 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
May 16, 2025Imitation learning for manipulation has a well-known data scarcity problem. Unlike natural language and 2D computer vision, there is no Internet-scale corpus of data for dexterous manipulation. One appealing option is egocentric human video, a passively scalable data source. However, existing large-scale datasets such as Ego4D do not have native hand pose annotations and do not focus on object manipulation. To this end, we use Apple Vision Pro to collect EgoDex: the largest and most diverse dataset of dexterous human manipulation to date. EgoDex has 829 hours of egocentric video with paired 3D hand and finger tracking data collected at the time of recording, where multiple calibrated cameras and on-device SLAM can be used to precisely track the pose of every joint of each hand. The dataset covers a wide range of diverse manipulation behaviors with everyday household objects in 194 different tabletop tasks ranging from tying shoelaces to folding laundry. Furthermore, we train and systematically evaluate imitation learning policies for hand trajectory prediction on the dataset, introducing metrics and benchmarks for measuring progress in this increasingly important area. By releasing this large-scale dataset, we hope to push the frontier of robotics, computer vision, and foundation models.
EMOTION: Expressive Motion Sequence Generation for Humanoid Robots with In-Context Learning
Oct 30, 2024



This paper introduces a framework, called EMOTION, for generating expressive motion sequences in humanoid robots, enhancing their ability to engage in humanlike non-verbal communication. Non-verbal cues such as facial expressions, gestures, and body movements play a crucial role in effective interpersonal interactions. Despite the advancements in robotic behaviors, existing methods often fall short in mimicking the diversity and subtlety of human non-verbal communication. To address this gap, our approach leverages the in-context learning capability of large language models (LLMs) to dynamically generate socially appropriate gesture motion sequences for human-robot interaction. We use this framework to generate 10 different expressive gestures and conduct online user studies comparing the naturalness and understandability of the motions generated by EMOTION and its human-feedback version, EMOTION++, against those by human operators. The results demonstrate that our approach either matches or surpasses human performance in generating understandable and natural robot motions under certain scenarios. We also provide design implications for future research to consider a set of variables when generating expressive robotic gestures.
Dynamics as Prompts: In-Context Learning for Sim-to-Real System Identifications
Oct 27, 2024Sim-to-real transfer remains a significant challenge in robotics due to the discrepancies between simulated and real-world dynamics. Traditional methods like Domain Randomization often fail to capture fine-grained dynamics, limiting their effectiveness for precise control tasks. In this work, we propose a novel approach that dynamically adjusts simulation environment parameters online using in-context learning. By leveraging past interaction histories as context, our method adapts the simulation environment dynamics to real-world dynamics without requiring gradient updates, resulting in faster and more accurate alignment between simulated and real-world performance. We validate our approach across two tasks: object scooping and table air hockey. In the sim-to-sim evaluations, our method significantly outperforms the baselines on environment parameter estimation by 80% and 42% in the object scooping and table air hockey setups, respectively. Furthermore, our method achieves at least 70% success rate in sim-to-real transfer on object scooping across three different objects. By incorporating historical interaction data, our approach delivers efficient and smooth system identification, advancing the deployment of robots in dynamic real-world scenarios. Demos are available on our project page: https://sim2real-capture.github.io/
CaDRE: Controllable and Diverse Generation of Safety-Critical Driving Scenarios using Real-World Trajectories
Mar 19, 2024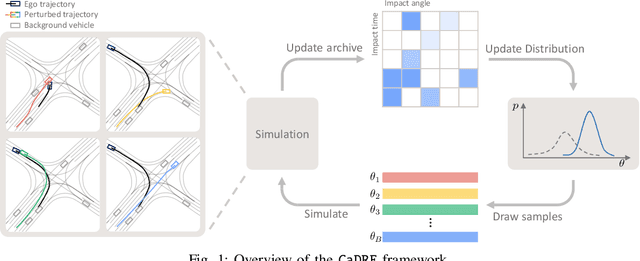
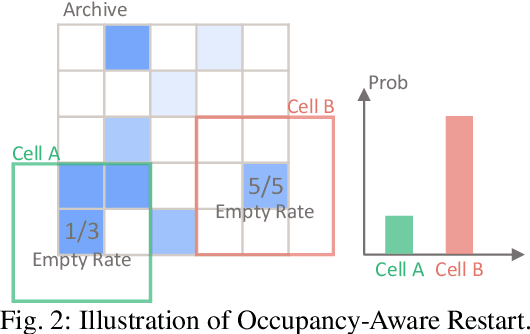
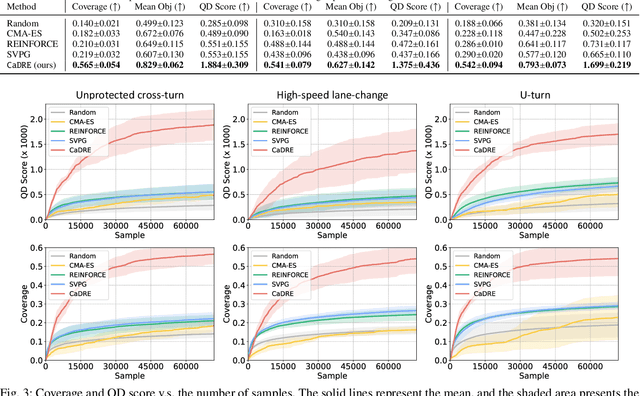
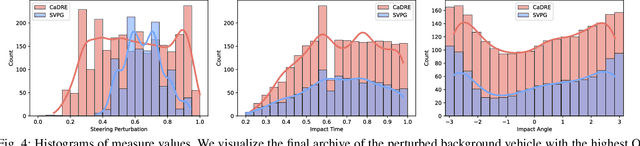
Simulation is an indispensable tool in the development and testing of autonomous vehicles (AVs), offering an efficient and safe alternative to road testing by allowing the exploration of a wide range of scenarios. Despite its advantages, a significant challenge within simulation-based testing is the generation of safety-critical scenarios, which are essential to ensure that AVs can handle rare but potentially fatal situations. This paper addresses this challenge by introducing a novel generative framework, CaDRE, which is specifically designed for generating diverse and controllable safety-critical scenarios using real-world trajectories. Our approach optimizes for both the quality and diversity of scenarios by employing a unique formulation and algorithm that integrates real-world data, domain knowledge, and black-box optimization techniques. We validate the effectiveness of our framework through extensive testing in three representative types of traffic scenarios. The results demonstrate superior performance in generating diverse and high-quality scenarios with greater sample efficiency than existing reinforcement learning and sampling-based methods.
Gradient Shaping for Multi-Constraint Safe Reinforcement Learning
Dec 23, 2023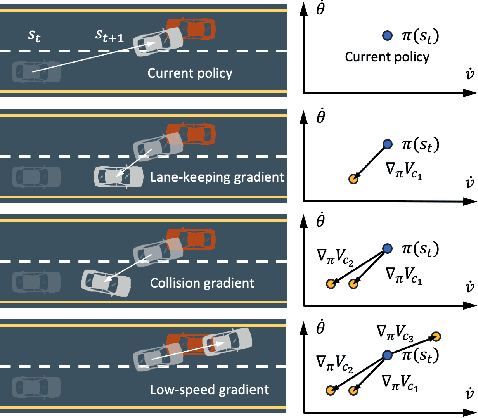
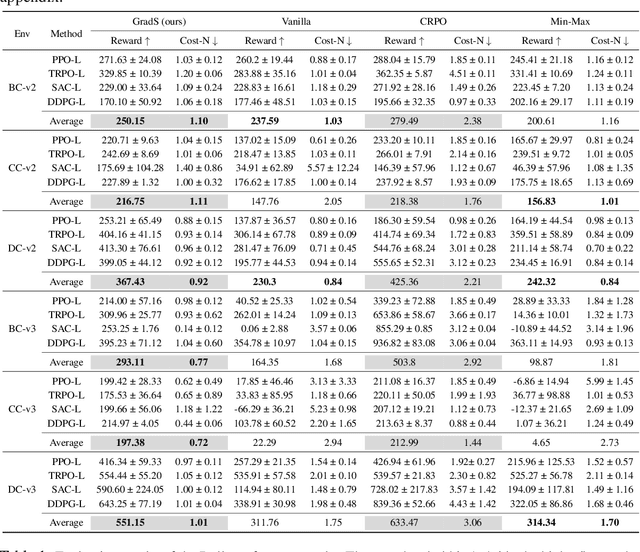
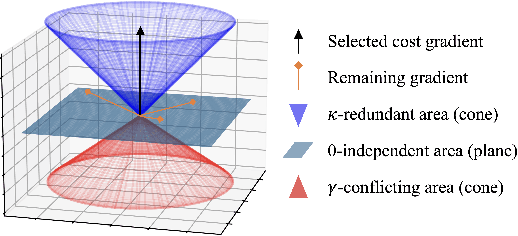
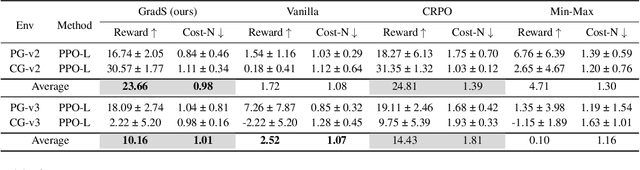
Online safe reinforcement learning (RL) involves training a policy that maximizes task efficiency while satisfying constraints via interacting with the environments. In this paper, our focus lies in addressing the complex challenges associated with solving multi-constraint (MC) safe RL problems. We approach the safe RL problem from the perspective of Multi-Objective Optimization (MOO) and propose a unified framework designed for MC safe RL algorithms. This framework highlights the manipulation of gradients derived from constraints. Leveraging insights from this framework and recognizing the significance of \textit{redundant} and \textit{conflicting} constraint conditions, we introduce the Gradient Shaping (GradS) method for general Lagrangian-based safe RL algorithms to improve the training efficiency in terms of both reward and constraint satisfaction. Our extensive experimentation demonstrates the effectiveness of our proposed method in encouraging exploration and learning a policy that improves both safety and reward performance across various challenging MC safe RL tasks as well as good scalability to the number of constraints.
Creative Robot Tool Use with Large Language Models
Oct 19, 2023



Tool use is a hallmark of advanced intelligence, exemplified in both animal behavior and robotic capabilities. This paper investigates the feasibility of imbuing robots with the ability to creatively use tools in tasks that involve implicit physical constraints and long-term planning. Leveraging Large Language Models (LLMs), we develop RoboTool, a system that accepts natural language instructions and outputs executable code for controlling robots in both simulated and real-world environments. RoboTool incorporates four pivotal components: (i) an "Analyzer" that interprets natural language to discern key task-related concepts, (ii) a "Planner" that generates comprehensive strategies based on the language input and key concepts, (iii) a "Calculator" that computes parameters for each skill, and (iv) a "Coder" that translates these plans into executable Python code. Our results show that RoboTool can not only comprehend explicit or implicit physical constraints and environmental factors but also demonstrate creative tool use. Unlike traditional Task and Motion Planning (TAMP) methods that rely on explicit optimization, our LLM-based system offers a more flexible, efficient, and user-friendly solution for complex robotics tasks. Through extensive experiments, we validate that RoboTool is proficient in handling tasks that would otherwise be infeasible without the creative use of tools, thereby expanding the capabilities of robotic systems. Demos are available on our project page: https://creative-robotool.github.io/.
What Went Wrong? Closing the Sim-to-Real Gap via Differentiable Causal Discovery
Jun 28, 2023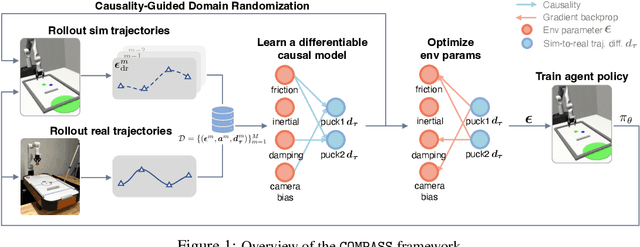

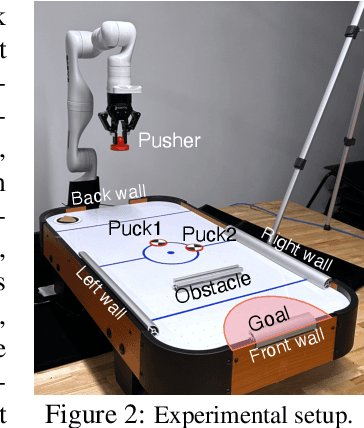

Training control policies in simulation is more appealing than on real robots directly, as it allows for exploring diverse states in a safe and efficient manner. Yet, robot simulators inevitably exhibit disparities from the real world, yielding inaccuracies that manifest as the simulation-to-real gap. Existing literature has proposed to close this gap by actively modifying specific simulator parameters to align the simulated data with real-world observations. However, the set of tunable parameters is usually manually selected to reduce the search space in a case-by-case manner, which is hard to scale up for complex systems and requires extensive domain knowledge. To address the scalability issue and automate the parameter-tuning process, we introduce an approach that aligns the simulator with the real world by discovering the causal relationship between the environment parameters and the sim-to-real gap. Concretely, our method learns a differentiable mapping from the environment parameters to the differences between simulated and real-world robot-object trajectories. This mapping is governed by a simultaneously-learned causal graph to help prune the search space of parameters, provide better interpretability, and improve generalization. We perform experiments to achieve both sim-to-sim and sim-to-real transfer, and show that our method has significant improvements in trajectory alignment and task success rate over strong baselines in a challenging manipulation task.
Multimodal Representation Learning of Cardiovascular Magnetic Resonance Imaging
Apr 16, 2023Self-supervised learning is crucial for clinical imaging applications, given the lack of explicit labels in healthcare. However, conventional approaches that rely on precise vision-language alignment are not always feasible in complex clinical imaging modalities, such as cardiac magnetic resonance (CMR). CMR provides a comprehensive visualization of cardiac anatomy, physiology, and microstructure, making it challenging to interpret. Additionally, CMR reports require synthesizing information from sequences of images and different views, resulting in potentially weak alignment between the study and diagnosis report pair. To overcome these challenges, we propose \textbf{CMRformer}, a multimodal learning framework to jointly learn sequences of CMR images and associated cardiologist's reports. Moreover, one of the major obstacles to improving CMR study is the lack of large, publicly available datasets. To bridge this gap, we collected a large \textbf{CMR dataset}, which consists of 13,787 studies from clinical cases. By utilizing our proposed CMRformer and our collected dataset, we achieved remarkable performance in real-world clinical tasks, such as CMR image retrieval and diagnosis report retrieval. Furthermore, the learned representations are evaluated to be practically helpful for downstream applications, such as disease classification. Our work could potentially expedite progress in the CMR study and lead to more accurate and effective diagnosis and treatment.
Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation
Oct 18, 2022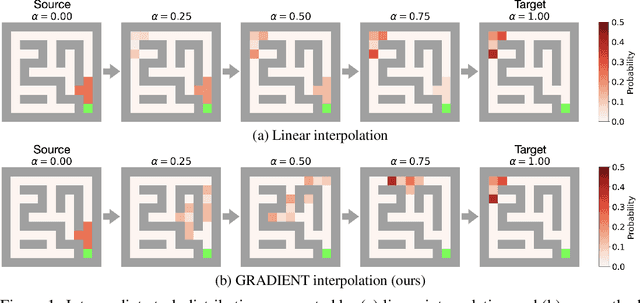


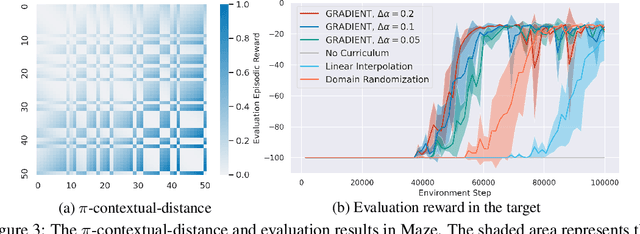
Curriculum Reinforcement Learning (CRL) aims to create a sequence of tasks, starting from easy ones and gradually learning towards difficult tasks. In this work, we focus on the idea of framing CRL as interpolations between a source (auxiliary) and a target task distribution. Although existing studies have shown the great potential of this idea, it remains unclear how to formally quantify and generate the movement between task distributions. Inspired by the insights from gradual domain adaptation in semi-supervised learning, we create a natural curriculum by breaking down the potentially large task distributional shift in CRL into smaller shifts. We propose GRADIENT, which formulates CRL as an optimal transport problem with a tailored distance metric between tasks. Specifically, we generate a sequence of task distributions as a geodesic interpolation (i.e., Wasserstein barycenter) between the source and target distributions. Different from many existing methods, our algorithm considers a task-dependent contextual distance metric and is capable of handling nonparametric distributions in both continuous and discrete context settings. In addition, we theoretically show that GRADIENT enables smooth transfer between subsequent stages in the curriculum under certain conditions. We conduct extensive experiments in locomotion and manipulation tasks and show that our proposed GRADIENT achieves higher performance than baselines in terms of learning efficiency and asymptotic performance.
Trustworthy Reinforcement Learning Against Intrinsic Vulnerabilities: Robustness, Safety, and Generalizability
Sep 16, 2022


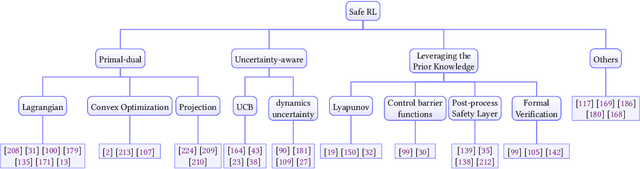
A trustworthy reinforcement learning algorithm should be competent in solving challenging real-world problems, including {robustly} handling uncertainties, satisfying {safety} constraints to avoid catastrophic failures, and {generalizing} to unseen scenarios during deployments. This study aims to overview these main perspectives of trustworthy reinforcement learning considering its intrinsic vulnerabilities on robustness, safety, and generalizability. In particular, we give rigorous formulations, categorize corresponding methodologies, and discuss benchmarks for each perspective. Moreover, we provide an outlook section to spur promising future directions with a brief discussion on extrinsic vulnerabilities considering human feedback. We hope this survey could bring together separate threads of studies together in a unified framework and promote the trustworthiness of reinforcement learning.