 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA One-Inclusion Graph Approach to Multi-Group Learning
Mar 24, 2026We prove the tightest-known upper bounds on the sample complexity of multi-group learning. Our algorithm extends the one-inclusion graph prediction strategy using a generalization of bipartite $b$-matching. In the group-realizable setting, we provide a lower bound confirming that our algorithm's $\log n / n$ convergence rate is optimal in general. If one relaxes the learning objective such that the group on which we are evaluated is chosen obliviously of the sample, then our algorithm achieves the optimal $1/n$ convergence rate under group-realizability.
Group-realizable multi-group learning by minimizing empirical risk
Jan 23, 2026The sample complexity of multi-group learning is shown to improve in the group-realizable setting over the agnostic setting, even when the family of groups is infinite so long as it has finite VC dimension. The improved sample complexity is obtained by empirical risk minimization over the class of group-realizable concepts, which itself could have infinite VC dimension. Implementing this approach is also shown to be computationally intractable, and an alternative approach is suggested based on improper learning.
Group-wise oracle-efficient algorithms for online multi-group learning
Jun 07, 2024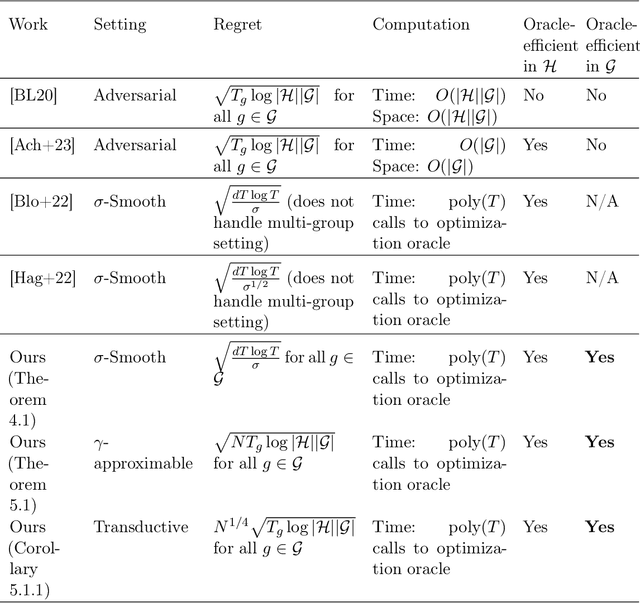
We study the problem of online multi-group learning, a learning model in which an online learner must simultaneously achieve small prediction regret on a large collection of (possibly overlapping) subsequences corresponding to a family of groups. Groups are subsets of the context space, and in fairness applications, they may correspond to subpopulations defined by expressive functions of demographic attributes. In contrast to previous work on this learning model, we consider scenarios in which the family of groups is too large to explicitly enumerate, and hence we seek algorithms that only access groups via an optimization oracle. In this paper, we design such oracle-efficient algorithms with sublinear regret under a variety of settings, including: (i) the i.i.d. setting, (ii) the adversarial setting with smoothed context distributions, and (iii) the adversarial transductive setting.
Multi-group Learning for Hierarchical Groups
Feb 01, 2024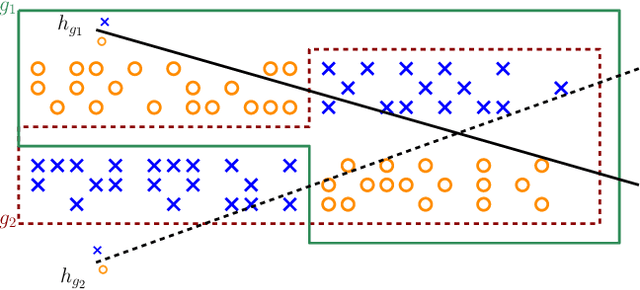

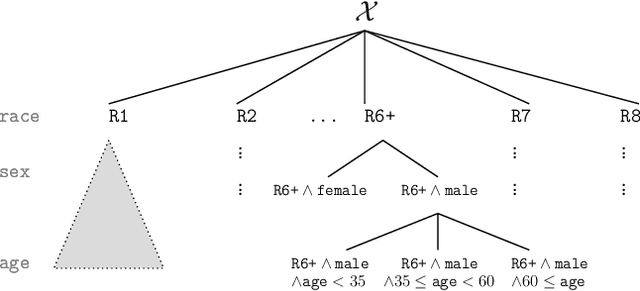
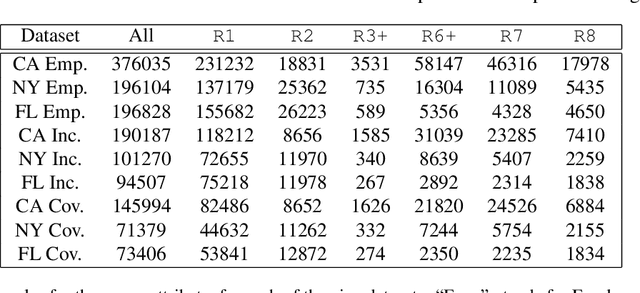
The multi-group learning model formalizes the learning scenario in which a single predictor must generalize well on multiple, possibly overlapping subgroups of interest. We extend the study of multi-group learning to the natural case where the groups are hierarchically structured. We design an algorithm for this setting that outputs an interpretable and deterministic decision tree predictor with near-optimal sample complexity. We then conduct an empirical evaluation of our algorithm and find that it achieves attractive generalization properties on real datasets with hierarchical group structure.
TerrainNet: Visual Modeling of Complex Terrain for High-speed, Off-road Navigation
Mar 28, 2023



Effective use of camera-based vision systems is essential for robust performance in autonomous off-road driving, particularly in the high-speed regime. Despite success in structured, on-road settings, current end-to-end approaches for scene prediction have yet to be successfully adapted for complex outdoor terrain. To this end, we present TerrainNet, a vision-based terrain perception system for semantic and geometric terrain prediction for aggressive, off-road navigation. The approach relies on several key insights and practical considerations for achieving reliable terrain modeling. The network includes a multi-headed output representation to capture fine- and coarse-grained terrain features necessary for estimating traversability. Accurate depth estimation is achieved using self-supervised depth completion with multi-view RGB and stereo inputs. Requirements for real-time performance and fast inference speeds are met using efficient, learned image feature projections. Furthermore, the model is trained on a large-scale, real-world off-road dataset collected across a variety of diverse outdoor environments. We show how TerrainNet can also be used for costmap prediction and provide a detailed framework for integration into a planning module. We demonstrate the performance of TerrainNet through extensive comparison to current state-of-the-art baselines for camera-only scene prediction. Finally, we showcase the effectiveness of integrating TerrainNet within a complete autonomous-driving stack by conducting a real-world vehicle test in a challenging off-road scenario.
Group conditional validity via multi-group learning
Mar 19, 2023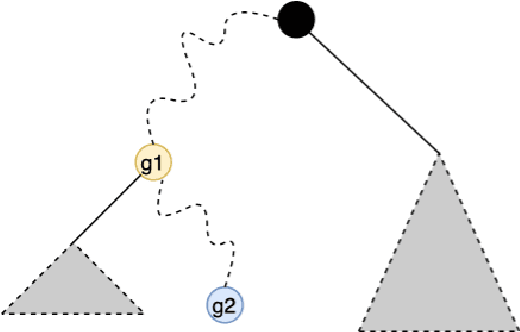
We consider the problem of distribution-free conformal prediction and the criterion of group conditional validity. This criterion is motivated by many practical scenarios including hidden stratification and group fairness. Existing methods achieve such guarantees under either restrictive grouping structure or distributional assumptions, or they are overly-conservative under heteroskedastic noise. We propose a simple reduction to the problem of achieving validity guarantees for individual populations by leveraging algorithms for a problem called multi-group learning. This allows us to port theoretical guarantees from multi-group learning to obtain obtain sample complexity guarantees for conformal prediction. We also provide a new algorithm for multi-group learning for groups with hierarchical structure. Using this algorithm in our reduction leads to improved sample complexity guarantees with a simpler predictor structure.
Learning Tensor Representations for Meta-Learning
Jan 18, 2022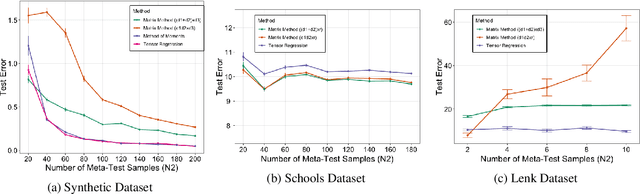
We introduce a tensor-based model of shared representation for meta-learning from a diverse set of tasks. Prior works on learning linear representations for meta-learning assume that there is a common shared representation across different tasks, and do not consider the additional task-specific observable side information. In this work, we model the meta-parameter through an order-$3$ tensor, which can adapt to the observed task features of the task. We propose two methods to estimate the underlying tensor. The first method solves a tensor regression problem and works under natural assumptions on the data generating process. The second method uses the method of moments under additional distributional assumptions and has an improved sample complexity in terms of the number of tasks. We also focus on the meta-test phase, and consider estimating task-specific parameters on a new task. Substituting the estimated tensor from the first step allows us estimating the task-specific parameters with very few samples of the new task, thereby showing the benefits of learning tensor representations for meta-learning. Finally, through simulation and several real-world datasets, we evaluate our methods and show that it improves over previous linear models of shared representations for meta-learning.
An Attack on InstaHide: Is Private Learning Possible with Instance Encoding?
Nov 10, 2020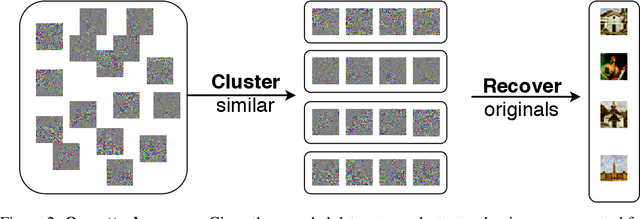



A learning algorithm is private if the produced model does not reveal (too much) about its training set. InstaHide [Huang, Song, Li, Arora, ICML'20] is a recent proposal that claims to preserve privacy by an encoding mechanism that modifies the inputs before being processed by the normal learner. We present a reconstruction attack on InstaHide that is able to use the encoded images to recover visually recognizable versions of the original images. Our attack is effective and efficient, and empirically breaks InstaHide on CIFAR-10, CIFAR-100, and the recently released InstaHide Challenge. We further formalize various privacy notions of learning through instance encoding and investigate the possibility of achieving these notions. We prove barriers against achieving (indistinguishability based notions of) privacy through any learning protocol that uses instance encoding.
Ensuring Fairness Beyond the Training Data
Jul 12, 2020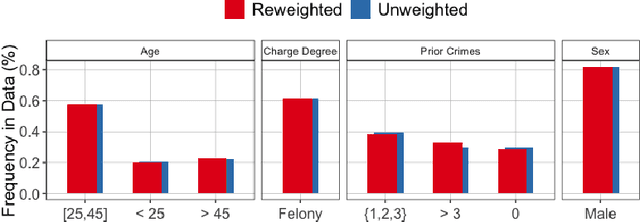

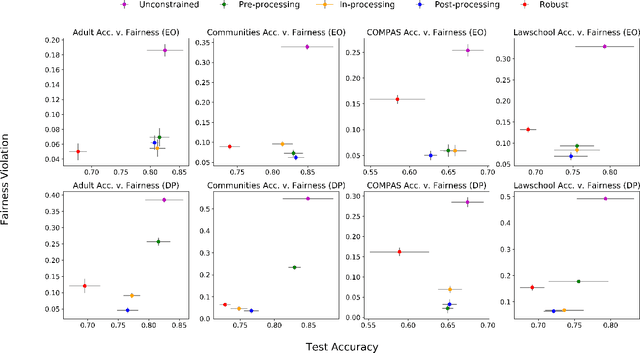
We initiate the study of fair classifiers that are robust to perturbations in the training distribution. Despite recent progress, the literature on fairness has largely ignored the design of fair and robust classifiers. In this work, we develop classifiers that are fair not only with respect to the training distribution, but also for a class of distributions that are weighted perturbations of the training samples. We formulate a min-max objective function whose goal is to minimize a distributionally robust training loss, and at the same time, find a classifier that is fair with respect to a class of distributions. We first reduce this problem to finding a fair classifier that is robust with respect to the class of distributions. Based on online learning algorithm, we develop an iterative algorithm that provably converges to such a fair and robust solution. Experiments on standard machine learning fairness datasets suggest that, compared to the state-of-the-art fair classifiers, our classifier retains fairness guarantees and test accuracy for a large class of perturbations on the test set. Furthermore, our experiments show that there is an inherent trade-off between fairness robustness and accuracy of such classifiers.
Methodological Blind Spots in Machine Learning Fairness: Lessons from the Philosophy of Science and Computer Science
Oct 31, 2019In the ML fairness literature, there have been few investigations through the viewpoint of philosophy, a lens that encourages the critical evaluation of basic assumptions. The purpose of this paper is to use three ideas from the philosophy of science and computer science to tease out blind spots in the assumptions that underlie ML fairness: abstraction, induction, and measurement. Through this investigation, we hope to warn of these methodological blind spots and encourage further interdisciplinary investigation in fair-ML through the framework of philosophy.