 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBypassing Prompt Guards in Production with Controlled-Release Prompting
Oct 02, 2025As large language models (LLMs) advance, ensuring AI safety and alignment is paramount. One popular approach is prompt guards, lightweight mechanisms designed to filter malicious queries while being easy to implement and update. In this work, we introduce a new attack that circumvents such prompt guards, highlighting their limitations. Our method consistently jailbreaks production models while maintaining response quality, even under the highly protected chat interfaces of Google Gemini (2.5 Flash/Pro), DeepSeek Chat (DeepThink), Grok (3), and Mistral Le Chat (Magistral). The attack exploits a resource asymmetry between the prompt guard and the main LLM, encoding a jailbreak prompt that lightweight guards cannot decode but the main model can. This reveals an attack surface inherent to lightweight prompt guards in modern LLM architectures and underscores the need to shift defenses from blocking malicious inputs to preventing malicious outputs. We additionally identify other critical alignment issues, such as copyrighted data extraction, training data extraction, and malicious response leakage during thinking.
SoK: Watermarking for AI-Generated Content
Nov 27, 2024

As the outputs of generative AI (GenAI) techniques improve in quality, it becomes increasingly challenging to distinguish them from human-created content. Watermarking schemes are a promising approach to address the problem of distinguishing between AI and human-generated content. These schemes embed hidden signals within AI-generated content to enable reliable detection. While watermarking is not a silver bullet for addressing all risks associated with GenAI, it can play a crucial role in enhancing AI safety and trustworthiness by combating misinformation and deception. This paper presents a comprehensive overview of watermarking techniques for GenAI, beginning with the need for watermarking from historical and regulatory perspectives. We formalize the definitions and desired properties of watermarking schemes and examine the key objectives and threat models for existing approaches. Practical evaluation strategies are also explored, providing insights into the development of robust watermarking techniques capable of resisting various attacks. Additionally, we review recent representative works, highlight open challenges, and discuss potential directions for this emerging field. By offering a thorough understanding of watermarking in GenAI, this work aims to guide researchers in advancing watermarking methods and applications, and support policymakers in addressing the broader implications of GenAI.
Publicly Detectable Watermarking for Language Models
Oct 27, 2023We construct the first provable watermarking scheme for language models with public detectability or verifiability: we use a private key for watermarking and a public key for watermark detection. Our protocol is the first watermarking scheme that does not embed a statistical signal in generated text. Rather, we directly embed a publicly-verifiable cryptographic signature using a form of rejection sampling. We show that our construction meets strong formal security guarantees and preserves many desirable properties found in schemes in the private-key watermarking setting. In particular, our watermarking scheme retains distortion-freeness and model agnosticity. We implement our scheme and make empirical measurements over open models in the 7B parameter range. Our experiments suggest that our watermarking scheme meets our formal claims while preserving text quality.
Overparameterized (robust) models from computational constraints
Aug 27, 2022Overparameterized models with millions of parameters have been hugely successful. In this work, we ask: can the need for large models be, at least in part, due to the \emph{computational} limitations of the learner? Additionally, we ask, is this situation exacerbated for \emph{robust} learning? We show that this indeed could be the case. We show learning tasks for which computationally bounded learners need \emph{significantly more} model parameters than what information-theoretic learners need. Furthermore, we show that even more model parameters could be necessary for robust learning. In particular, for computationally bounded learners, we extend the recent result of Bubeck and Sellke [NeurIPS'2021] which shows that robust models might need more parameters, to the computational regime and show that bounded learners could provably need an even larger number of parameters. Then, we address the following related question: can we hope to remedy the situation for robust computationally bounded learning by restricting \emph{adversaries} to also be computationally bounded for sake of obtaining models with fewer parameters? Here again, we show that this could be possible. Specifically, building on the work of Garg, Jha, Mahloujifar, and Mahmoody [ALT'2020], we demonstrate a learning task that can be learned efficiently and robustly against a computationally bounded attacker, while to be robust against an information-theoretic attacker requires the learner to utilize significantly more parameters.
Deletion Inference, Reconstruction, and Compliance in Machine (Un)Learning
Feb 07, 2022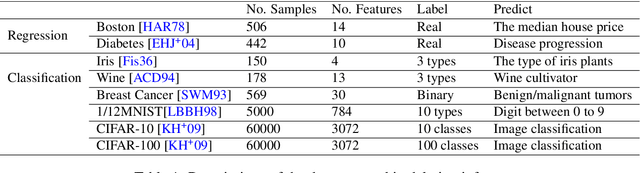
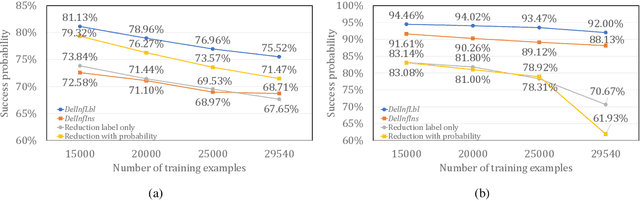
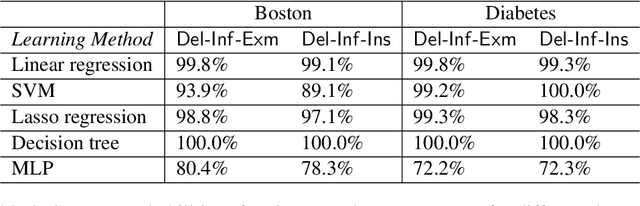
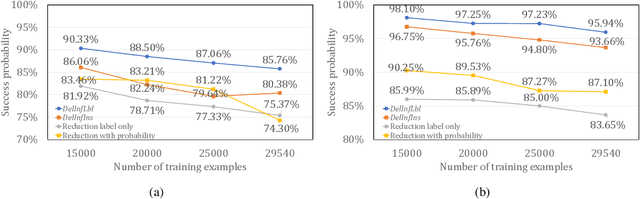
Privacy attacks on machine learning models aim to identify the data that is used to train such models. Such attacks, traditionally, are studied on static models that are trained once and are accessible by the adversary. Motivated to meet new legal requirements, many machine learning methods are recently extended to support machine unlearning, i.e., updating models as if certain examples are removed from their training sets, and meet new legal requirements. However, privacy attacks could potentially become more devastating in this new setting, since an attacker could now access both the original model before deletion and the new model after the deletion. In fact, the very act of deletion might make the deleted record more vulnerable to privacy attacks. Inspired by cryptographic definitions and the differential privacy framework, we formally study privacy implications of machine unlearning. We formalize (various forms of) deletion inference and deletion reconstruction attacks, in which the adversary aims to either identify which record is deleted or to reconstruct (perhaps part of) the deleted records. We then present successful deletion inference and reconstruction attacks for a variety of machine learning models and tasks such as classification, regression, and language models. Finally, we show that our attacks would provably be precluded if the schemes satisfy (variants of) Deletion Compliance (Garg, Goldwasser, and Vasudevan, Eurocrypt' 20).
An Attack on InstaHide: Is Private Learning Possible with Instance Encoding?
Nov 10, 2020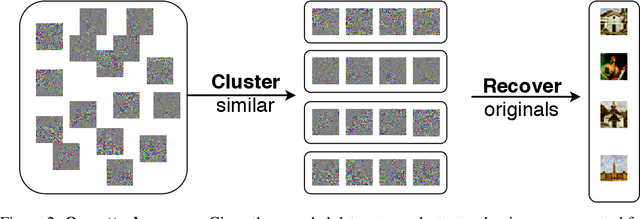



A learning algorithm is private if the produced model does not reveal (too much) about its training set. InstaHide [Huang, Song, Li, Arora, ICML'20] is a recent proposal that claims to preserve privacy by an encoding mechanism that modifies the inputs before being processed by the normal learner. We present a reconstruction attack on InstaHide that is able to use the encoded images to recover visually recognizable versions of the original images. Our attack is effective and efficient, and empirically breaks InstaHide on CIFAR-10, CIFAR-100, and the recently released InstaHide Challenge. We further formalize various privacy notions of learning through instance encoding and investigate the possibility of achieving these notions. We prove barriers against achieving (indistinguishability based notions of) privacy through any learning protocol that uses instance encoding.
Obliviousness Makes Poisoning Adversaries Weaker
Mar 26, 2020
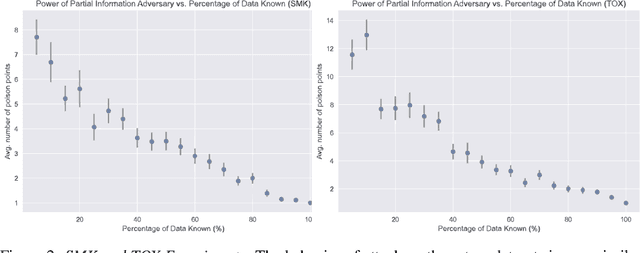

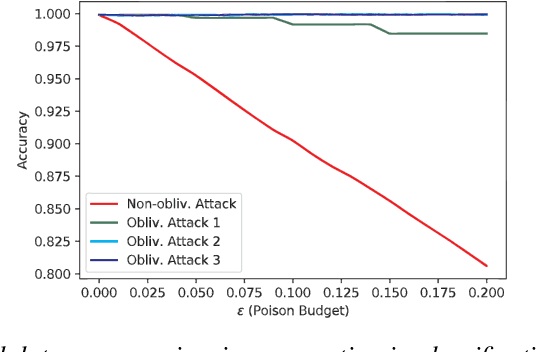
Poisoning attacks have emerged as a significant security threat to machine learning (ML) algorithms. It has been demonstrated that adversaries who make small changes to the training set, such as adding specially crafted data points, can hurt the performance of the output model. Most of these attacks require the full knowledge of training data or the underlying data distribution. In this paper we study the power of oblivious adversaries who do not have any information about the training set. We show a separation between oblivious and full-information poisoning adversaries. Specifically, we construct a sparse linear regression problem for which LASSO estimator is robust against oblivious adversaries whose goal is to add a non-relevant features to the model with certain poisoning budget. On the other hand, non-oblivious adversaries, with the same budget, can craft poisoning examples based on the rest of the training data and successfully add non-relevant features to the model.
Adversarially Robust Learning Could Leverage Computational Hardness
May 28, 2019Over recent years, devising classification algorithms that are robust to adversarial perturbations has emerged as a challenging problem. In particular, deep neural nets (DNNs) seem to be susceptible to small imperceptible changes over test instances. In this work, we study whether there is any learning task for which it is possible to design classifiers that are only robust against polynomial-time adversaries. Indeed, numerous cryptographic tasks (e.g. encryption of long messages) are only be secure against computationally bounded adversaries, and are indeed mpossible for computationally unbounded attackers. Thus, it is natural to ask if the same strategy could help robust learning. We show that computational limitation of attackers can indeed be useful in robust learning by demonstrating a classifier for a learning task in which computational and information theoretic adversaries of bounded perturbations have very different power. Namely, while computationally unbounded adversaries can attack successfully and find adversarial examples with small perturbation, polynomial time adversaries are unable to do so unless they can break standard cryptographic hardness assumptions. Our results, therefore, indicate that perhaps a similar approach to cryptography (relying on computational hardness) holds promise for achieving computationally robust machine learning. We also show that the existence of such learning task in which computational robustness beats information theoretic robustness implies (average case) hard problems in $\mathbf{NP}$.