 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Shaping for Multi-Constraint Safe Reinforcement Learning
Paper and Code
Dec 23, 2023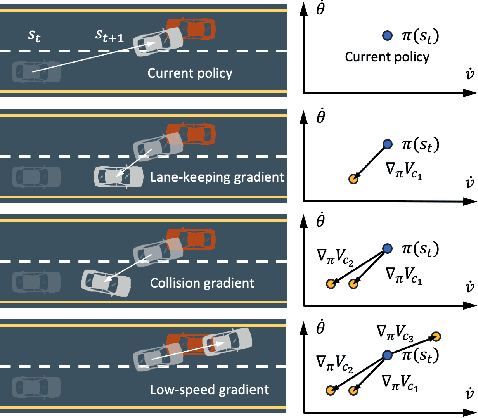
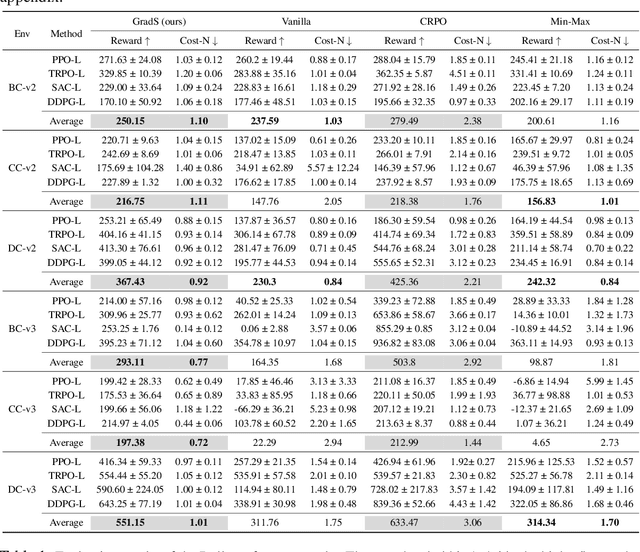
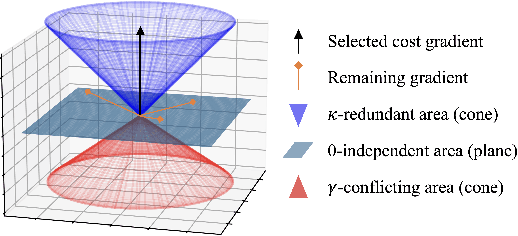
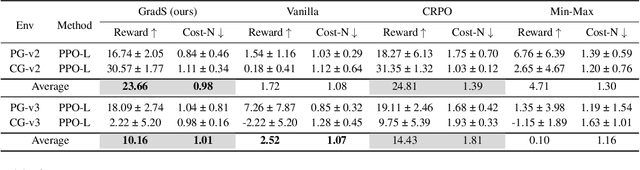
Online safe reinforcement learning (RL) involves training a policy that maximizes task efficiency while satisfying constraints via interacting with the environments. In this paper, our focus lies in addressing the complex challenges associated with solving multi-constraint (MC) safe RL problems. We approach the safe RL problem from the perspective of Multi-Objective Optimization (MOO) and propose a unified framework designed for MC safe RL algorithms. This framework highlights the manipulation of gradients derived from constraints. Leveraging insights from this framework and recognizing the significance of \textit{redundant} and \textit{conflicting} constraint conditions, we introduce the Gradient Shaping (GradS) method for general Lagrangian-based safe RL algorithms to improve the training efficiency in terms of both reward and constraint satisfaction. Our extensive experimentation demonstrates the effectiveness of our proposed method in encouraging exploration and learning a policy that improves both safety and reward performance across various challenging MC safe RL tasks as well as good scalability to the number of constraints.