 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForesight: Iterative Reasoning About Clues that Matter for Navigation
Jun 10, 2026Open-world mapless navigation from sparse language instructions requires resolving underspecified goals and inferring which environmental cues are relevant for reaching the goal. For instance, reaching an out-of-view destination may require interpreting ramps, signs, or detours that reveal where to go or which route to take. Prior works are limited by their reliance on known navigation factors and closed-set factor categories, or identify cues before motion planning and miss plan-dependent cues. We argue that pretrained Vision-Language Models (VLMs) can discover novel instruction-relevant cues, but require adaptation to focus on which cues matter and how they should influence motion planning. We realize these ideas in Foresight, a test-time framework in which a finetuned VLM alternates between proposing image-space motion plans and critiquing them using the language goal and visual context. Subsequent plans are conditioned on prior critiques, enabling iterative motion refinement before execution. To align plan critiques and refinements with open-set behavior preferences, we learn a reward model from human feedback and use it to post-train the VLM with reinforcement learning in the plan-critique loop. In offline evaluations and 6 real-world environments, Foresight improves average task success by 37% and reduces interventions per mission by 52% relative to state-of-the-art test-time reasoning and foundation-model baselines, while running in real-time on a Jetson AGX Orin. We will release code, data, and training details to support future work on test-time reasoning for robot motion refinement. Additional videos at: https://amrl.cs.utexas.edu/foresight
ELLIPSE: Evidential Learning for Robust Waypoints and Uncertainties
Mar 04, 2026Robust waypoint prediction is crucial for mobile robots operating in open-world, safety-critical settings. While Imitation Learning (IL) methods have demonstrated great success in practice, they are susceptible to distribution shifts: the policy can become dangerously overconfident in unfamiliar states. In this paper, we present \textit{ELLIPSE}, a method building on multivariate deep evidential regression to output waypoints and multivariate Student-t predictive distributions in a single forward pass. To reduce covariate-shift-induced overconfidence under viewpoint and pose perturbations near expert trajectories, we introduce a lightweight domain augmentation procedure that synthesizes plausible viewpoint/pose variations without collecting additional demonstrations. To improve uncertainty reliability under environment/domain shift (e.g., unseen staircases), we apply a post-hoc isotonic recalibration on probability integral transform (PIT) values so that prediction sets remain plausible during deployment. We ground the discussion and experiments in staircase waypoint prediction, where obtaining robust waypoint and uncertainty is pivotal. Extensive real world evaluations show that \textit{ELLIPSE} improves both task success rate and uncertainty coverage compared to baselines.
VENTURA: Adapting Image Diffusion Models for Unified Task Conditioned Navigation
Oct 01, 2025Robots must adapt to diverse human instructions and operate safely in unstructured, open-world environments. Recent Vision-Language models (VLMs) offer strong priors for grounding language and perception, but remain difficult to steer for navigation due to differences in action spaces and pretraining objectives that hamper transferability to robotics tasks. Towards addressing this, we introduce VENTURA, a vision-language navigation system that finetunes internet-pretrained image diffusion models for path planning. Instead of directly predicting low-level actions, VENTURA generates a path mask (i.e. a visual plan) in image space that captures fine-grained, context-aware navigation behaviors. A lightweight behavior-cloning policy grounds these visual plans into executable trajectories, yielding an interface that follows natural language instructions to generate diverse robot behaviors. To scale training, we supervise on path masks derived from self-supervised tracking models paired with VLM-augmented captions, avoiding manual pixel-level annotation or highly engineered data collection setups. In extensive real-world evaluations, VENTURA outperforms state-of-the-art foundation model baselines on object reaching, obstacle avoidance, and terrain preference tasks, improving success rates by 33% and reducing collisions by 54% across both seen and unseen scenarios. Notably, we find that VENTURA generalizes to unseen combinations of distinct tasks, revealing emergent compositional capabilities. Videos, code, and additional materials: https://venturapath.github.io
Aim My Robot: Precision Local Navigation to Any Object
Nov 22, 2024Existing navigation systems mostly consider "success" when the robot reaches within 1m radius to a goal. This precision is insufficient for emerging applications where the robot needs to be positioned precisely relative to an object for downstream tasks, such as docking, inspection, and manipulation. To this end, we design and implement Aim-My-Robot (AMR), a local navigation system that enables a robot to reach any object in its vicinity at the desired relative pose, with centimeter-level precision. AMR achieves high precision and robustness by leveraging multi-modal perception, precise action prediction, and is trained on large-scale photorealistic data generated in simulation. AMR shows strong sim2real transfer and can adapt to different robot kinematics and unseen objects with little to no fine-tuning.
Agile Continuous Jumping in Discontinuous Terrains
Sep 17, 2024



We focus on agile, continuous, and terrain-adaptive jumping of quadrupedal robots in discontinuous terrains such as stairs and stepping stones. Unlike single-step jumping, continuous jumping requires accurately executing highly dynamic motions over long horizons, which is challenging for existing approaches. To accomplish this task, we design a hierarchical learning and control framework, which consists of a learned heightmap predictor for robust terrain perception, a reinforcement-learning-based centroidal-level motion policy for versatile and terrain-adaptive planning, and a low-level model-based leg controller for accurate motion tracking. In addition, we minimize the sim-to-real gap by accurately modeling the hardware characteristics. Our framework enables a Unitree Go1 robot to perform agile and continuous jumps on human-sized stairs and sparse stepping stones, for the first time to the best of our knowledge. In particular, the robot can cross two stair steps in each jump and completes a 3.5m long, 2.8m high, 14-step staircase in 4.5 seconds. Moreover, the same policy outperforms baselines in various other parkour tasks, such as jumping over single horizontal or vertical discontinuities. Experiment videos can be found at \url{https://yxyang.github.io/jumping\_cod/}.
V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Navigation
Dec 26, 2023



Reliable estimation of terrain traversability is critical for the successful deployment of autonomous systems in wild, outdoor environments. Given the lack of large-scale annotated datasets for off-road navigation, strictly-supervised learning approaches remain limited in their generalization ability. To this end, we introduce a novel, image-based self-supervised learning method for traversability prediction, leveraging a state-of-the-art vision foundation model for improved out-of-distribution performance. Our method employs contrastive representation learning using both human driving data and instance-based segmentation masks during training. We show that this simple, yet effective, technique drastically outperforms recent methods in predicting traversability for both on- and off-trail driving scenarios. We compare our method with recent baselines on both a common benchmark as well as our own datasets, covering a diverse range of outdoor environments and varied terrain types. We also demonstrate the compatibility of resulting costmap predictions with a model-predictive controller. Finally, we evaluate our approach on zero- and few-shot tasks, demonstrating unprecedented performance for generalization to new environments. Videos and additional material can be found here: \url{https://sites.google.com/view/visual-traversability-learning}.
LiDAR-UDA: Self-ensembling Through Time for Unsupervised LiDAR Domain Adaptation
Sep 24, 2023We introduce LiDAR-UDA, a novel two-stage self-training-based Unsupervised Domain Adaptation (UDA) method for LiDAR segmentation. Existing self-training methods use a model trained on labeled source data to generate pseudo labels for target data and refine the predictions via fine-tuning the network on the pseudo labels. These methods suffer from domain shifts caused by different LiDAR sensor configurations in the source and target domains. We propose two techniques to reduce sensor discrepancy and improve pseudo label quality: 1) LiDAR beam subsampling, which simulates different LiDAR scanning patterns by randomly dropping beams; 2) cross-frame ensembling, which exploits temporal consistency of consecutive frames to generate more reliable pseudo labels. Our method is simple, generalizable, and does not incur any extra inference cost. We evaluate our method on several public LiDAR datasets and show that it outperforms the state-of-the-art methods by more than $3.9\%$ mIoU on average for all scenarios. Code will be available at https://github.com/JHLee0513/LiDARUDA.
CAJun: Continuous Adaptive Jumping using a Learned Centroidal Controller
Jun 16, 2023We present CAJun, a novel hierarchical learning and control framework that enables legged robots to jump continuously with adaptive jumping distances. CAJun consists of a high-level centroidal policy and a low-level leg controller. In particular, we use reinforcement learning (RL) to train the centroidal policy, which specifies the gait timing, base velocity, and swing foot position for the leg controller. The leg controller optimizes motor commands for the swing and stance legs according to the gait timing to track the swing foot target and base velocity commands using optimal control. Additionally, we reformulate the stance leg optimizer in the leg controller to speed up policy training by an order of magnitude. Our system combines the versatility of learning with the robustness of optimal control. By combining RL with optimal control methods, our system achieves the versatility of learning while enjoys the robustness from control methods, making it easily transferable to real robots. We show that after 20 minutes of training on a single GPU, CAJun can achieve continuous, long jumps with adaptive distances on a Go1 robot with small sim-to-real gaps. Moreover, the robot can jump across gaps with a maximum width of 70cm, which is over 40% wider than existing methods.
Continuous Versatile Jumping Using Learned Action Residuals
Apr 17, 2023

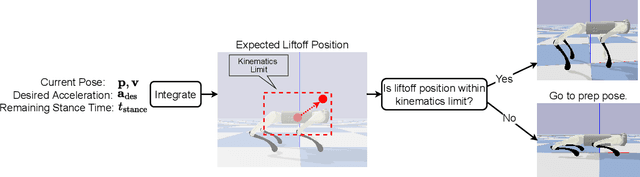

Jumping is essential for legged robots to traverse through difficult terrains. In this work, we propose a hierarchical framework that combines optimal control and reinforcement learning to learn continuous jumping motions for quadrupedal robots. The core of our framework is a stance controller, which combines a manually designed acceleration controller with a learned residual policy. As the acceleration controller warm starts policy for efficient training, the trained policy overcomes the limitation of the acceleration controller and improves the jumping stability. In addition, a low-level whole-body controller converts the body pose command from the stance controller to motor commands. After training in simulation, our framework can be deployed directly to the real robot, and perform versatile, continuous jumping motions, including omni-directional jumps at up to 50cm high, 60cm forward, and jump-turning at up to 90 degrees. Please visit our website for more results: https://sites.google.com/view/learning-to-jump.
TerrainNet: Visual Modeling of Complex Terrain for High-speed, Off-road Navigation
Mar 28, 2023



Effective use of camera-based vision systems is essential for robust performance in autonomous off-road driving, particularly in the high-speed regime. Despite success in structured, on-road settings, current end-to-end approaches for scene prediction have yet to be successfully adapted for complex outdoor terrain. To this end, we present TerrainNet, a vision-based terrain perception system for semantic and geometric terrain prediction for aggressive, off-road navigation. The approach relies on several key insights and practical considerations for achieving reliable terrain modeling. The network includes a multi-headed output representation to capture fine- and coarse-grained terrain features necessary for estimating traversability. Accurate depth estimation is achieved using self-supervised depth completion with multi-view RGB and stereo inputs. Requirements for real-time performance and fast inference speeds are met using efficient, learned image feature projections. Furthermore, the model is trained on a large-scale, real-world off-road dataset collected across a variety of diverse outdoor environments. We show how TerrainNet can also be used for costmap prediction and provide a detailed framework for integration into a planning module. We demonstrate the performance of TerrainNet through extensive comparison to current state-of-the-art baselines for camera-only scene prediction. Finally, we showcase the effectiveness of integrating TerrainNet within a complete autonomous-driving stack by conducting a real-world vehicle test in a challenging off-road scenario.