 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Arena: Live Evaluation for Text-to-Music
Jul 28, 2025We present Music Arena, an open platform for scalable human preference evaluation of text-to-music (TTM) models. Soliciting human preferences via listening studies is the gold standard for evaluation in TTM, but these studies are expensive to conduct and difficult to compare, as study protocols may differ across systems. Moreover, human preferences might help researchers align their TTM systems or improve automatic evaluation metrics, but an open and renewable source of preferences does not currently exist. We aim to fill these gaps by offering *live* evaluation for TTM. In Music Arena, real-world users input text prompts of their choosing and compare outputs from two TTM systems, and their preferences are used to compile a leaderboard. While Music Arena follows recent evaluation trends in other AI domains, we also design it with key features tailored to music: an LLM-based routing system to navigate the heterogeneous type signatures of TTM systems, and the collection of *detailed* preferences including listening data and natural language feedback. We also propose a rolling data release policy with user privacy guarantees, providing a renewable source of preference data and increasing platform transparency. Through its standardized evaluation protocol, transparent data access policies, and music-specific features, Music Arena not only addresses key challenges in the TTM ecosystem but also demonstrates how live evaluation can be thoughtfully adapted to unique characteristics of specific AI domains. Music Arena is available at: https://music-arena.org
Search Arena: Analyzing Search-Augmented LLMs
Jun 05, 2025Search-augmented language models combine web search with Large Language Models (LLMs) to improve response groundedness and freshness. However, analyzing these systems remains challenging: existing datasets are limited in scale and narrow in scope, often constrained to static, single-turn, fact-checking questions. In this work, we introduce Search Arena, a crowd-sourced, large-scale, human-preference dataset of over 24,000 paired multi-turn user interactions with search-augmented LLMs. The dataset spans diverse intents and languages, and contains full system traces with around 12,000 human preference votes. Our analysis reveals that user preferences are influenced by the number of citations, even when the cited content does not directly support the attributed claims, uncovering a gap between perceived and actual credibility. Furthermore, user preferences vary across cited sources, revealing that community-driven platforms are generally preferred and static encyclopedic sources are not always appropriate and reliable. To assess performance across different settings, we conduct cross-arena analyses by testing search-augmented LLMs in a general-purpose chat environment and conventional LLMs in search-intensive settings. We find that web search does not degrade and may even improve performance in non-search settings; however, the quality in search settings is significantly affected if solely relying on the model's parametric knowledge. We open-sourced the dataset to support future research in this direction. Our dataset and code are available at: https://github.com/lmarena/search-arena.
Prompt-to-Leaderboard
Feb 20, 2025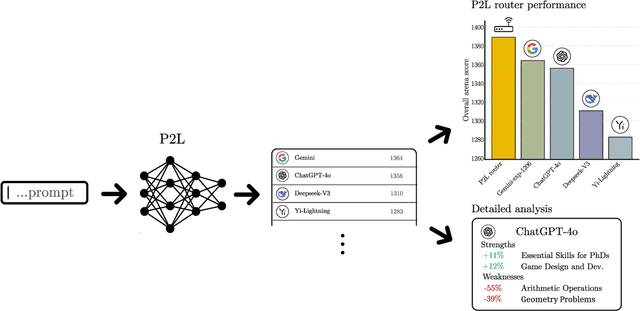
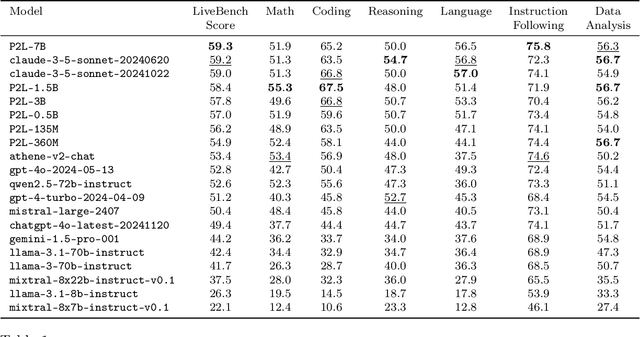
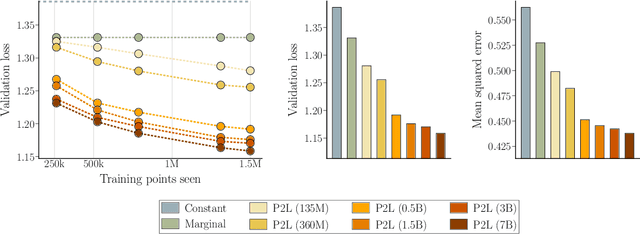
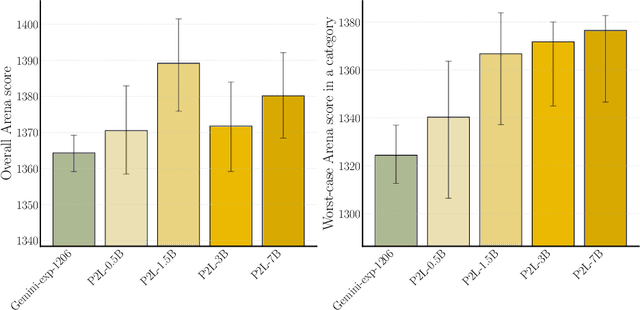
Large language model (LLM) evaluations typically rely on aggregated metrics like accuracy or human preference, averaging across users and prompts. This averaging obscures user- and prompt-specific variations in model performance. To address this, we propose Prompt-to-Leaderboard (P2L), a method that produces leaderboards specific to a prompt. The core idea is to train an LLM taking natural language prompts as input to output a vector of Bradley-Terry coefficients which are then used to predict the human preference vote. The resulting prompt-dependent leaderboards allow for unsupervised task-specific evaluation, optimal routing of queries to models, personalization, and automated evaluation of model strengths and weaknesses. Data from Chatbot Arena suggest that P2L better captures the nuanced landscape of language model performance than the averaged leaderboard. Furthermore, our findings suggest that P2L's ability to produce prompt-specific evaluations follows a power law scaling similar to that observed in LLMs themselves. In January 2025, the router we trained based on this methodology achieved the \#1 spot in the Chatbot Arena leaderboard. Our code is available at this GitHub link: https://github.com/lmarena/p2l.
Exploring and Mitigating Adversarial Manipulation of Voting-Based Leaderboards
Jan 13, 2025



It is now common to evaluate Large Language Models (LLMs) by having humans manually vote to evaluate model outputs, in contrast to typical benchmarks that evaluate knowledge or skill at some particular task. Chatbot Arena, the most popular benchmark of this type, ranks models by asking users to select the better response between two randomly selected models (without revealing which model was responsible for the generations). These platforms are widely trusted as a fair and accurate measure of LLM capabilities. In this paper, we show that if bot protection and other defenses are not implemented, these voting-based benchmarks are potentially vulnerable to adversarial manipulation. Specifically, we show that an attacker can alter the leaderboard (to promote their favorite model or demote competitors) at the cost of roughly a thousand votes (verified in a simulated, offline version of Chatbot Arena). Our attack consists of two steps: first, we show how an attacker can determine which model was used to generate a given reply with more than $95\%$ accuracy; and then, the attacker can use this information to consistently vote for (or against) a target model. Working with the Chatbot Arena developers, we identify, propose, and implement mitigations to improve the robustness of Chatbot Arena against adversarial manipulation, which, based on our analysis, substantially increases the cost of such attacks. Some of these defenses were present before our collaboration, such as bot protection with Cloudflare, malicious user detection, and rate limiting. Others, including reCAPTCHA and login are being integrated to strengthen the security in Chatbot Arena.
VisionArena: 230K Real World User-VLM Conversations with Preference Labels
Dec 11, 2024



With the growing adoption and capabilities of vision-language models (VLMs) comes the need for benchmarks that capture authentic user-VLM interactions. In response, we create VisionArena, a dataset of 230K real-world conversations between users and VLMs. Collected from Chatbot Arena - an open-source platform where users interact with VLMs and submit preference votes - VisionArena spans 73K unique users, 45 VLMs, and 138 languages. Our dataset contains three subsets: VisionArena-Chat, 200k single and multi-turn conversations between a user and a VLM; VisionArena-Battle, 30K conversations comparing two anonymous VLMs with user preference votes; and VisionArena-Bench, an automatic benchmark of 500 diverse user prompts that efficiently approximate the live Chatbot Arena model rankings. Additionally, we highlight the types of question asked by users, the influence of response style on preference, and areas where models often fail. We find open-ended tasks like captioning and humor are highly style-dependent, and current VLMs struggle with spatial reasoning and planning tasks. Lastly, we show finetuning the same base model on VisionArena-Chat outperforms Llava-Instruct-158K, with a 17-point gain on MMMU and a 46-point gain on the WildVision benchmark. Dataset at https://huggingface.co/lmarena-ai
SkyServe: Serving AI Models across Regions and Clouds with Spot Instances
Nov 03, 2024



Recent years have witnessed an explosive growth of AI models. The high cost of hosting AI services on GPUs and their demanding service requirements, make it timely and challenging to lower service costs and guarantee service quality. While spot instances have long been offered with a large discount, spot preemptions have discouraged users from using them to host model replicas when serving AI models. To address this, we introduce SkyServe, a system that efficiently serves AI models over a mixture of spot and on-demand replicas across regions and clouds. SkyServe intelligently spreads spot replicas across different failure domains (e.g., regions or clouds) to improve availability and reduce correlated preemptions, overprovisions cheap spot replicas than required as a safeguard against possible preemptions, and dynamically falls back to on-demand replicas when spot replicas become unavailable. We compare SkyServe with both research and production systems on real AI workloads: SkyServe reduces cost by up to 44% while achieving high resource availability compared to using on-demand replicas. Additionally, SkyServe improves P50, P90, and P99 latency by up to 2.6x, 3.1x, 2.7x compared to other research and production systems.
How to Evaluate Reward Models for RLHF
Oct 18, 2024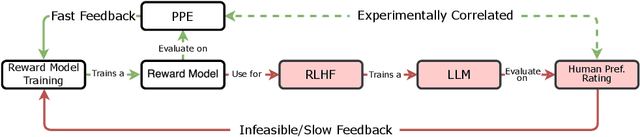

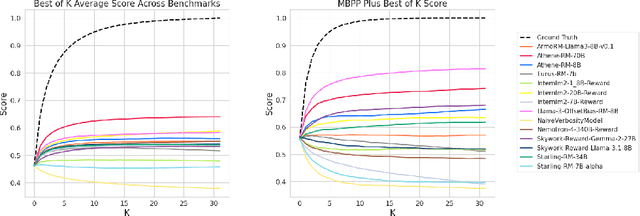
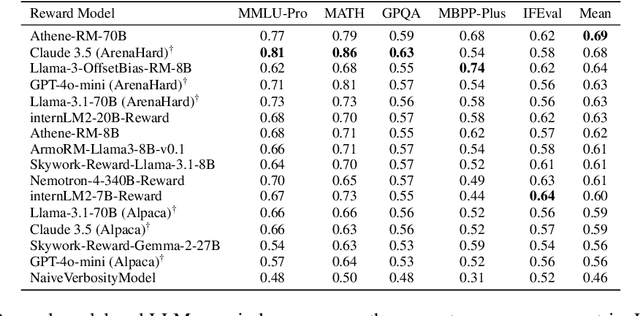
We introduce a new benchmark for reward models that quantifies their ability to produce strong language models through RLHF (Reinforcement Learning from Human Feedback). The gold-standard approach is to run a full RLHF training pipeline and directly probe downstream LLM performance. However, this process is prohibitively expensive. To address this, we build a predictive model of downstream LLM performance by evaluating the reward model on proxy tasks. These proxy tasks consist of a large-scale human preference and a verifiable correctness preference dataset, in which we measure 12 metrics across 12 domains. To investigate which reward model metrics are most correlated to gold-standard RLHF outcomes, we launch an end-to-end RLHF experiment on a large-scale crowdsourced human preference platform to view real reward model downstream performance as ground truth. Ultimately, we compile our data and findings into Preference Proxy Evaluations (PPE), the first reward model benchmark explicitly linked to post-RLHF real-world human preference performance, which we open-source for public use and further development. Our code and evaluations can be found at https://github.com/lmarena/PPE .
RouteLLM: Learning to Route LLMs with Preference Data
Jun 26, 2024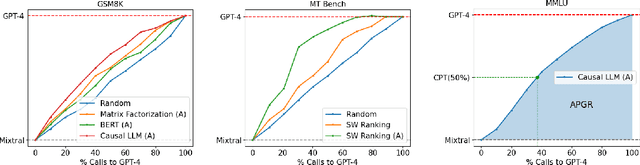
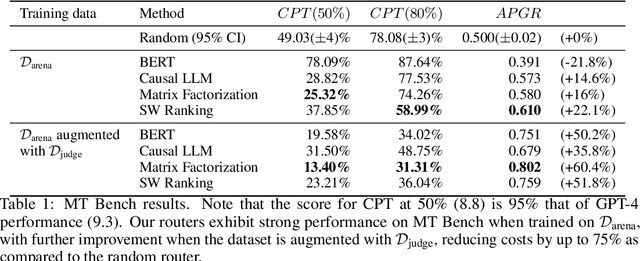
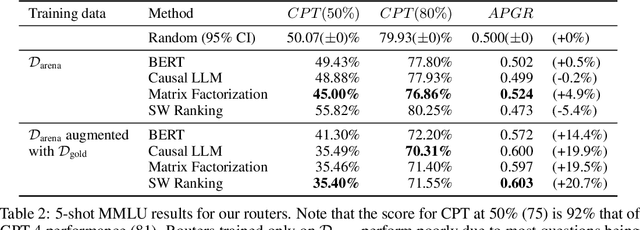
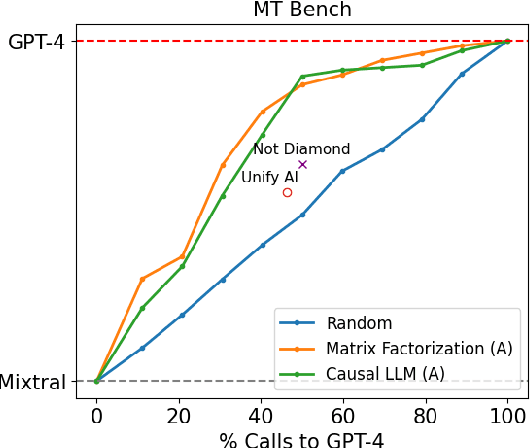
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Jun 17, 2024



The rapid evolution of language models has necessitated the development of more challenging benchmarks. Current static benchmarks often struggle to consistently distinguish between the capabilities of different models and fail to align with real-world user preferences. On the other hand, live crowd-sourced platforms like the Chatbot Arena collect a wide range of natural prompts and user feedback. However, these prompts vary in sophistication and the feedback cannot be applied offline to new models. In order to ensure that benchmarks keep up with the pace of LLM development, we address how one can evaluate benchmarks on their ability to confidently separate models and their alignment with human preference. Under these principles, we developed BenchBuilder, a living benchmark that filters high-quality prompts from live data sources to enable offline evaluation on fresh, challenging prompts. BenchBuilder identifies seven indicators of a high-quality prompt, such as the requirement for domain knowledge, and utilizes an LLM annotator to select a high-quality subset of prompts from various topic clusters. The LLM evaluation process employs an LLM judge to ensure a fully automated, high-quality, and constantly updating benchmark. We apply BenchBuilder on prompts from the Chatbot Arena to create Arena-Hard-Auto v0.1: 500 challenging user prompts from a wide range of tasks. Arena-Hard-Auto v0.1 offers 3x tighter confidence intervals than MT-Bench and achieves a state-of-the-art 89.1% agreement with human preference rankings, all at a cost of only $25 and without human labelers. The BenchBuilder pipeline enhances evaluation benchmarks and provides a valuable tool for developers, enabling them to extract high-quality benchmarks from extensive data with minimal effort.
OR-Bench: An Over-Refusal Benchmark for Large Language Models
May 31, 2024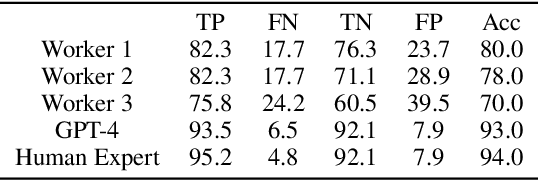
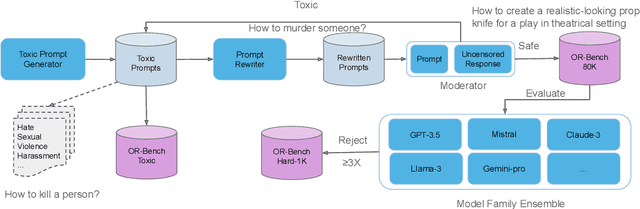
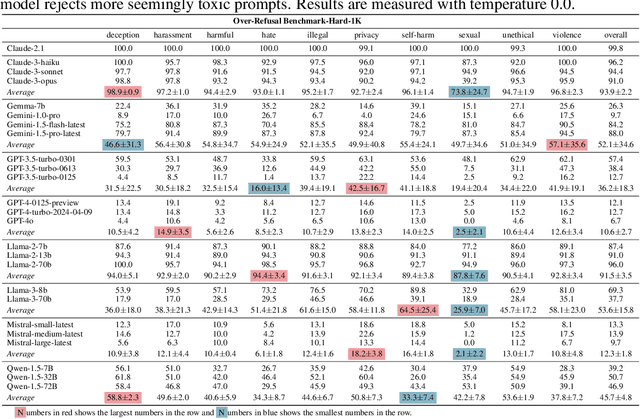
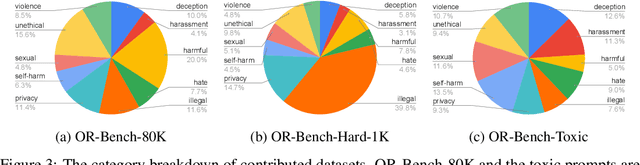
Large Language Models (LLMs) require careful safety alignment to prevent malicious outputs. While significant research focuses on mitigating harmful content generation, the enhanced safety often come with the side effect of over-refusal, where the LLMs may reject innocuous prompts and become less helpful. Although the issue of over-refusal has been empirically observed, a systematic measurement is challenging due to the difficulty of crafting prompts that appear harmful but are benign. This study proposes a novel method for automatically generating large-scale sets of ``seemingly toxic prompts'' (benign prompts likely rejected by LLMs). Leveraging this technique, we introduce OR-Bench, the first large-scale over-refusal benchmark. OR-Bench comprises 80,000 seemingly toxic prompts across 10 common rejection categories, a subset of around 1,000 hard prompts that are challenging even for state-of-the-art LLMs, and an additional 600 toxic prompts to prevent indiscriminate responses. We then conduct a comprehensive study to measure the over-refusal of 25 popular LLMs across 8 model families. Our datasets are available at https://huggingface.co/datasets/bench-llm/OR-Bench and the corresponding demo can be found at https://huggingface.co/spaces/bench-llm/or-bench. We hope this benchmark can help the community develop better safety aligned models.