 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Equitable Survival Prediction: A Fairness-Aware Survival Modeling (FASM) Approach
Oct 23, 2025As machine learning models become increasingly integrated into healthcare, structural inequities and social biases embedded in clinical data can be perpetuated or even amplified by data-driven models. In survival analysis, censoring and time dynamics can further add complexity to fair model development. Additionally, algorithmic fairness approaches often overlook disparities in cross-group rankings, e.g., high-risk Black patients may be ranked below lower-risk White patients who do not experience the event of mortality. Such misranking can reinforce biological essentialism and undermine equitable care. We propose a Fairness-Aware Survival Modeling (FASM), designed to mitigate algorithmic bias regarding both intra-group and cross-group risk rankings over time. Using breast cancer prognosis as a representative case and applying FASM to SEER breast cancer data, we show that FASM substantially improves fairness while preserving discrimination performance comparable to fairness-unaware survival models. Time-stratified evaluations show that FASM maintains stable fairness over a 10-year horizon, with the greatest improvements observed during the mid-term of follow-up. Our approach enables the development of survival models that prioritize both accuracy and equity in clinical decision-making, advancing fairness as a core principle in clinical care.
seeBias: A Comprehensive Tool for Assessing and Visualizing AI Fairness
Apr 11, 2025Fairness in artificial intelligence (AI) prediction models is increasingly emphasized to support responsible adoption in high-stakes domains such as health care and criminal justice. Guidelines and implementation frameworks highlight the importance of both predictive accuracy and equitable outcomes. However, current fairness toolkits often evaluate classification performance disparities in isolation, with limited attention to other critical aspects such as calibration. To address these gaps, we present seeBias, an R package for comprehensive evaluation of model fairness and predictive performance. seeBias offers an integrated evaluation across classification, calibration, and other performance domains, providing a more complete view of model behavior. It includes customizable visualizations to support transparent reporting and responsible AI implementation. Using public datasets from criminal justice and healthcare, we demonstrate how seeBias supports fairness evaluations, and uncovers disparities that conventional fairness metrics may overlook. The R package is available on GitHub, and a Python version is under development.
Retrieval-Augmented Generation for Generative Artificial Intelligence in Medicine
Jun 18, 2024Generative artificial intelligence (AI) has brought revolutionary innovations in various fields, including medicine. However, it also exhibits limitations. In response, retrieval-augmented generation (RAG) provides a potential solution, enabling models to generate more accurate contents by leveraging the retrieval of external knowledge. With the rapid advancement of generative AI, RAG can pave the way for connecting this transformative technology with medical applications and is expected to bring innovations in equity, reliability, and personalization to health care.
Towards Clinical AI Fairness: Filling Gaps in the Puzzle
May 28, 2024



The ethical integration of Artificial Intelligence (AI) in healthcare necessitates addressing fairness-a concept that is highly context-specific across medical fields. Extensive studies have been conducted to expand the technical components of AI fairness, while tremendous calls for AI fairness have been raised from healthcare. Despite this, a significant disconnect persists between technical advancements and their practical clinical applications, resulting in a lack of contextualized discussion of AI fairness in clinical settings. Through a detailed evidence gap analysis, our review systematically pinpoints several deficiencies concerning both healthcare data and the provided AI fairness solutions. We highlight the scarcity of research on AI fairness in many medical domains where AI technology is increasingly utilized. Additionally, our analysis highlights a substantial reliance on group fairness, aiming to ensure equality among demographic groups from a macro healthcare system perspective; in contrast, individual fairness, focusing on equity at a more granular level, is frequently overlooked. To bridge these gaps, our review advances actionable strategies for both the healthcare and AI research communities. Beyond applying existing AI fairness methods in healthcare, we further emphasize the importance of involving healthcare professionals to refine AI fairness concepts and methods to ensure contextually relevant and ethically sound AI applications in healthcare.
Fairness-Aware Interpretable Modeling (FAIM) for Trustworthy Machine Learning in Healthcare
Mar 08, 2024
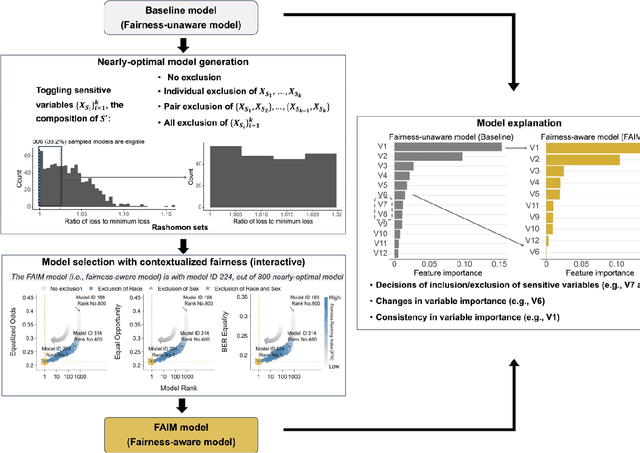


The escalating integration of machine learning in high-stakes fields such as healthcare raises substantial concerns about model fairness. We propose an interpretable framework - Fairness-Aware Interpretable Modeling (FAIM), to improve model fairness without compromising performance, featuring an interactive interface to identify a "fairer" model from a set of high-performing models and promoting the integration of data-driven evidence and clinical expertise to enhance contextualized fairness. We demonstrated FAIM's value in reducing sex and race biases by predicting hospital admission with two real-world databases, MIMIC-IV-ED and SGH-ED. We show that for both datasets, FAIM models not only exhibited satisfactory discriminatory performance but also significantly mitigated biases as measured by well-established fairness metrics, outperforming commonly used bias-mitigation methods. Our approach demonstrates the feasibility of improving fairness without sacrificing performance and provides an a modeling mode that invites domain experts to engage, fostering a multidisciplinary effort toward tailored AI fairness.
Developing Federated Time-to-Event Scores Using Heterogeneous Real-World Survival Data
Mar 08, 2024

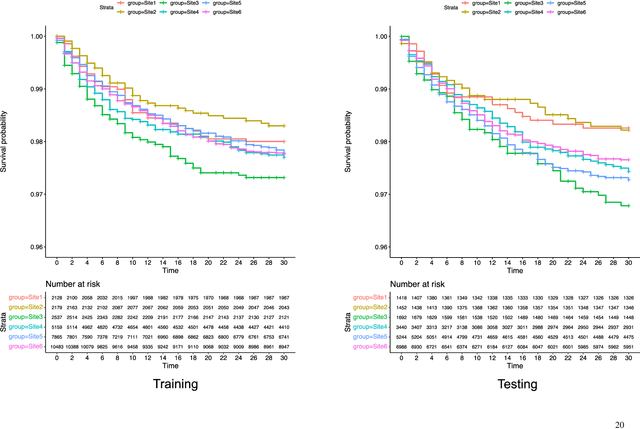
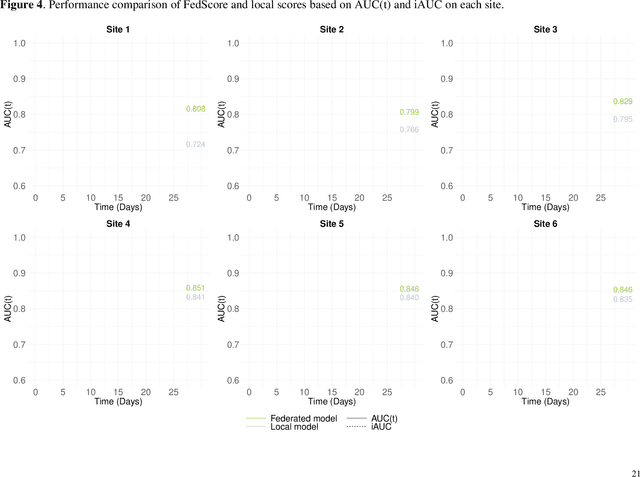
Survival analysis serves as a fundamental component in numerous healthcare applications, where the determination of the time to specific events (such as the onset of a certain disease or death) for patients is crucial for clinical decision-making. Scoring systems are widely used for swift and efficient risk prediction. However, existing methods for constructing survival scores presume that data originates from a single source, posing privacy challenges in collaborations with multiple data owners. We propose a novel framework for building federated scoring systems for multi-site survival outcomes, ensuring both privacy and communication efficiency. We applied our approach to sites with heterogeneous survival data originating from emergency departments in Singapore and the United States. Additionally, we independently developed local scores at each site. In testing datasets from each participant site, our proposed federated scoring system consistently outperformed all local models, evidenced by higher integrated area under the receiver operating characteristic curve (iAUC) values, with a maximum improvement of 11.6%. Additionally, the federated score's time-dependent AUC(t) values showed advantages over local scores, exhibiting narrower confidence intervals (CIs) across most time points. The model developed through our proposed method exhibits effective performance on each local site, signifying noteworthy implications for healthcare research. Sites participating in our proposed federated scoring model training gained benefits by acquiring survival models with enhanced prediction accuracy and efficiency. This study demonstrates the effectiveness of our privacy-preserving federated survival score generation framework and its applicability to real-world heterogeneous survival data.
Survival modeling using deep learning, machine learning and statistical methods: A comparative analysis for predicting mortality after hospital admission
Mar 04, 2024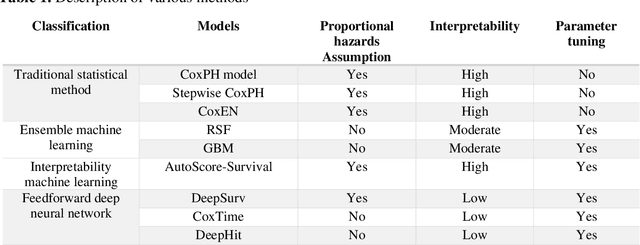
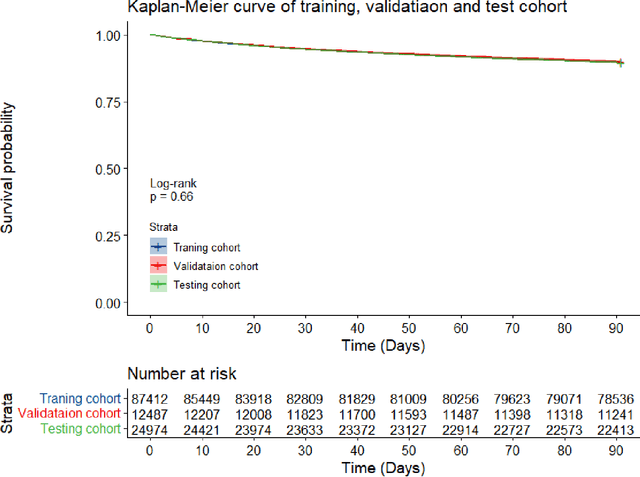
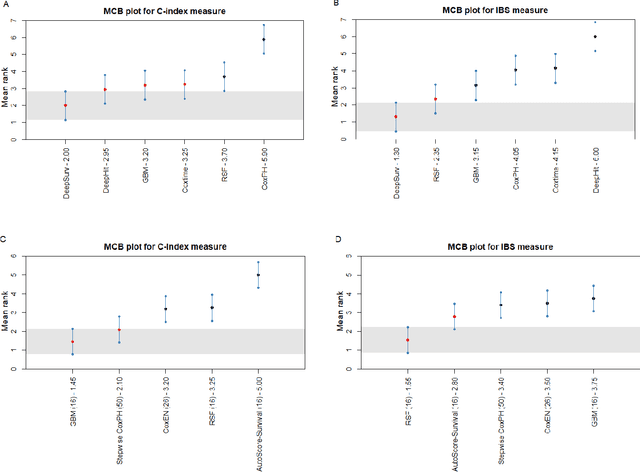
Survival analysis is essential for studying time-to-event outcomes and providing a dynamic understanding of the probability of an event occurring over time. Various survival analysis techniques, from traditional statistical models to state-of-the-art machine learning algorithms, support healthcare intervention and policy decisions. However, there remains ongoing discussion about their comparative performance. We conducted a comparative study of several survival analysis methods, including Cox proportional hazards (CoxPH), stepwise CoxPH, elastic net penalized Cox model, Random Survival Forests (RSF), Gradient Boosting machine (GBM) learning, AutoScore-Survival, DeepSurv, time-dependent Cox model based on neural network (CoxTime), and DeepHit survival neural network. We applied the concordance index (C-index) for model goodness-of-fit, and integral Brier scores (IBS) for calibration, and considered the model interpretability. As a case study, we performed a retrospective analysis of patients admitted through the emergency department of a tertiary hospital from 2017 to 2019, predicting 90-day all-cause mortality based on patient demographics, clinicopathological features, and historical data. The results of the C-index indicate that deep learning achieved comparable performance, with DeepSurv producing the best discrimination (DeepSurv: 0.893; CoxTime: 0.892; DeepHit: 0.891). The calibration of DeepSurv (IBS: 0.041) performed the best, followed by RSF (IBS: 0.042) and GBM (IBS: 0.0421), all using the full variables. Moreover, AutoScore-Survival, using a minimal variable subset, is easy to interpret, and can achieve good discrimination and calibration (C-index: 0.867; IBS: 0.044). While all models were satisfactory, DeepSurv exhibited the best discrimination and calibration. In addition, AutoScore-Survival offers a more parsimonious model and excellent interpretability.
Federated Learning for Clinical Structured Data: A Benchmark Comparison of Engineering and Statistical Approaches
Nov 06, 2023Federated learning (FL) has shown promising potential in safeguarding data privacy in healthcare collaborations. While the term "FL" was originally coined by the engineering community, the statistical field has also explored similar privacy-preserving algorithms. Statistical FL algorithms, however, remain considerably less recognized than their engineering counterparts. Our goal was to bridge the gap by presenting the first comprehensive comparison of FL frameworks from both engineering and statistical domains. We evaluated five FL frameworks using both simulated and real-world data. The results indicate that statistical FL algorithms yield less biased point estimates for model coefficients and offer convenient confidence interval estimations. In contrast, engineering-based methods tend to generate more accurate predictions, sometimes surpassing central pooled and statistical FL models. This study underscores the relative strengths and weaknesses of both types of methods, emphasizing the need for increased awareness and their integration in future FL applications.
Generative Artificial Intelligence in Healthcare: Ethical Considerations and Assessment Checklist
Nov 02, 2023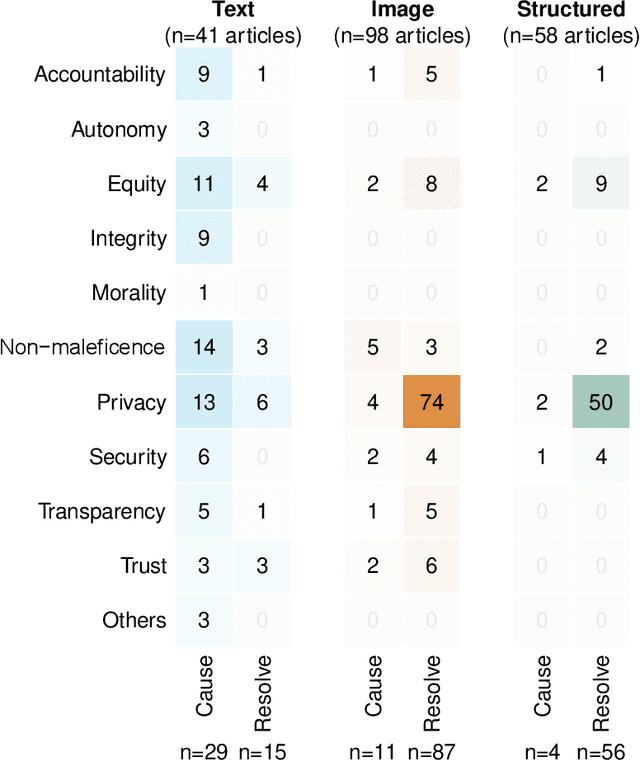
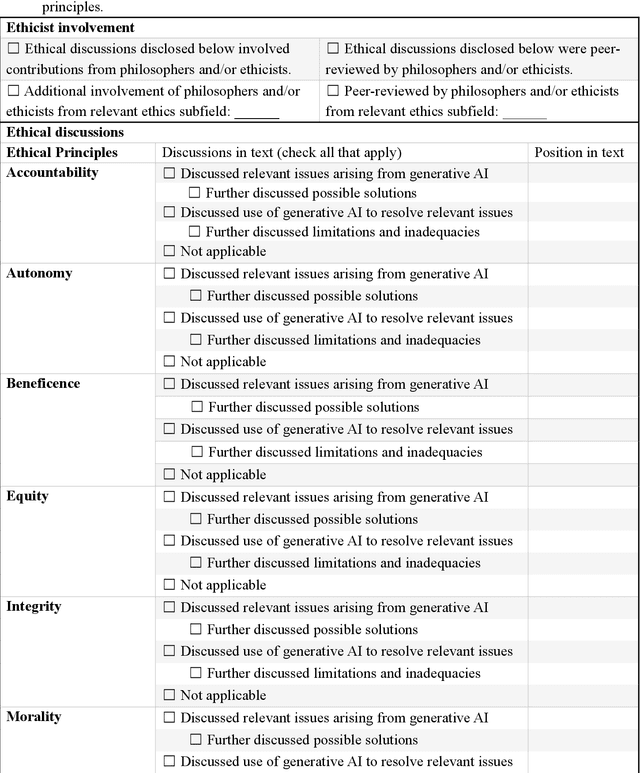
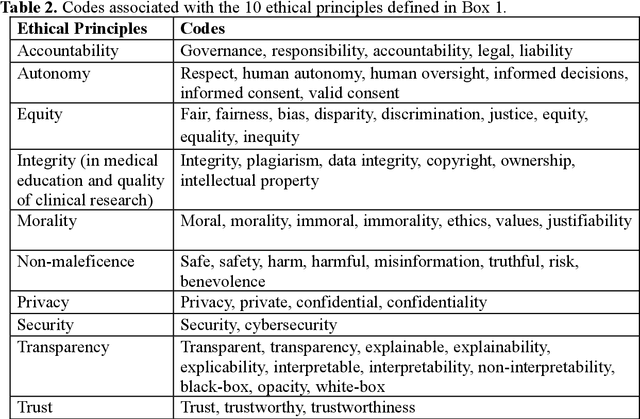
The widespread use of ChatGPT and other emerging technology powered by generative artificial intelligence (AI) has drawn much attention to potential ethical issues, especially in high-stakes applications such as healthcare. However, less clear is how to resolve such issues beyond following guidelines and regulations that are still under discussion and development. On the other hand, other types of generative AI have been used to synthesize images and other types of data for research and practical purposes, which have resolved some ethical issues and exposed other ethical issues, but such technology is less often the focus of ongoing ethical discussions. Here we highlight gaps in current ethical discussions of generative AI via a systematic scoping review of relevant existing research in healthcare, and reduce the gaps by proposing an ethics checklist for comprehensive assessment and transparent documentation of ethical discussions in generative AI development. While the checklist can be readily integrated into the current peer review and publication system to enhance generative AI research, it may also be used in broader settings to disclose ethics-related considerations in generative AI-powered products (or real-life applications of such products) to help users establish reasonable trust in their capabilities.