 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQFT: Quantized Full-parameter Tuning of LLMs with Affordable Resources
Paper and Code
Oct 11, 2023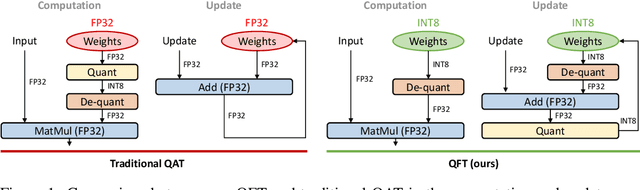



Large Language Models (LLMs) have showcased remarkable impacts across a wide spectrum of natural language processing tasks. Fine-tuning these pre-trained models on downstream datasets provides further significant performance gains, but this process has been challenging due to its extraordinary resource requirements. To this end, existing efforts focus on parameter-efficient fine-tuning, which, unfortunately, fail to capitalize on the powerful potential of full-parameter fine-tuning. In this work, we propose QFT, a novel Quantized Full-parameter Tuning framework for LLMs that enables memory-efficient fine-tuning without harming performance. Our framework incorporates two novel ideas: (i) we adopt the efficient Lion optimizer, which only keeps track of the momentum and has consistent update magnitudes for each parameter, an inherent advantage for robust quantization; and (ii) we quantize all model states and store them as integer values, and present a gradient flow and parameter update scheme for the quantized weights. As a result, QFT reduces the model state memory to 21% of the standard solution while achieving comparable performance, e.g., tuning a LLaMA-7B model requires only <30GB of memory, satisfied by a single A6000 GPU.