 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Inject: Automated Prompt Injection via Reinforcement Learning
Feb 05, 2026Prompt injection is one of the most critical vulnerabilities in LLM agents; yet, effective automated attacks remain largely unexplored from an optimization perspective. Existing methods heavily depend on human red-teamers and hand-crafted prompts, limiting their scalability and adaptability. We propose AutoInject, a reinforcement learning framework that generates universal, transferable adversarial suffixes while jointly optimizing for attack success and utility preservation on benign tasks. Our black-box method supports both query-based optimization and transfer attacks to unseen models and tasks. Using only a 1.5B parameter adversarial suffix generator, we successfully compromise frontier systems including GPT 5 Nano, Claude Sonnet 3.5, and Gemini 2.5 Flash on the AgentDojo benchmark, establishing a stronger baseline for automated prompt injection research.
Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
Jan 13, 2025



It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.
SoK: Watermarking for AI-Generated Content
Nov 27, 2024

As the outputs of generative AI (GenAI) techniques improve in quality, it becomes increasingly challenging to distinguish them from human-created content. Watermarking schemes are a promising approach to address the problem of distinguishing between AI and human-generated content. These schemes embed hidden signals within AI-generated content to enable reliable detection. While watermarking is not a silver bullet for addressing all risks associated with GenAI, it can play a crucial role in enhancing AI safety and trustworthiness by combating misinformation and deception. This paper presents a comprehensive overview of watermarking techniques for GenAI, beginning with the need for watermarking from historical and regulatory perspectives. We formalize the definitions and desired properties of watermarking schemes and examine the key objectives and threat models for existing approaches. Practical evaluation strategies are also explored, providing insights into the development of robust watermarking techniques capable of resisting various attacks. Additionally, we review recent representative works, highlight open challenges, and discuss potential directions for this emerging field. By offering a thorough understanding of watermarking in GenAI, this work aims to guide researchers in advancing watermarking methods and applications, and support policymakers in addressing the broader implications of GenAI.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024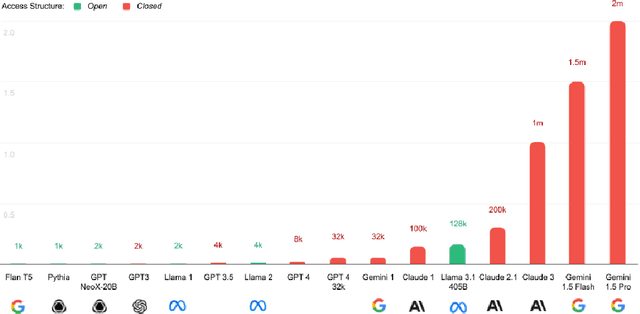



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
Mar 28, 2024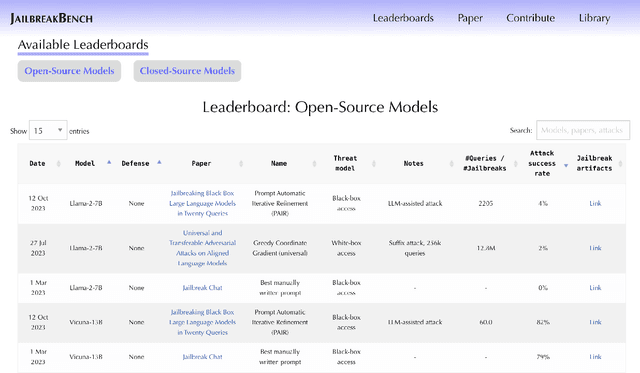


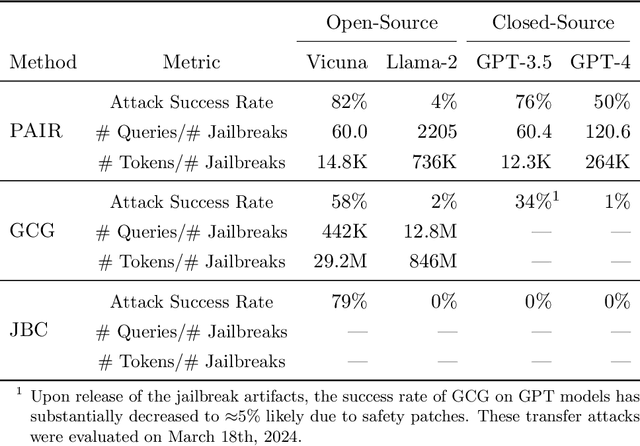
Jailbreak attacks cause large language models (LLMs) to generate harmful, unethical, or otherwise objectionable content. Evaluating these attacks presents a number of challenges, which the current collection of benchmarks and evaluation techniques do not adequately address. First, there is no clear standard of practice regarding jailbreaking evaluation. Second, existing works compute costs and success rates in incomparable ways. And third, numerous works are not reproducible, as they withhold adversarial prompts, involve closed-source code, or rely on evolving proprietary APIs. To address these challenges, we introduce JailbreakBench, an open-sourced benchmark with the following components: (1) a new jailbreaking dataset containing 100 unique behaviors, which we call JBB-Behaviors; (2) an evolving repository of state-of-the-art adversarial prompts, which we refer to as jailbreak artifacts; (3) a standardized evaluation framework that includes a clearly defined threat model, system prompts, chat templates, and scoring functions; and (4) a leaderboard that tracks the performance of attacks and defenses for various LLMs. We have carefully considered the potential ethical implications of releasing this benchmark, and believe that it will be a net positive for the community. Over time, we will expand and adapt the benchmark to reflect technical and methodological advances in the research community.
Are aligned neural networks adversarially aligned?
Jun 26, 2023



Large language models are now tuned to align with the goals of their creators, namely to be "helpful and harmless." These models should respond helpfully to user questions, but refuse to answer requests that could cause harm. However, adversarial users can construct inputs which circumvent attempts at alignment. In this work, we study to what extent these models remain aligned, even when interacting with an adversarial user who constructs worst-case inputs (adversarial examples). These inputs are designed to cause the model to emit harmful content that would otherwise be prohibited. We show that existing NLP-based optimization attacks are insufficiently powerful to reliably attack aligned text models: even when current NLP-based attacks fail, we can find adversarial inputs with brute force. As a result, the failure of current attacks should not be seen as proof that aligned text models remain aligned under adversarial inputs. However the recent trend in large-scale ML models is multimodal models that allow users to provide images that influence the text that is generated. We show these models can be easily attacked, i.e., induced to perform arbitrary un-aligned behavior through adversarial perturbation of the input image. We conjecture that improved NLP attacks may demonstrate this same level of adversarial control over text-only models.
Increasing Confidence in Adversarial Robustness Evaluations
Jun 28, 2022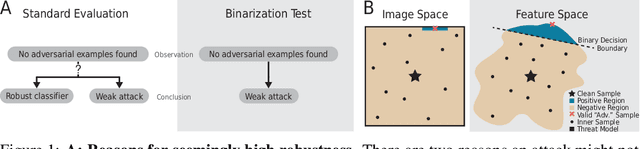
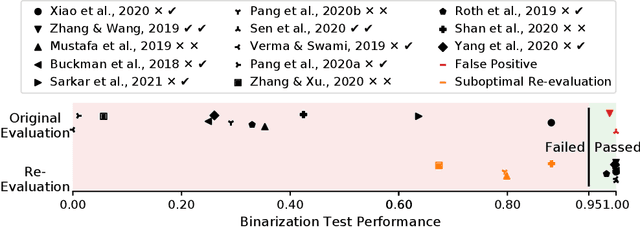
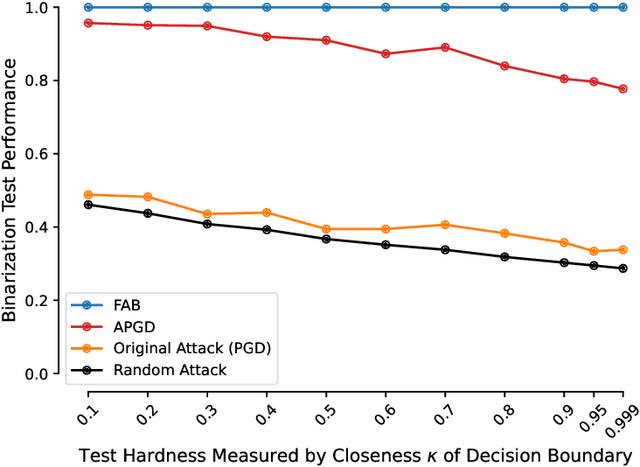
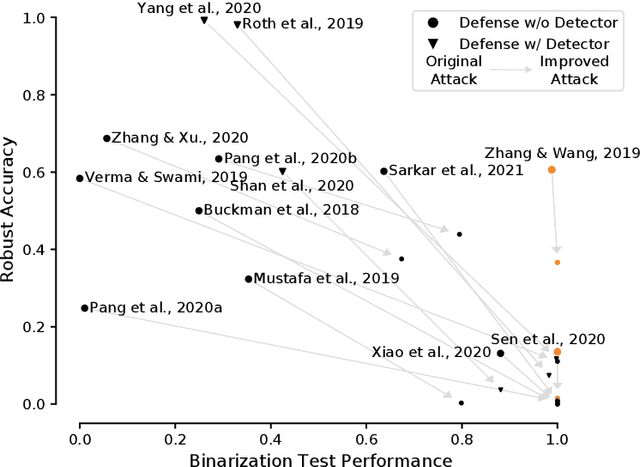
Hundreds of defenses have been proposed to make deep neural networks robust against minimal (adversarial) input perturbations. However, only a handful of these defenses held up their claims because correctly evaluating robustness is extremely challenging: Weak attacks often fail to find adversarial examples even if they unknowingly exist, thereby making a vulnerable network look robust. In this paper, we propose a test to identify weak attacks, and thus weak defense evaluations. Our test slightly modifies a neural network to guarantee the existence of an adversarial example for every sample. Consequentially, any correct attack must succeed in breaking this modified network. For eleven out of thirteen previously-published defenses, the original evaluation of the defense fails our test, while stronger attacks that break these defenses pass it. We hope that attack unit tests - such as ours - will be a major component in future robustness evaluations and increase confidence in an empirical field that is currently riddled with skepticism.
The Privacy Onion Effect: Memorization is Relative
Jun 22, 2022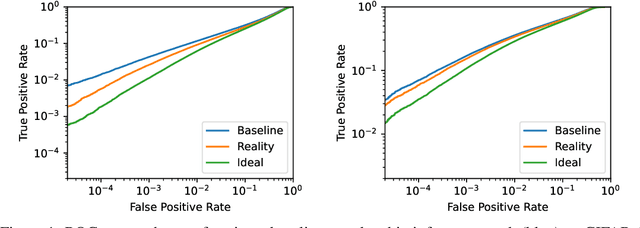
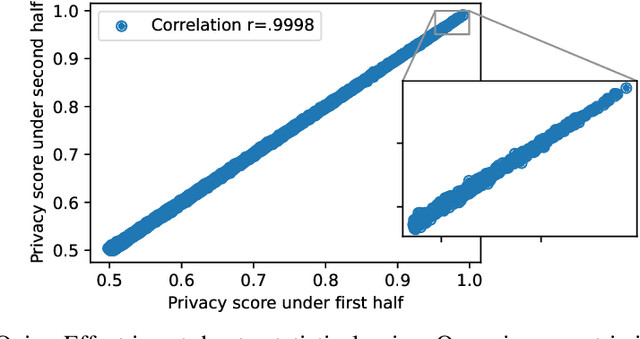
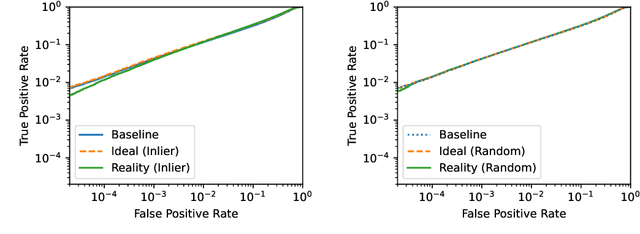
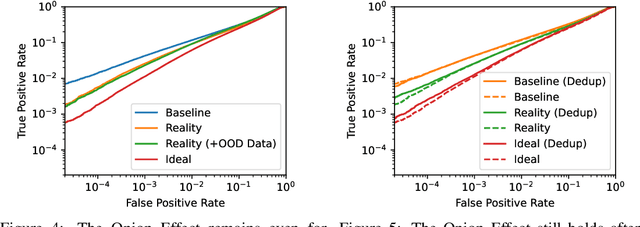
Machine learning models trained on private datasets have been shown to leak their private data. While recent work has found that the average data point is rarely leaked, the outlier samples are frequently subject to memorization and, consequently, privacy leakage. We demonstrate and analyse an Onion Effect of memorization: removing the "layer" of outlier points that are most vulnerable to a privacy attack exposes a new layer of previously-safe points to the same attack. We perform several experiments to study this effect, and understand why it occurs. The existence of this effect has various consequences. For example, it suggests that proposals to defend against memorization without training with rigorous privacy guarantees are unlikely to be effective. Further, it suggests that privacy-enhancing technologies such as machine unlearning could actually harm the privacy of other users.
(Certified!!) Adversarial Robustness for Free!
Jun 21, 2022
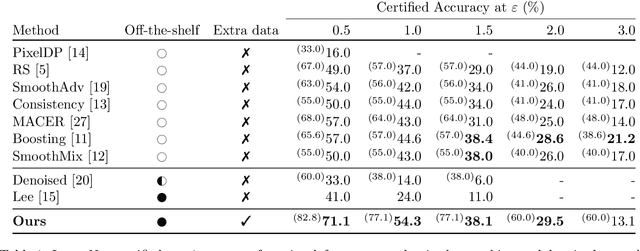
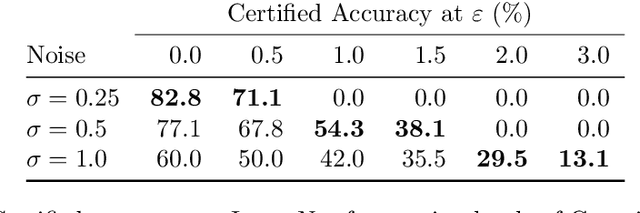

In this paper we show how to achieve state-of-the-art certified adversarial robustness to 2-norm bounded perturbations by relying exclusively on off-the-shelf pretrained models. To do so, we instantiate the denoised smoothing approach of Salman et al. by combining a pretrained denoising diffusion probabilistic model and a standard high-accuracy classifier. This allows us to certify 71% accuracy on ImageNet under adversarial perturbations constrained to be within a 2-norm of 0.5, an improvement of 14 percentage points over the prior certified SoTA using any approach, or an improvement of 30 percentage points over denoised smoothing. We obtain these results using only pretrained diffusion models and image classifiers, without requiring any fine tuning or retraining of model parameters.
Debugging Differential Privacy: A Case Study for Privacy Auditing
Mar 28, 2022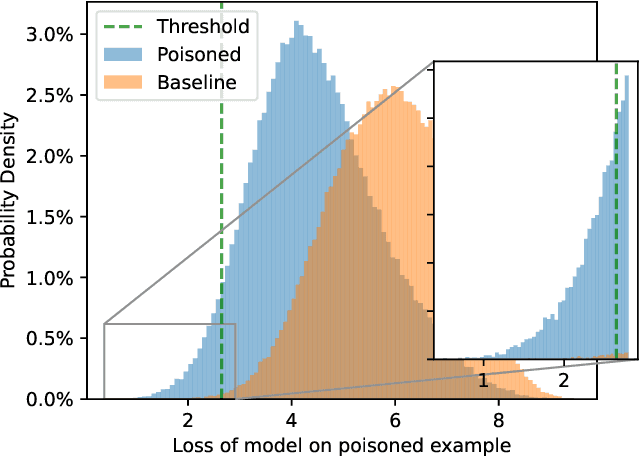
Differential Privacy can provide provable privacy guarantees for training data in machine learning. However, the presence of proofs does not preclude the presence of errors. Inspired by recent advances in auditing which have been used for estimating lower bounds on differentially private algorithms, here we show that auditing can also be used to find flaws in (purportedly) differentially private schemes. In this case study, we audit a recent open source implementation of a differentially private deep learning algorithm and find, with 99.99999999% confidence, that the implementation does not satisfy the claimed differential privacy guarantee.