 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Perception and Action: Spatially-Grounded Mid-Level Representations for Robot Generalization
Jun 06, 2025In this work, we investigate how spatially grounded auxiliary representations can provide both broad, high-level grounding as well as direct, actionable information to improve policy learning performance and generalization for dexterous tasks. We study these mid-level representations across three critical dimensions: object-centricity, pose-awareness, and depth-awareness. We use these interpretable mid-level representations to train specialist encoders via supervised learning, then feed them as inputs to a diffusion policy to solve dexterous bimanual manipulation tasks in the real world. We propose a novel mixture-of-experts policy architecture that combines multiple specialized expert models, each trained on a distinct mid-level representation, to improve policy generalization. This method achieves an average success rate that is 11% higher than a language-grounded baseline and 24 percent higher than a standard diffusion policy baseline on our evaluation tasks. Furthermore, we find that leveraging mid-level representations as supervision signals for policy actions within a weighted imitation learning algorithm improves the precision with which the policy follows these representations, yielding an additional performance increase of 10%. Our findings highlight the importance of grounding robot policies not only with broad perceptual tasks but also with more granular, actionable representations. For further information and videos, please visit https://mid-level-moe.github.io.
LocoTouch: Learning Dexterous Quadrupedal Transport with Tactile Sensing
May 29, 2025Quadrupedal robots have demonstrated remarkable agility and robustness in traversing complex terrains. However, they remain limited in performing object interactions that require sustained contact. In this work, we present LocoTouch, a system that equips quadrupedal robots with tactile sensing to address a challenging task in this category: long-distance transport of unsecured cylindrical objects, which typically requires custom mounting mechanisms to maintain stability. For efficient large-area tactile sensing, we design a high-density distributed tactile sensor array that covers the entire back of the robot. To effectively leverage tactile feedback for locomotion control, we develop a simulation environment with high-fidelity tactile signals, and train tactile-aware transport policies using a two-stage learning pipeline. Furthermore, we design a novel reward function to promote stable, symmetric, and frequency-adaptive locomotion gaits. After training in simulation, LocoTouch transfers zero-shot to the real world, reliably balancing and transporting a wide range of unsecured, cylindrical everyday objects with broadly varying sizes and weights. Thanks to the responsiveness of the tactile sensor and the adaptive gait reward, LocoTouch can robustly balance objects with slippery surfaces over long distances, or even under severe external perturbations.
Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models
Apr 17, 2025Learning to perform manipulation tasks from human videos is a promising approach for teaching robots. However, many manipulation tasks require changing control parameters during task execution, such as force, which visual data alone cannot capture. In this work, we leverage sensing devices such as armbands that measure human muscle activities and microphones that record sound, to capture the details in the human manipulation process, and enable robots to extract task plans and control parameters to perform the same task. To achieve this, we introduce Chain-of-Modality (CoM), a prompting strategy that enables Vision Language Models to reason about multimodal human demonstration data -- videos coupled with muscle or audio signals. By progressively integrating information from each modality, CoM refines a task plan and generates detailed control parameters, enabling robots to perform manipulation tasks based on a single multimodal human video prompt. Our experiments show that CoM delivers a threefold improvement in accuracy for extracting task plans and control parameters compared to baselines, with strong generalization to new task setups and objects in real-world robot experiments. Videos and code are available at https://chain-of-modality.github.io
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
QuietPaw: Learning Quadrupedal Locomotion with Versatile Noise Preference Alignment
Mar 06, 2025When operating at their full capacity, quadrupedal robots can produce loud footstep noise, which can be disruptive in human-centered environments like homes, offices, and hospitals. As a result, balancing locomotion performance with noise constraints is crucial for the successful real-world deployment of quadrupedal robots. However, achieving adaptive noise control is challenging due to (a) the trade-off between agility and noise minimization, (b) the need for generalization across diverse deployment conditions, and (c) the difficulty of effectively adjusting policies based on noise requirements. We propose QuietPaw, a framework incorporating our Conditional Noise-Constrained Policy (CNCP), a constrained learning-based algorithm that enables flexible, noise-aware locomotion by conditioning policy behavior on noise-reduction levels. We leverage value representation decomposition in the critics, disentangling state representations from condition-dependent representations and this allows a single versatile policy to generalize across noise levels without retraining while improving the Pareto trade-off between agility and noise reduction. We validate our approach in simulation and the real world, demonstrating that CNCP can effectively balance locomotion performance and noise constraints, achieving continuously adjustable noise reduction.
Versatile Locomotion Skills for Hexapod Robots
Dec 14, 2024



Hexapod robots are potentially suitable for carrying out tasks in cluttered environments since they are stable, compact, and light weight. They also have multi-joint legs and variable height bodies that make them good candidates for tasks such as stairs climbing and squeezing under objects in a typical home environment or an attic. Expanding on our previous work on joist climbing in attics, we train a legged hexapod equipped with a depth camera and visual inertial odometry (VIO) to perform three tasks: climbing stairs, avoiding obstacles, and squeezing under obstacles such as a table. Our policies are trained with simulation data only and can be deployed on lowcost hardware not requiring real-time joint state feedback. We train our model in a teacher-student model with 2 phases: In phase 1, we use reinforcement learning with access to privileged information such as height maps and joint feedback. In phase 2, we use supervised learning to distill the model into one with access to only onboard observations, consisting of egocentric depth images and robot pose captured by a tracking VIO camera. By manipulating available privileged information, constructing simulation terrains, and refining reward functions during phase 1 training, we are able to train the robots with skills that are robust in non-ideal physical environments. We demonstrate successful sim-to-real transfer and achieve high success rates across all three tasks in physical experiments.
Learning Multi-Agent Loco-Manipulation for Long-Horizon Quadrupedal Pushing
Nov 14, 2024Recently, quadrupedal locomotion has achieved significant success, but their manipulation capabilities, particularly in handling large objects, remain limited, restricting their usefulness in demanding real-world applications such as search and rescue, construction, industrial automation, and room organization. This paper tackles the task of obstacle-aware, long-horizon pushing by multiple quadrupedal robots. We propose a hierarchical multi-agent reinforcement learning framework with three levels of control. The high-level controller integrates an RRT planner and a centralized adaptive policy to generate subgoals, while the mid-level controller uses a decentralized goal-conditioned policy to guide the robots toward these sub-goals. A pre-trained low-level locomotion policy executes the movement commands. We evaluate our method against several baselines in simulation, demonstrating significant improvements over baseline approaches, with 36.0% higher success rates and 24.5% reduction in completion time than the best baseline. Our framework successfully enables long-horizon, obstacle-aware manipulation tasks like Push-Cuboid and Push-T on Go1 robots in the real world.
Vision Language Models are In-Context Value Learners
Nov 07, 2024
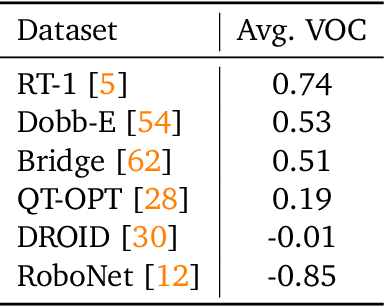
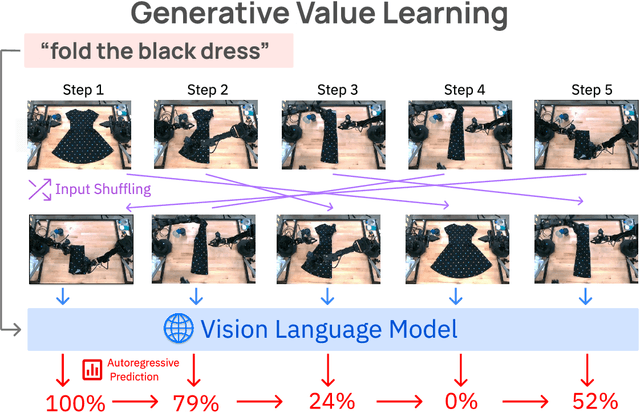
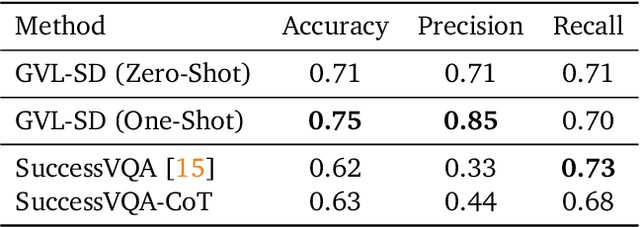
Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
IPPON: Common Sense Guided Informative Path Planning for Object Goal Navigation
Oct 25, 2024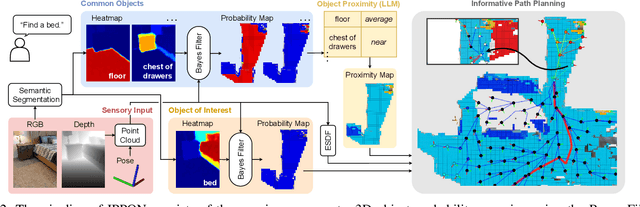
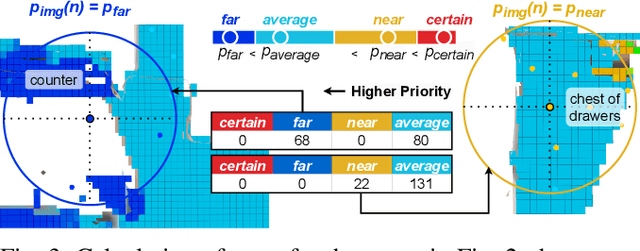
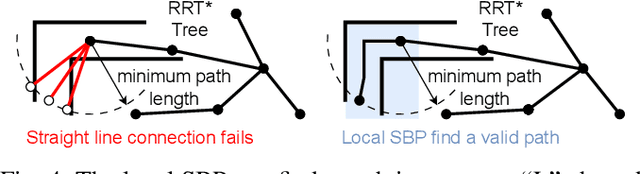
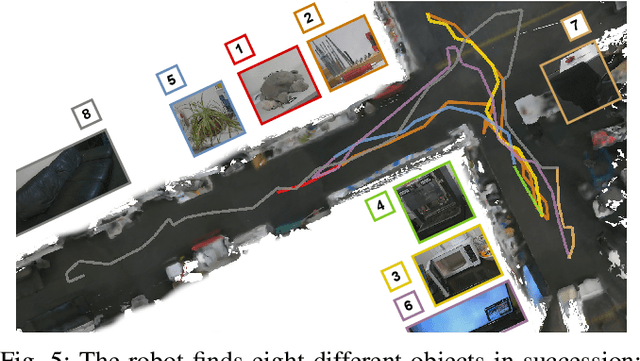
Navigating efficiently to an object in an unexplored environment is a critical skill for general-purpose intelligent robots. Recent approaches to this object goal navigation problem have embraced a modular strategy, integrating classical exploration algorithms-notably frontier exploration-with a learned semantic mapping/exploration module. This paper introduces a novel informative path planning and 3D object probability mapping approach. The mapping module computes the probability of the object of interest through semantic segmentation and a Bayes filter. Additionally, it stores probabilities for common objects, which semantically guides the exploration based on common sense priors from a large language model. The planner terminates when the current viewpoint captures enough voxels identified with high confidence as the object of interest. Although our planner follows a zero-shot approach, it achieves state-of-the-art performance as measured by the Success weighted by Path Length (SPL) and Soft SPL in the Habitat ObjectNav Challenge 2023, outperforming other works by more than 20%. Furthermore, we validate its effectiveness on real robots. Project webpage: https://ippon-paper.github.io/
Agile Continuous Jumping in Discontinuous Terrains
Sep 17, 2024



We focus on agile, continuous, and terrain-adaptive jumping of quadrupedal robots in discontinuous terrains such as stairs and stepping stones. Unlike single-step jumping, continuous jumping requires accurately executing highly dynamic motions over long horizons, which is challenging for existing approaches. To accomplish this task, we design a hierarchical learning and control framework, which consists of a learned heightmap predictor for robust terrain perception, a reinforcement-learning-based centroidal-level motion policy for versatile and terrain-adaptive planning, and a low-level model-based leg controller for accurate motion tracking. In addition, we minimize the sim-to-real gap by accurately modeling the hardware characteristics. Our framework enables a Unitree Go1 robot to perform agile and continuous jumps on human-sized stairs and sparse stepping stones, for the first time to the best of our knowledge. In particular, the robot can cross two stair steps in each jump and completes a 3.5m long, 2.8m high, 14-step staircase in 4.5 seconds. Moreover, the same policy outperforms baselines in various other parkour tasks, such as jumping over single horizontal or vertical discontinuities. Experiment videos can be found at \url{https://yxyang.github.io/jumping\_cod/}.