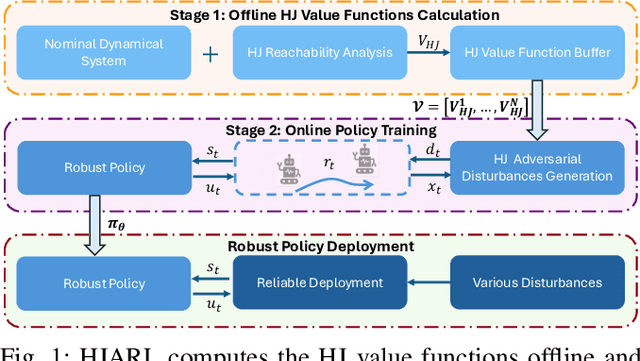
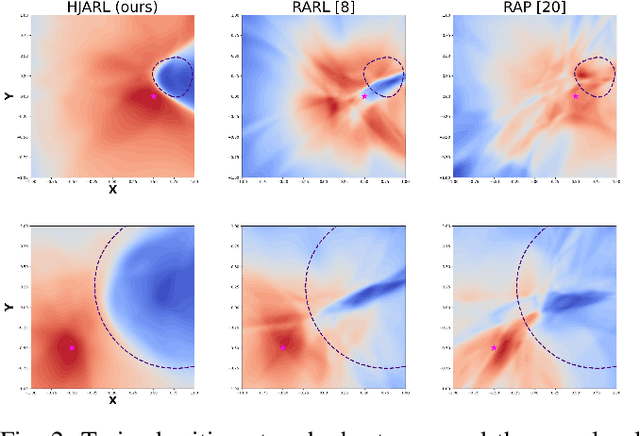
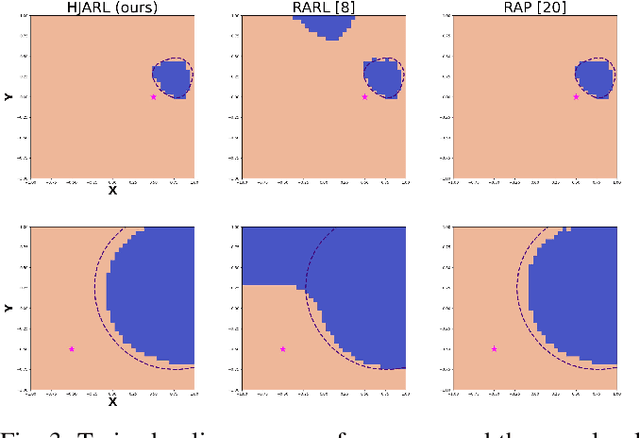

Deep Reinforcement Learning (RL) has shown remarkable success in robotics with complex and heterogeneous dynamics. However, its vulnerability to unknown disturbances and adversarial attacks remains a significant challenge. In this paper, we propose a robust policy training framework that integrates model-based control principles with adversarial RL training to improve robustness without the need for external black-box adversaries. Our approach introduces a novel Hamilton-Jacobi reachability-guided disturbance for adversarial RL training, where we use interpretable worst-case or near-worst-case disturbances as adversaries against the robust policy. We evaluated its effectiveness across three distinct tasks: a reach-avoid game in both simulation and real-world settings, and a highly dynamic quadrotor stabilization task in simulation. We validate that our learned critic network is consistent with the ground-truth HJ value function, while the policy network shows comparable performance with other learning-based methods.
Creative Robot Tool Use with Large Language Models
Oct 19, 2023



Tool use is a hallmark of advanced intelligence, exemplified in both animal behavior and robotic capabilities. This paper investigates the feasibility of imbuing robots with the ability to creatively use tools in tasks that involve implicit physical constraints and long-term planning. Leveraging Large Language Models (LLMs), we develop RoboTool, a system that accepts natural language instructions and outputs executable code for controlling robots in both simulated and real-world environments. RoboTool incorporates four pivotal components: (i) an "Analyzer" that interprets natural language to discern key task-related concepts, (ii) a "Planner" that generates comprehensive strategies based on the language input and key concepts, (iii) a "Calculator" that computes parameters for each skill, and (iv) a "Coder" that translates these plans into executable Python code. Our results show that RoboTool can not only comprehend explicit or implicit physical constraints and environmental factors but also demonstrate creative tool use. Unlike traditional Task and Motion Planning (TAMP) methods that rely on explicit optimization, our LLM-based system offers a more flexible, efficient, and user-friendly solution for complex robotics tasks. Through extensive experiments, we validate that RoboTool is proficient in handling tasks that would otherwise be infeasible without the creative use of tools, thereby expanding the capabilities of robotic systems. Demos are available on our project page: https://creative-robotool.github.io/.
What Went Wrong? Closing the Sim-to-Real Gap via Differentiable Causal Discovery
Jun 28, 2023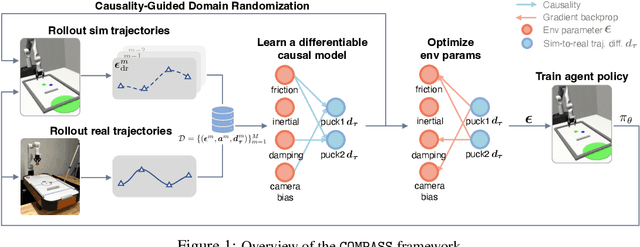


Training control policies in simulation is more appealing than on real robots directly, as it allows for exploring diverse states in a safe and efficient manner. Yet, robot simulators inevitably exhibit disparities from the real world, yielding inaccuracies that manifest as the simulation-to-real gap. Existing literature has proposed to close this gap by actively modifying specific simulator parameters to align the simulated data with real-world observations. However, the set of tunable parameters is usually manually selected to reduce the search space in a case-by-case manner, which is hard to scale up for complex systems and requires extensive domain knowledge. To address the scalability issue and automate the parameter-tuning process, we introduce an approach that aligns the simulator with the real world by discovering the causal relationship between the environment parameters and the sim-to-real gap. Concretely, our method learns a differentiable mapping from the environment parameters to the differences between simulated and real-world robot-object trajectories. This mapping is governed by a simultaneously-learned causal graph to help prune the search space of parameters, provide better interpretability, and improve generalization. We perform experiments to achieve both sim-to-sim and sim-to-real transfer, and show that our method has significant improvements in trajectory alignment and task success rate over strong baselines in a challenging manipulation task.