 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerrainNet: Visual Modeling of Complex Terrain for High-speed, Off-road Navigation
Mar 28, 2023



Effective use of camera-based vision systems is essential for robust performance in autonomous off-road driving, particularly in the high-speed regime. Despite success in structured, on-road settings, current end-to-end approaches for scene prediction have yet to be successfully adapted for complex outdoor terrain. To this end, we present TerrainNet, a vision-based terrain perception system for semantic and geometric terrain prediction for aggressive, off-road navigation. The approach relies on several key insights and practical considerations for achieving reliable terrain modeling. The network includes a multi-headed output representation to capture fine- and coarse-grained terrain features necessary for estimating traversability. Accurate depth estimation is achieved using self-supervised depth completion with multi-view RGB and stereo inputs. Requirements for real-time performance and fast inference speeds are met using efficient, learned image feature projections. Furthermore, the model is trained on a large-scale, real-world off-road dataset collected across a variety of diverse outdoor environments. We show how TerrainNet can also be used for costmap prediction and provide a detailed framework for integration into a planning module. We demonstrate the performance of TerrainNet through extensive comparison to current state-of-the-art baselines for camera-only scene prediction. Finally, we showcase the effectiveness of integrating TerrainNet within a complete autonomous-driving stack by conducting a real-world vehicle test in a challenging off-road scenario.
Learning Online from Corrective Feedback: A Meta-Algorithm for Robotics
Apr 02, 2021
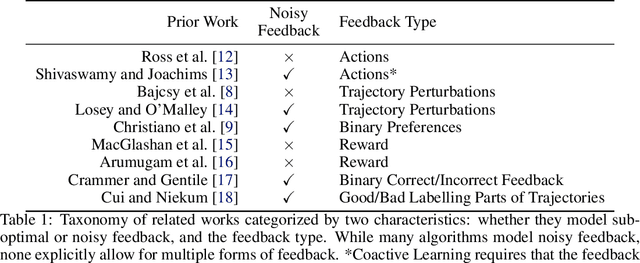

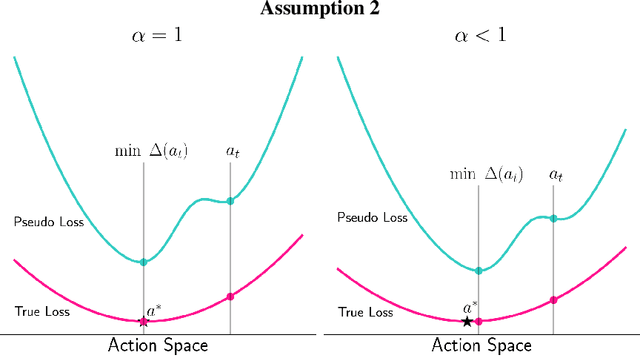
A key challenge in Imitation Learning (IL) is that optimal state actions demonstrations are difficult for the teacher to provide. For example in robotics, providing kinesthetic demonstrations on a robotic manipulator requires the teacher to control multiple degrees of freedom at once. The difficulty of requiring optimal state action demonstrations limits the space of problems where the teacher can provide quality feedback. As an alternative to state action demonstrations, the teacher can provide corrective feedback such as their preferences or rewards. Prior work has created algorithms designed to learn from specific types of noisy feedback, but across teachers and tasks different forms of feedback may be required. Instead we propose that in order to learn from a diversity of scenarios we need to learn from a variety of feedback. To learn from a variety of feedback we make the following insight: the teacher's cost function is latent and we can model a stream of feedback as a stream of loss functions. We then use any online learning algorithm to minimize the sum of these losses. With this insight we can learn from a diversity of feedback that is weakly correlated with the teacher's true cost function. We unify prior work into a general corrective feedback meta-algorithm and show that regardless of feedback we can obtain the same regret bounds. We demonstrate our approach by learning to perform a household navigation task on a robotic racecar platform. Our results show that our approach can learn quickly from a variety of noisy feedback.