 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotionScape: A Large-Scale Real-World Highly Dynamic UAV Video Dataset for World Models
Apr 09, 2026Recent advances in world models have demonstrated strong capabilities in simulating physical reality, making them an increasingly important foundation for embodied intelligence. For UAV agents in particular, accurate prediction of complex 3D dynamics is essential for autonomous navigation and robust decision-making in unconstrained environments. However, under the highly dynamic camera trajectories typical of UAV views, existing world models often struggle to maintain spatiotemporal physical consistency. A key reason lies in the distribution bias of current training data: most existing datasets exhibit restricted 2.5D motion patterns, such as ground-constrained autonomous driving scenes or relatively smooth human-centric egocentric videos, and therefore lack realistic high-dynamic 6-DoF UAV motion priors. To address this gap, we present MotionScape, a large-scale real-world UAV-view video dataset with highly dynamic motion for world modeling. MotionScape contains over 30 hours of 4K UAV-view videos, totaling more than 4.5M frames. This novel dataset features semantically and geometrically aligned training samples, where diverse real-world UAV videos are tightly coupled with accurate 6-DoF camera trajectories and fine-grained natural language descriptions. To build the dataset, we develop an automated multi-stage processing pipeline that integrates CLIP-based relevance filtering, temporal segmentation, robust visual SLAM for trajectory recovery, and large-language-model-driven semantic annotation. Extensive experiments show that incorporating such semantically and geometrically aligned annotations effectively improves the ability of existing world models to simulate complex 3D dynamics and handle large viewpoint shifts, thereby benefiting decision-making and planning for UAV agents in complex environments. The dataset is publicly available at https://github.com/Thelegendzz/MotionScape
RAPTOR: Real-Time High-Resolution UAV Video Prediction with Efficient Video Attention
Dec 25, 2025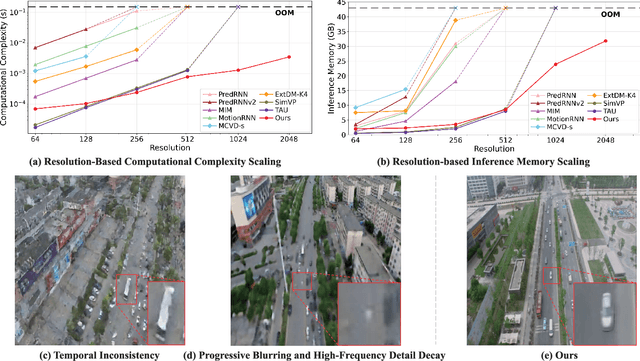



Video prediction is plagued by a fundamental trilemma: achieving high-resolution and perceptual quality typically comes at the cost of real-time speed, hindering its use in latency-critical applications. This challenge is most acute for autonomous UAVs in dense urban environments, where foreseeing events from high-resolution imagery is non-negotiable for safety. Existing methods, reliant on iterative generation (diffusion, autoregressive models) or quadratic-complexity attention, fail to meet these stringent demands on edge hardware. To break this long-standing trade-off, we introduce RAPTOR, a video prediction architecture that achieves real-time, high-resolution performance. RAPTOR's single-pass design avoids the error accumulation and latency of iterative approaches. Its core innovation is Efficient Video Attention (EVA), a novel translator module that factorizes spatiotemporal modeling. Instead of processing flattened spacetime tokens with $O((ST)^2)$ or $O(ST)$ complexity, EVA alternates operations along the spatial (S) and temporal (T) axes. This factorization reduces the time complexity to $O(S + T)$ and memory complexity to $O(max(S, T))$, enabling global context modeling at $512^2$ resolution and beyond, operating directly on dense feature maps with a patch-free design. Complementing this architecture is a 3-stage training curriculum that progressively refines predictions from coarse structure to sharp, temporally coherent details. Experiments show RAPTOR is the first predictor to exceed 30 FPS on a Jetson AGX Orin for $512^2$ video, setting a new state-of-the-art on UAVid, KTH, and a custom high-resolution dataset in PSNR, SSIM, and LPIPS. Critically, RAPTOR boosts the mission success rate in a real-world UAV navigation task by 18/%, paving the way for safer and more anticipatory embodied agents.
WGRAMMAR: Leverage Prior Knowledge to Accelerate Structured Decoding
Jul 22, 2025Structured decoding enables large language models (LLMs) to generate outputs in formats required by downstream systems, such as HTML or JSON. However, existing methods suffer from efficiency bottlenecks due to grammar compilation, state tracking, and mask creation. We observe that many real-world tasks embed strong prior knowledge about output structure. Leveraging this, we propose a decomposition of constraints into static and dynamic components -- precompiling static structures offline and instantiating dynamic arguments at runtime using grammar snippets. Instead of relying on pushdown automata, we employ a compositional set of operators to model regular formats, achieving lower transition latency. We introduce wgrammar, a lightweight decoding engine that integrates domain-aware simplification, constraint decomposition, and mask caching, achieving up to 250x speedup over existing systems. wgrammar's source code is publicly available at https://github.com/wrran/wgrammar.
MoE-Lightning: High-Throughput MoE Inference on Memory-constrained GPUs
Nov 18, 2024



Efficient deployment of large language models, particularly Mixture of Experts (MoE), on resource-constrained platforms presents significant challenges, especially in terms of computational efficiency and memory utilization. The MoE architecture, renowned for its ability to increase model capacity without a proportional increase in inference cost, greatly reduces the token generation latency compared with dense models. However, the large model size makes MoE models inaccessible to individuals without high-end GPUs. In this paper, we propose a high-throughput MoE batch inference system, that significantly outperforms past work. MoE-Lightning introduces a novel CPU-GPU-I/O pipelining schedule, CGOPipe, with paged weights to achieve high resource utilization, and a performance model, HRM, based on a Hierarchical Roofline Model we introduce to help find policies with higher throughput than existing systems. MoE-Lightning can achieve up to 10.3x higher throughput than state-of-the-art offloading-enabled LLM inference systems for Mixtral 8x7B on a single T4 GPU (16GB). When the theoretical system throughput is bounded by the GPU memory, MoE-Lightning can reach the throughput upper bound with 2-3x less CPU memory, significantly increasing resource utilization. MoE-Lightning also supports efficient batch inference for much larger MoEs (e.g., Mixtral 8x22B and DBRX) on multiple low-cost GPUs (e.g., 2-4 T4).
UNetMamba: An Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images
Aug 26, 2024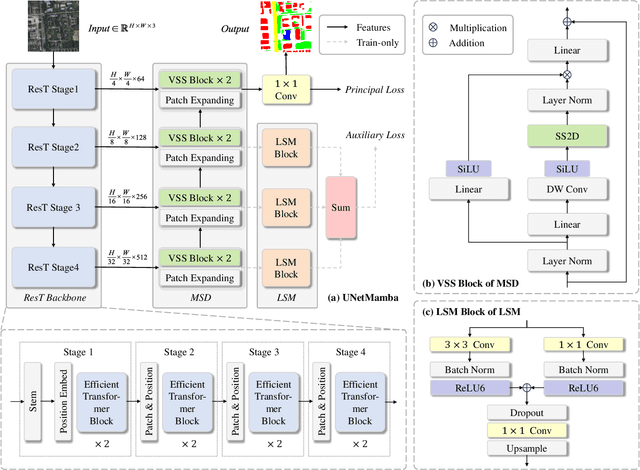
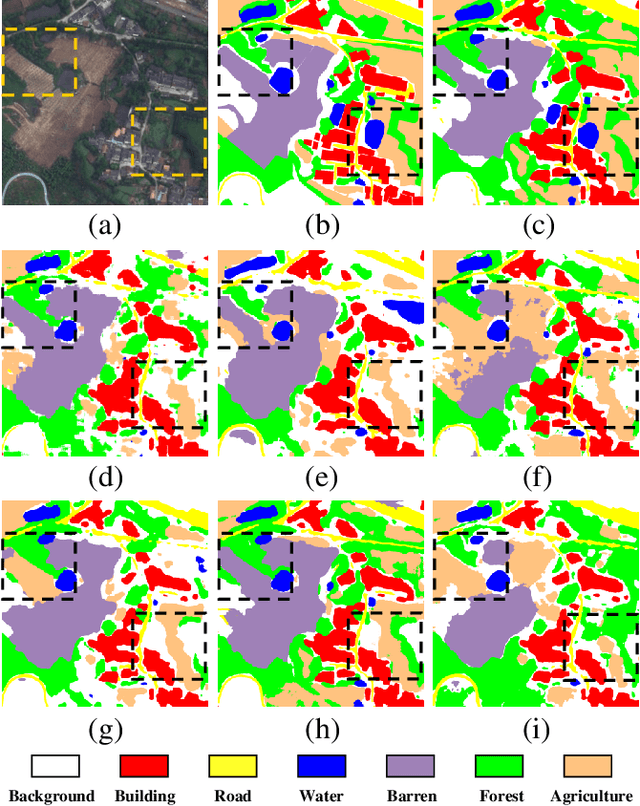


Semantic segmentation of high-resolution remote sensing images is vital in downstream applications such as land-cover mapping, urban planning and disaster assessment.Existing Transformer-based methods suffer from the constraint between accuracy and efficiency, while the recently proposed Mamba is renowned for being efficient. Therefore, to overcome the dilemma, we propose UNetMamba, a UNet-like semantic segmentation model based on Mamba. It incorporates a mamba segmentation decoder (MSD) that can efficiently decode the complex information within high-resolution images, and a local supervision module (LSM), which is train-only but can significantly enhance the perception of local contents. Extensive experiments demonstrate that UNetMamba outperforms the state-of-the-art methods with mIoU increased by 0.87% on LoveDA and 0.36% on ISPRS Vaihingen, while achieving high efficiency through the lightweight design, less memory footprint and reduced computational cost. The source code is available at https://github.com/EnzeZhu2001/UNetMamba.
UNetMamba: Efficient UNet-Like Mamba for Semantic Segmentation of High-Resolution Remote Sensing Images
Aug 21, 2024The semantic segmentation of high-resolution remote sensing images plays a crucial role in downstream applications such as urban planning and disaster assessment. However, existing Transformer-based methods suffer from the constraint between accuracy and efficiency. To overcome this dilemma, we propose UNetMamba, a novel Mamba-based semantic segmentation model. It incorporates a Mamba Segmentation Decoder (MSD) that can efficiently decode the complex information within high-resolution images, and a Local Supervision Module (LSM), which is train-only but can significantly enhance the perception of local contents. Extensive experiments demonstrate that UNet-Mamba outperforms the state-of-the-art methods with the mIoU increased by 0.87% on LoveDA and 0.36% on ISPRS Vaihingen, while achieving high efficiency through light weight, low memory footprint and low computational cost. The source code will soon be publicly available at https://github.com/EnzeZhu2001/UNetMamba.
Optimizing Speculative Decoding for Serving Large Language Models Using Goodput
Jun 20, 2024



Reducing the inference latency of large language models (LLMs) is crucial, and speculative decoding (SD) stands out as one of the most effective techniques. Rather than letting the LLM generate all tokens directly, speculative decoding employs effective proxies to predict potential outputs, which are then verified by the LLM without compromising the generation quality. Yet, deploying SD in real online LLM serving systems (with continuous batching) does not always yield improvement -- under higher request rates or low speculation accuracy, it paradoxically increases latency. Furthermore, there is no best speculation length work for all workloads under different system loads. Based on the observations, we develop a dynamic framework SmartSpec. SmartSpec dynamically determines the best speculation length for each request (from 0, i.e., no speculation, to many tokens) -- hence the associated speculative execution costs -- based on a new metric called goodput, which characterizes the current observed load of the entire system and the speculation accuracy. We show that SmartSpec consistently reduces average request latency by up to 3.2x compared to non-speculative decoding baselines across different sizes of target models, draft models, request rates, and datasets. Moreover, SmartSpec can be applied to different styles of speculative decoding, including traditional, model-based approaches as well as model-free methods like prompt lookup and tree-style decoding.
Towards Clinical AI Fairness: Filling Gaps in the Puzzle
May 28, 2024



The ethical integration of Artificial Intelligence (AI) in healthcare necessitates addressing fairness-a concept that is highly context-specific across medical fields. Extensive studies have been conducted to expand the technical components of AI fairness, while tremendous calls for AI fairness have been raised from healthcare. Despite this, a significant disconnect persists between technical advancements and their practical clinical applications, resulting in a lack of contextualized discussion of AI fairness in clinical settings. Through a detailed evidence gap analysis, our review systematically pinpoints several deficiencies concerning both healthcare data and the provided AI fairness solutions. We highlight the scarcity of research on AI fairness in many medical domains where AI technology is increasingly utilized. Additionally, our analysis highlights a substantial reliance on group fairness, aiming to ensure equality among demographic groups from a macro healthcare system perspective; in contrast, individual fairness, focusing on equity at a more granular level, is frequently overlooked. To bridge these gaps, our review advances actionable strategies for both the healthcare and AI research communities. Beyond applying existing AI fairness methods in healthcare, we further emphasize the importance of involving healthcare professionals to refine AI fairness concepts and methods to ensure contextually relevant and ethically sound AI applications in healthcare.
Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity
Apr 22, 2024



Large language models (LLMs) are increasingly integrated into many online services. However, a major challenge in deploying LLMs is their high cost, due primarily to the use of expensive GPU instances. To address this problem, we find that the significant heterogeneity of GPU types presents an opportunity to increase GPU cost efficiency and reduce deployment costs. The broad and growing market of GPUs creates a diverse option space with varying costs and hardware specifications. Within this space, we show that there is not a linear relationship between GPU cost and performance, and identify three key LLM service characteristics that significantly affect which GPU type is the most cost effective: model request size, request rate, and latency service-level objective (SLO). We then present M\'elange, a framework for navigating the diversity of GPUs and LLM service specifications to derive the most cost-efficient set of GPUs for a given LLM service. We frame the task of GPU selection as a cost-aware bin-packing problem, where GPUs are bins with a capacity and cost, and items are request slices defined by a request size and rate. Upon solution, M\'elange derives the minimal-cost GPU allocation that adheres to a configurable latency SLO. Our evaluations across both real-world and synthetic datasets demonstrate that M\'elange can reduce deployment costs by up to 77% as compared to utilizing only a single GPU type, highlighting the importance of making heterogeneity-aware GPU provisioning decisions for LLM serving. Our source code is publicly available at https://github.com/tyler-griggs/melange-release.
Computing in the Era of Large Generative Models: From Cloud-Native to AI-Native
Jan 17, 2024

In this paper, we investigate the intersection of large generative AI models and cloud-native computing architectures. Recent large models such as ChatGPT, while revolutionary in their capabilities, face challenges like escalating costs and demand for high-end GPUs. Drawing analogies between large-model-as-a-service (LMaaS) and cloud database-as-a-service (DBaaS), we describe an AI-native computing paradigm that harnesses the power of both cloud-native technologies (e.g., multi-tenancy and serverless computing) and advanced machine learning runtime (e.g., batched LoRA inference). These joint efforts aim to optimize costs-of-goods-sold (COGS) and improve resource accessibility. The journey of merging these two domains is just at the beginning and we hope to stimulate future research and development in this area.